
如何处理设计负责人多人编辑冲突?结合设计交付场景分析
文章围绕设计交付场景中的多人编辑冲突,给出明确判断:问题核心不在沟通情绪,而在协作机制缺失。处理这类冲突,设计负责人应先识别冲突类型,再从编辑边界、版本规则、评审合并、例外管理四个方面建立机制。文中分析了设计交付为何天然更容易出现冲突,包括页面和组件耦合高、最终版本口径不一、负责人角色汇聚压力以及需求变化与交付节奏不同步。随后结合需求探索期、详细设计期、临近交付期和研发联调期,说明不同阶段的处理重点,并指出落地时常见的三个难点:规则难执行、多方意见打散入口、负责人习惯亲自兜底。最终结论是,设计负责人要把多人编辑冲突从临时协调转成可预期、可回退、可裁决的设计交付机制,优先落地 owner 机制、版本分层和冻结点,才能真正减少覆盖修改和返工。
 William Gu
William Gu- 2026-05-29

如何提升设计负责人设计交付效率?规范版本和评论的实操经验
提升设计负责人设计交付效率,核心不在催设计师出稿,而在统一版本管理和评论机制。文章指出,设计低效通常源于版本混乱、评论失焦、冻结点缺失和交付边界不清,而不是单纯设计能力不足。实操上,设计负责人应先建立统一的版本命名和状态规则,明确探索中、待评审、已确认、已交付等阶段,并设置方案冻结和交付冻结节点,减少晚到意见造成的返工。评论管理则要从“随手提意见”升级为“按目标、体验、实现三类分类评论”,并指定归口人负责收敛冲突意见、输出明确结论,把模糊感受转成可执行修改项。文章还拆解了评审前、评审中、评审后和交付时的推进顺序,强调每轮只解决当前最重要的问题,并通过评论清单化、责任化、截止化提高会后执行效率。最后提醒,规范失效常常不是因为没有规则,而是规则太重、只约束设计师、不约束提意见的人,或者负责人自己频繁跳过流程。真正可持续的提升路径,是先用轻量但刚性的版本和评论规范,把设计交付过程稳定下来,再通过复盘持续优化返工点和决策节奏。
- Elara
- 2026-05-29

如何提升设计负责人设计交付效率?提前识别阻塞的实操经验
提升设计负责人设计交付效率,核心不是单纯要求团队加快出稿,而是提前识别阻塞、减少返工和统一协作标准。文章指出,设计项目变慢通常卡在需求不清、决策不明、资源切换频繁和跨团队协作断层,而不是设计执行本身。要提前识别阻塞,重点关注五类信号:需求目标说不清、评审参与多但无人拍板、资源排期满却优先级混乱、方案依赖外部输入却没有时间约束、过早讨论视觉细节而结构边界未定。落地上,设计负责人应建立设计可启动性检查、设置关键观察点、将阻塞从普通进度中单独定义,并设立明确的升级规则。真正有效的执行路径包括统一交付标准、把高频阻塞做成前置检查项、用短周期同步替代大评审、通过复盘沉淀团队阻塞地图。最后还提醒三个常见误区:把多开会当成提前识别、把负责人亲自盯项目当成机制建设、把交付提速误解为压缩必要设计过程。
- Rhett Bai
- 2026-05-29

如何处理设计负责人客户需求传递失真?结合设计交付场景分析
文章指出,设计负责人客户需求传递失真并非单纯沟通能力不足,而是需求在多次转述中被裁剪、误解和提前方案化。解决关键不在让负责人更会“传话”,而在建立一套围绕设计交付场景运转的机制:拆分客户原始诉求、业务目标、设计判断和交付约束;通过复述确认、分层分发、阶段评审和变更记录,把“理解”变成可验证信息。文中结合品牌视觉、页面设计、多角色协同和高频快单四类场景,分析了失真高发节点和落地方法,并强调常见误区包括把负责人当纯接口人、把客户意见全部当需求、只在出问题后复盘等。最终结论是,设计负责人真正要做的是把客户语言翻译成交付语言,用清晰的确认机制减少返工、统一团队理解并稳住设计交付质量。
- Joshua Lee
- 2026-05-29

如何处理设计负责人数据口径不统一?结合设计交付场景分析
文章围绕设计负责人数据口径不统一的问题,结合设计交付场景给出明确判断:问题本质不在报表,而在统计对象、统计时点、计算规则和使用场景没有统一定义。文中先分析了任务量、完成率、交付时效、返工率四类最容易出现分歧的数据口径,再提出“定义边界、统一源头、固定对账”三步处理方法,并进一步拆解到需求进入、设计执行、复盘三个交付阶段中。最后强调常见误区不是数字没统一,而是试图强行做成一套结果、依赖临场解释、过度细化字段或把系统性问题归为个人失误。核心结论是:要处理设计负责人数据口径不统一,关键不是反复对数,而是让数据定义嵌入设计交付流程,形成同源数据、分层口径和稳定对账机制。
- William Gu
- 2026-05-29

如何提升设计负责人设计交付效率?建立统一口径的实操经验
提升设计负责人设计交付效率,核心不是单纯压缩出图时间,而是先建立统一口径,解决需求理解、设计判断、交付表达和验收标准不一致的问题。文章指出,设计交付低效常见根因在于需求入口混乱、评审标准分散、交付件不完整和复用机制薄弱,而不是设计师画得慢。实操上,应先设定需求进入设计的准入条件,把评审从“看图会”改为“决策会”,建立最小可用的交付清单,并通过复盘不断沉淀规则。推进时还要避免只抓速度、不管返工,避免一上来做厚重规范,也不能只在设计内部统一而忽略产品和研发协同。落地路径上,建议按止损、提稳、放大、优化组织分工四个阶段推进,最终让设计交付从依赖个人经验转向依赖团队共识和规则,从而持续提升效率和稳定性。
- Joshua Lee
- 2026-05-29

如何处理设计负责人工作汇报低效?结合设计交付场景分析
文章认为,设计负责人工作汇报低效的根源通常不在表达能力,而在于汇报目标错位、设计交付缺少阶段化、缺乏证据链,以及没有把待决策事项说清。放在设计交付场景中,低效汇报本质上是把“设计过程说明”当成了“业务决策支持”。文章先用表格拆解低效汇报的常见表现与深层原因,再提出改进方向:将汇报从“设计内容汇报”重构为“交付管理汇报”,围绕目标、进展、风险、决策四层结构展开。随后结合需求进入、方案探索、方案收敛、开发对接等设计交付阶段,说明每个阶段真正该汇报什么,强调不要沉迷设计细节,而要突出边界、取舍、稳定性和落地风险。最后聚焦常见误区,指出设计负责人经常讲错对象、讲错层次、用设计语言汇报业务问题,或把汇报变成被动解释会。全文结论是,处理设计负责人工作汇报低效,关键不是优化展示形式,而是让汇报真正服务交付推进和决策闭环。
- Joshua Lee
- 2026-05-29
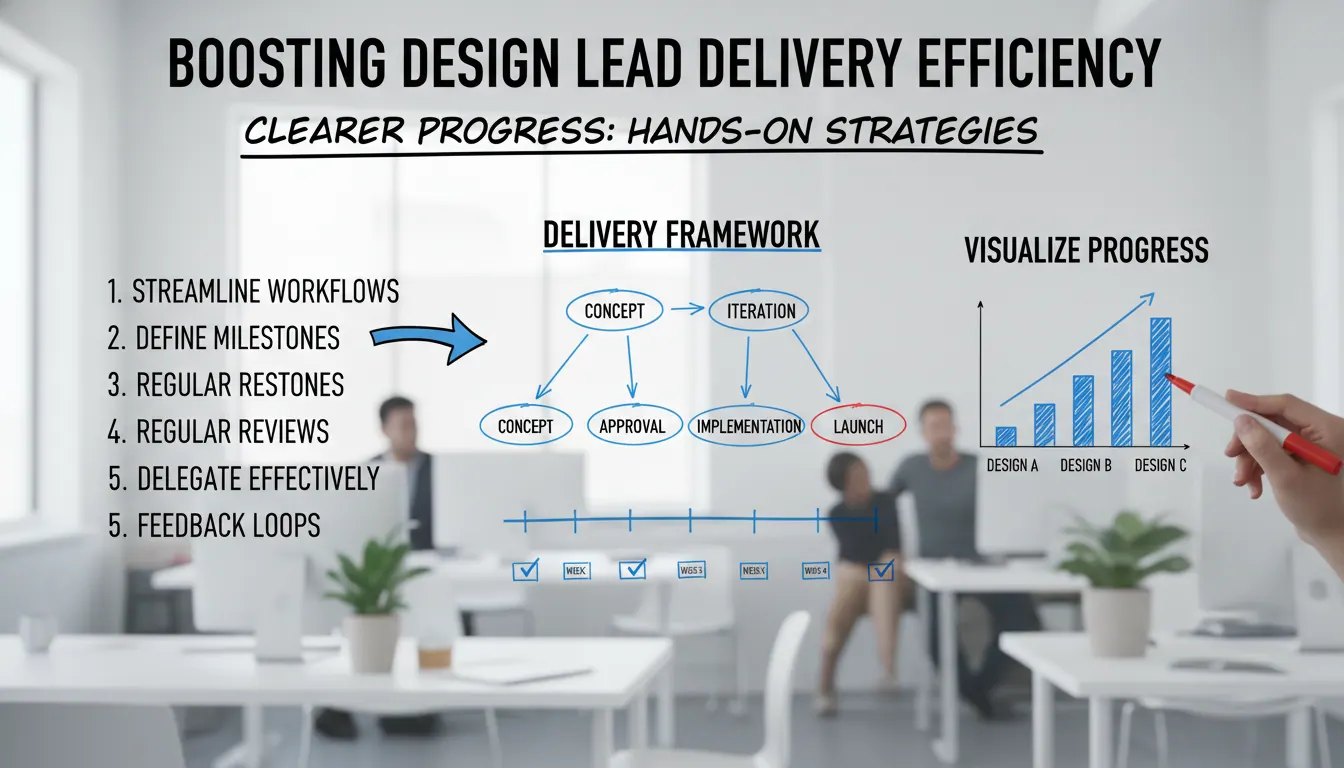
如何提升设计负责人设计交付效率?让进展更清楚的实操经验
提升设计负责人设计交付效率,核心不是让设计师单纯加快出图,而是把需求入口、任务阶段、完成标准、推进节奏和返工原因管理起来。文章从实操角度拆解了五个关键动作:先诊断效率低到底卡在哪,统一设计需求入口避免被随时打断,把设计任务拆成清晰阶段让进展可判断,按任务类型定义交付完成标准减少“做完了但不能交”的假性完成,再通过固定同步节奏和变更管理让风险提前暴露。最后强调,设计交付效率的本质是少返工、少无效沟通、少临时救火,设计负责人真正该优化的是管理机制,而不是单纯催速度。
- William Gu
- 2026-05-29

如何提升设计负责人设计交付效率?减少信息损耗的实操经验
提升设计负责人设计交付效率,核心不是单纯加快出图,而是减少需求理解、评审决策、设计交付和上线验收中的信息损耗。文章指出,效率低往往源于目标不清、边界模糊、拍板机制缺失和交付信息不完整,而不是设计师画得慢。要先判断问题出在入口、评审、交付还是验收,再重点管理四类最容易丢失的信息:目标信息、约束信息、决策信息和交付信息。实操上,可围绕四个节点重建机制:需求进入前设准入标准,方案推进时把评审从收集意见改为完成判断,设计交付时按研发可实现和可验收的结构输出,上线前把验收标准前置。文章还提醒三个常见误区:以为多同步就能减少损耗,以为规范齐全就能解决返工,以为负责人亲自兜底就是高效率。最后给出三步落地路径:写清每个需求的目标、边界和拍板人;评审后只保留已确认事项和待决事项;交付前做一次研发视角自检。真正稳定的提效,不靠个人硬扛,而靠让信息在协作链路中少变形、少丢失。
- William Gu
- 2026-05-29
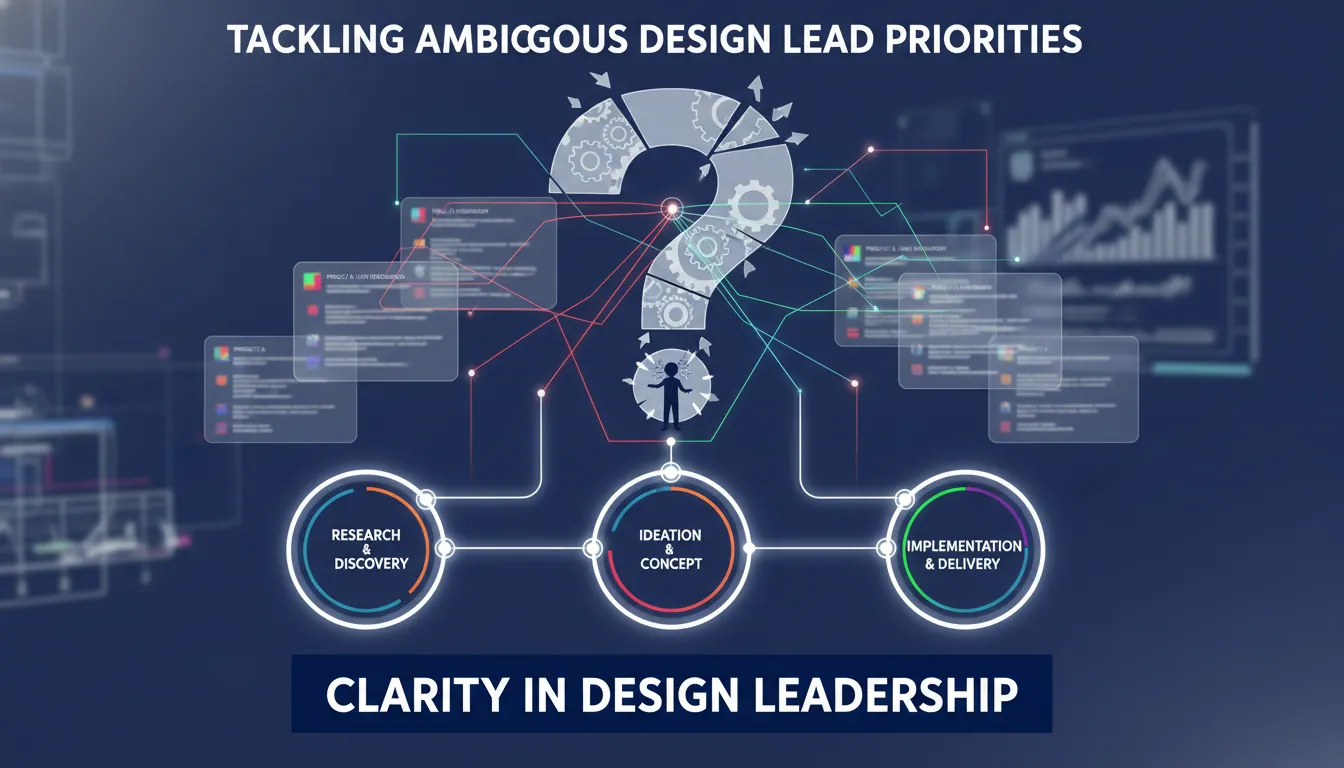
如何处理设计负责人任务优先级不明?结合设计交付场景分析
文章指出,设计负责人任务优先级不明,核心不是事情太多,而是目标没有被转换为清晰的设计交付顺序。处理这类问题,不能只靠个人时间管理,而要回到设计交付场景,从业务影响、交付时点、依赖关系、返工成本四个维度重排任务。文中先拆解了优先级失真的根源,包括需求入口混乱、项目节奏失真、设计被频繁插队以及返工成本被忽视;再分析了临时需求、小改动、无完成标准任务、沉没成本和关系驱动排序这五类最容易伪装成高优先级的任务。随后给出一套可落地机制:统一需求入口、统一排序标准、统一拍板责任,并通过定期复盘不断校正规则。在多项目并行、上线冲刺、需求频繁变化和设计资源紧张等典型场景中,文章进一步说明了应如何取舍:先保主线项目,先解阻塞项,先冻结范围,先做判断而不是先做图。最终结论是,设计负责人真正要解决的不是任务数量,而是任务顺序失真;只要建立公开透明的优先级机制,设计交付就能从被动救火转向主动推进。
- Rhett Bai
- 2026-05-29

如何处理设计负责人沟通没有结论?结合设计交付场景分析
文章认为,设计负责人沟通没有结论,通常不是单纯表达问题,而是目标不一致、决策权不明确、讨论对象过大、交付约束未被显性化共同造成的。放在设计交付场景中,正确处理方式不是继续无边界开会,而是围绕交付结果建立结构化决策机制。全文先拆解了沟通无结论的三层根源:目标层错位导致大家讨论的不是同一个问题,决策层错位导致人人能提意见却没人拍板,执行层错位导致所谓结论无法转成可交付动作。随后提出一套更有效的推进顺序:先定问题,再定判断标准,再定方案,最后定责任,把讨论从审美分歧拉回业务目标、用户任务、技术可行性和上线时间。文章还结合实际设计交付场景,说明设计负责人在现场应如何把无效争论收敛为结果,包括切分模糊反馈、把方案代价说透、在会议结束前用一句话锁定结论。同时重点分析了四个常见误区,例如把充分讨论当成高质量决策、用更多方案替代问题定义、把自己变成传话人、默认所有问题都要在会上解决。最后给出项目已经陷入反复拉扯时的止损方法,包括回到交付边界、用统一结论文档替代碎片化聊天、对无法收敛的冲突及时升级、并在后续项目中补上评审与变更机制。整篇文章的核心判断是:设计负责人沟通没有结论,本质上是缺少让结论产生的流程和责任机制,只有把沟通组织成可判断、可取舍、可追踪的决策过程,设计交付才能真正顺畅推进。
- Rhett Bai
- 2026-05-29

如何提升设计负责人设计交付效率?减少无效忙碌的实操经验
文章指出,提升设计负责人设计交付效率的关键不是让团队更忙,而是减少返工、降低任务切换、压缩等待时间、统一决策标准。首先要判断效率低到底是入口混乱、返工过多,还是负责人被碎片事务拖住。接着通过统一设计需求入口、建立优先级分层、给排期预留缓冲,先把任务管理住。真正影响设计交付效率的核心是返工,因此要把需求澄清前置、让评审围绕决策展开,并控制评审层级,避免同一方案被重复否定。同时,设计负责人要从低杠杆琐事中抽离,明确哪些事必须自己做,哪些要靠机制和授权解决。最后文章强调,落地过程中最常见的误区包括把响应快当成效率高、设计标准过度依赖负责人个人、所有项目都按同样精细度投入、只盯设计阶段不管研发落地。整体方法的核心是先控入口、再稳节奏,先减返工、再提速度,用机制替代救火,让团队把时间花在真正有价值的设计决策上。
- William Gu
- 2026-05-29
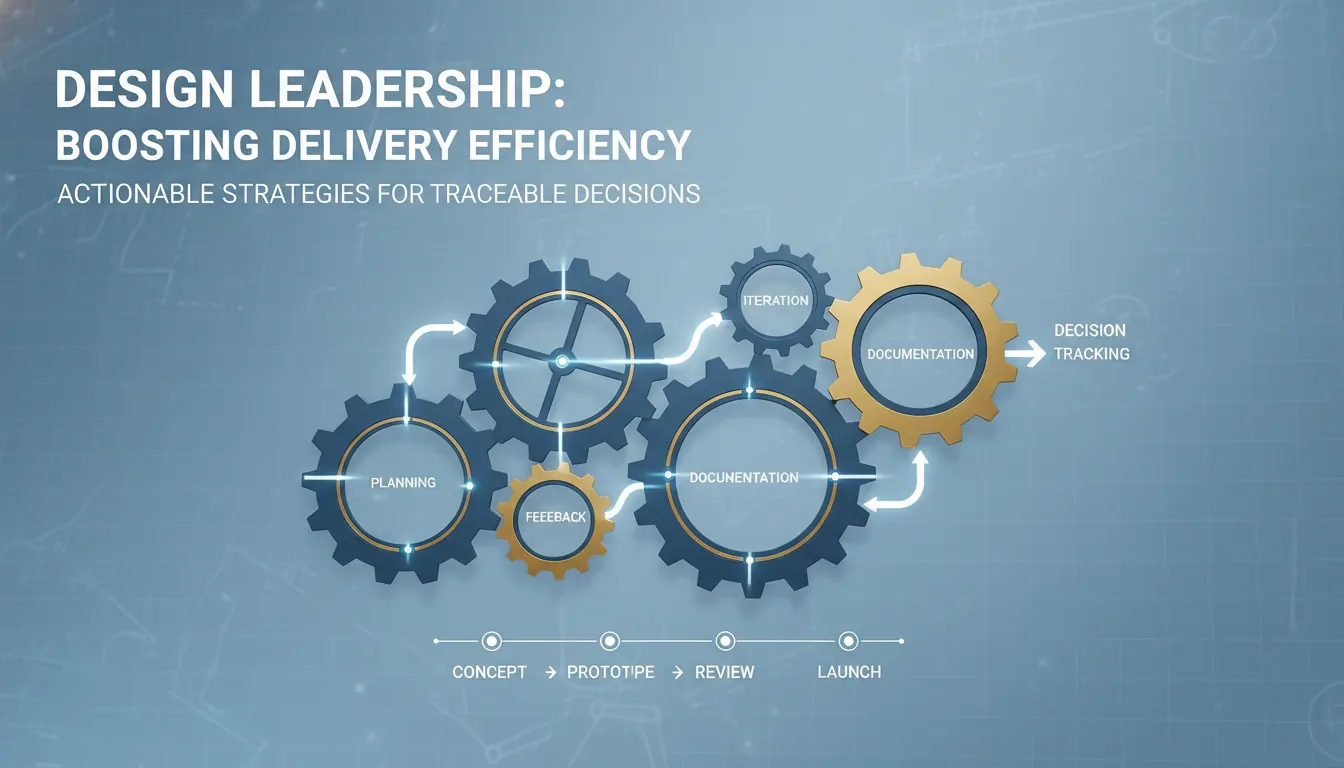
如何提升设计负责人设计交付效率?让决定可追踪的实操经验
提升设计负责人设计交付效率,关键不在催设计师更快出稿,而在于让需求判断、设计决策、评审结论和交付标准都可追踪。文章指出,效率低常见根源包括需求入口混乱、优先级频繁变化、评审不收口、交付标准模糊和设计资产无法复用。真正有效的路径是先诊断瓶颈所在,再建立轻量但统一的决策留痕机制,确保关键决定能回答为什么这样做、谁决定、依据是什么、后续去哪里回查。随后把流程改成节点驱动,重点抓住需求过滤、方案对齐、评审拍板和交付验收四个节点,减少靠负责人个人盯项目的低效方式。衡量设计交付效率时,不应只看出稿速度和忙碌程度,更应看返工率、等待时间、决策耗时和一次通过率。落地时最常见的难点包括团队习惯口头定结论、负责人自己频繁插单、跨部门对完成定义不一致以及记录无法复用。文章最后强调,设计交付效率的本质提升来自可追踪的决定,而不是更拼的执行。
- Elara
- 2026-05-29

如何处理设计负责人新人上手慢?结合设计交付场景分析
文章认为,设计负责人新人上手慢,核心通常不是个人能力差,而是角色切换、交付链路不熟和职责边界不清共同造成的。解决方法不是单纯催速度,而是先判断他慢在业务理解、方案决策还是项目推进,再围绕设计交付场景建立负责人职责、项目节奏图、设计决策标准和短周期反馈机制。文中进一步拆解了理解慢、决策慢、推进慢三种典型表现及对应纠偏动作,并指出常见误区包括把慢等同于能力弱、放任其自行摸索、只看设计稿不看交付动作、试图一次性补齐所有短板。最终结论是,想让新人设计负责人真正提速,关键在于帮助他尽快建立完整的设计交付闭环意识,而不是继续按资深设计师的方式工作。
- Elara
- 2026-05-29

如何提升设计负责人设计交付效率?建立协作指引的实操经验
提升设计负责人设计交付效率,关键不在催进度或强化个人管控,而在建立能减少返工、统一协作预期的协作指引。文章指出,设计交付慢通常不是设计执行慢,而是需求输入混乱、反馈角色不清、交付标准不一致、变更无边界、上线验收缺失造成的协作成本过高。真正有效的协作指引应聚焦高频问题,覆盖需求准入、反馈分层、交付标准、变更规则和上线验收,并按项目流转链路编写,落到可执行动作,而不是空泛原则。落地时要把指引嵌入项目启动和日常推进,优先解决当前最痛的一个环节,同时为紧急需求等例外场景预留规则,并通过复盘持续迭代。文章还提醒,常见误区包括规则写得过多、把设计规范与协作指引混在一起、只约束设计师不约束协作方,以及过度依赖负责人个人权威。最终结论是,设计负责人要把交付效率问题从“人盯人”转为“机制驱动”,让团队在负责人不持续介入的情况下,也能稳定完成高质量设计交付。
- Elara
- 2026-05-29

如何提升设计负责人设计交付效率?分层处理信息的实操经验
文章指出,设计负责人提升设计交付效率的关键不在于催促产出,而在于通过分层处理信息,把目标、范围、方案和执行四类问题分别在合适阶段解决。低效的根源通常不是设计执行慢,而是需求信息混乱、讨论顺序错误、责任边界模糊和决策颗粒度失衡。文中提出四层信息框架:战略层明确为什么做,业务层明确做什么和优先级,方案层解决路径和结构,执行层保障交付和协同。围绕这套框架,文章给出四个实操动作:接需求先定目标,不直接接任务;设计开始前切清范围,防止项目膨胀;评审时只讨论当前层级的问题,避免跨层返工;进入执行后重点清理阻塞信息,而不是盯每一张设计稿。随后分析了落地时常见误区,包括把分层做成加流程、负责人包揽所有判断、只在项目出问题后才回头整理信息。最后建议将这套方法嵌入团队日常协作:统一需求入口表达顺序,建立阶段性结论,对并行项目按信息成熟度分流,并在复杂协作场景下借助合适系统承接节点信息。核心结论是,设计交付效率的提升,本质上取决于设计负责人是否具备信息过滤、层级判断和决策组织能力。
- Elara
- 2026-05-29

如何处理设计负责人文件权限混乱?结合设计交付场景分析
文章指出,设计负责人文件权限混乱的根源通常不在工具,而在设计交付链路缺少分层和边界,具体表现为文件未分类、角色未分权、阶段未分段、变更未留痕。处理方法应围绕设计交付场景展开,重点分析了评审、开发交付、对外协作和多项目并行四类最容易失控的场景,并提出按“文件、角色、阶段、动作”四层重建权限模型。落地上,建议先盘点高风险在途项目,再为每个项目建立唯一交付入口,统一最小命名和版本规则,并把临时授权变成可回收动作。文章同时提醒避免四类常见误区:以全开放换效率、只整理目录不清角色、历史项目长期开放、把权限维护完全压在负责人个人身上。最终结论是,设计负责人要解决文件权限混乱,核心不是补权限,而是围绕设计交付重建秩序。
- Elara
- 2026-05-29

如何处理设计负责人消息通知打扰?结合设计交付场景分析
文章认为,设计负责人消息通知打扰的根因并不只是消息多,而是设计交付流程中沟通入口失控、优先级混乱、责任过度集中和状态不可见。真正有效的处理方式不是简单静音或要求少发消息,而是把通知按是否影响方向、责任和交付时点进行分级,保留必要中断,削减本可通过流程解决的低价值确认。文中结合需求变更、设计评审、开发还原、上线验收等设计交付场景,拆解了设计负责人为何容易成为默认确认入口,并指出三类常见误区:把知道所有细节当成负责、把秒回当成高效、把流程问题当成个人习惯问题。落地上,建议先做一周消息盘点,再公开响应规则,优先改造需求变更入口和开发还原确认机制,同时保留有门槛的升级通道,并用固定协同节奏替代随机打断。核心结论是,减少设计负责人通知打扰,关键不在少回消息,而在重建设计交付秩序,让负责人从“随时答疑的人”回到“关键决策和交付把关的人”。
- Elara
- 2026-05-29
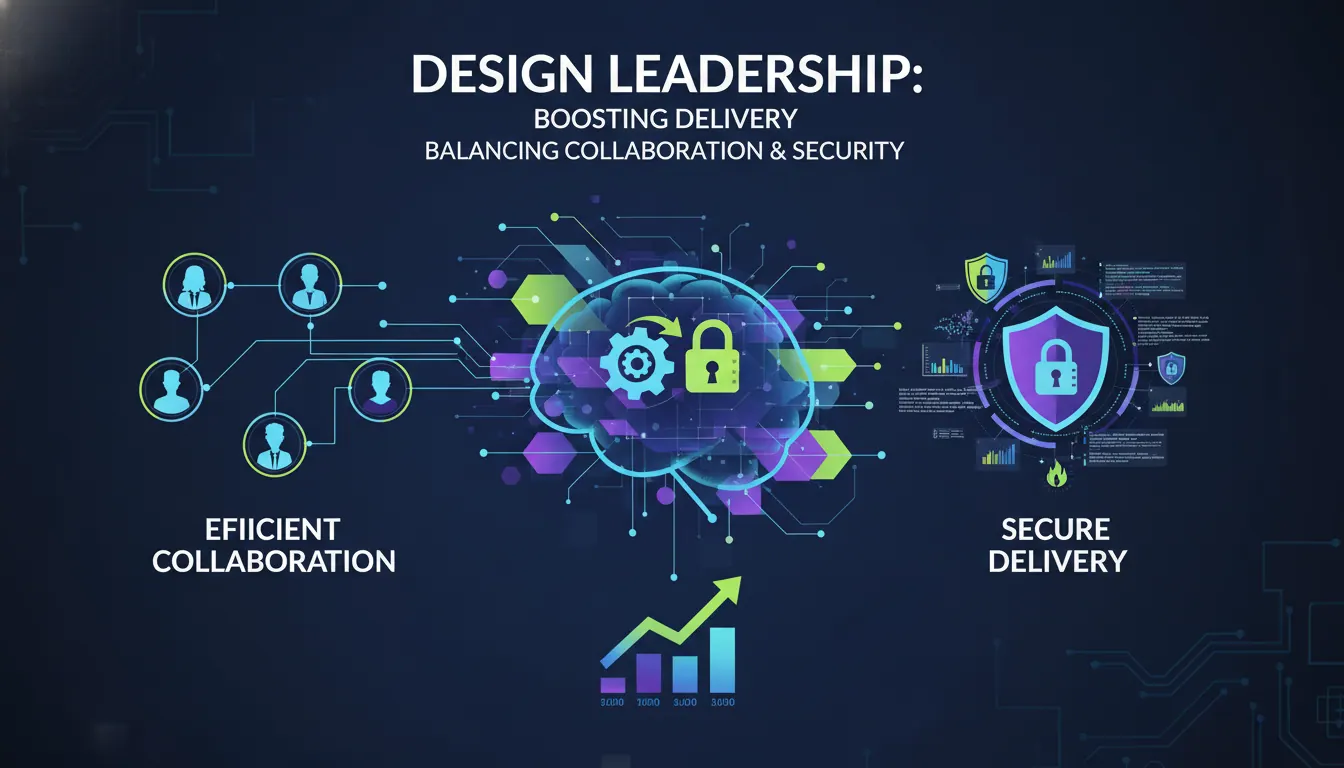
如何提升设计负责人设计交付效率?兼顾协作与安全的实操经验
文章指出,设计负责人要提升设计交付效率,重点不在单纯催快设计产出,而在于拆清交付链路、降低协作损耗、把安全前置。真正拖慢效率的通常是需求入口混乱、评审缺少拍板、资产版本失控、交付说明不完整以及权限边界模糊。文中先用表格拆解了常见低效卡点与根因,然后提炼出四个关键杠杆:统一需求治理、分层评审收口、设计资产标准化、按角色做权限分层。接着给出一条可执行的五阶段交付流程,包括需求受理、方案对齐、设计生产、交付验收和上线回看,强调每个阶段都要有明确产出物与责任边界。文章还总结了三类常见误区:把效率等同于出稿速度、用口头同步代替正式协作、出问题后才补安全。最后给出四个落地动作,建议设计负责人先统一需求入口、拆分评审关口、从最小标准化开始建设资产规则,并优先收紧外部共享和长期开放权限。核心结论是,设计交付效率的提升,本质是让协作可控、版本可追、责任可落、安全可管,从而实现既快又稳的交付。
- William Gu
- 2026-05-29

如何处理设计负责人资源抢占严重?结合设计交付场景分析
文章围绕设计负责人资源抢占严重这一问题,结合设计交付场景给出核心判断:问题根源通常不在负责人个人忙,而在于需求入口失控、优先级失效、关键人依赖过重和交付边界模糊。正文先用定性表格帮助判断抢占严重程度,再拆解四类成因,包括未分级需求过多、口头优先级压倒排期、负责人承担过多不可替代职责,以及返工回流导致持续救火。随后提出五步落地法:统一设计需求入口、建立清晰优先级规则、分层授权减少负责人对所有设计的参与、公开产能与冲突、将规则固化为稳定机制。文章还针对三类高频抢占场景——高优先级插单、负责人被拉入过多过程评审、返工反复回流——分别给出处理方法,最后强调落地难点主要在组织习惯而非方法本身,建议从收口需求、停止口头插单、让负责人退出常规评审三件事开始,逐步把人治救火转成机制化交付。
- Elara
- 2026-05-29