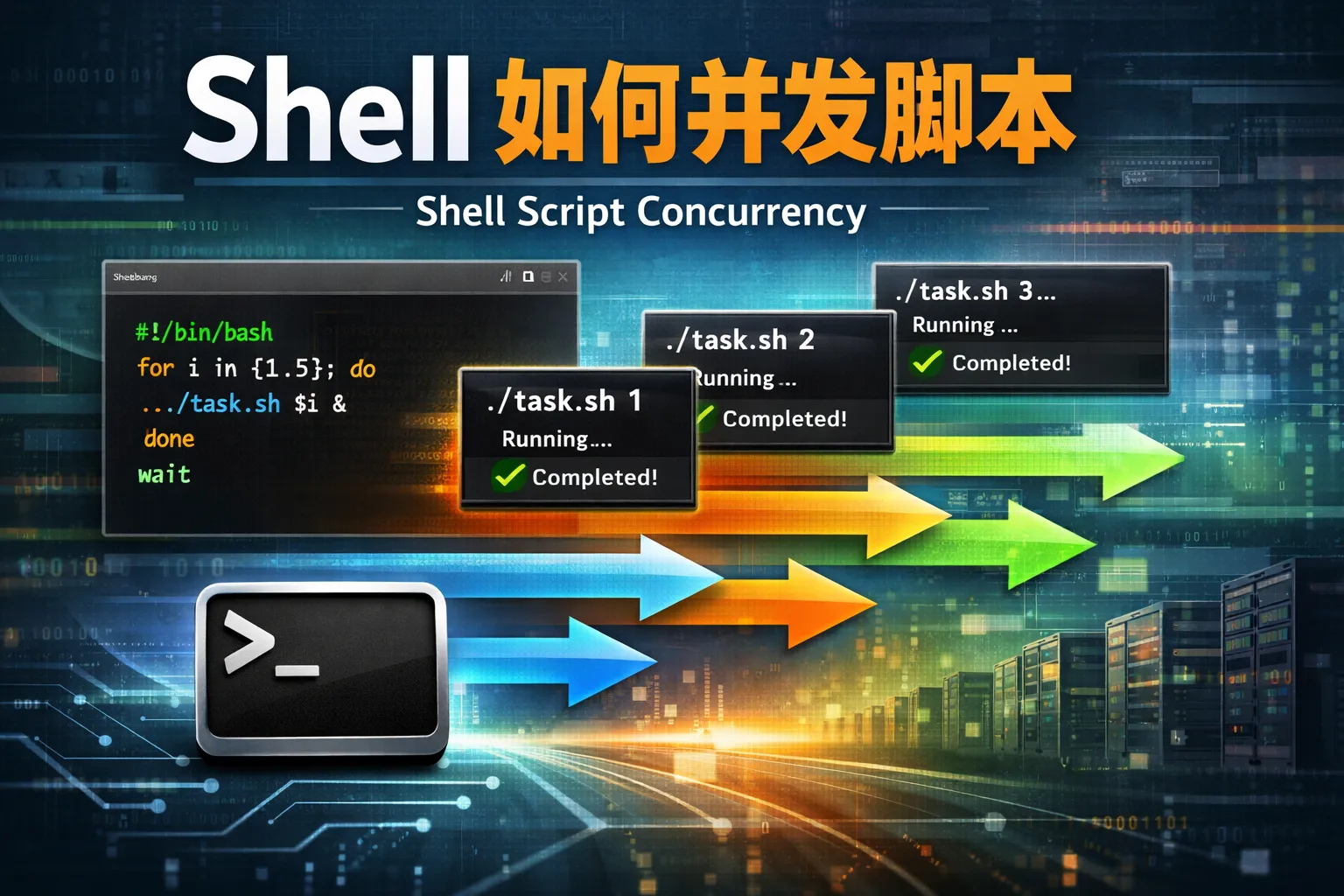
shell如何并发脚本
本文围绕Shell并发脚本展开,介绍了其底层逻辑、三种主流实现方案、性能优化要点、跨平台适配技巧及风险管控方法,结合权威报告数据和对比表格分析了不同方案的适用场景和优劣势,帮助运维团队通过轻量化改造提升脚本执行效率。
 Rhett Bai
Rhett Bai- 2026-03-03

java的同步和异步如何实现
本文围绕Java同步与异步实现展开,详细讲解了同步锁、原子类等同步技术的实现逻辑,以及Future、CompletableFuture等异步方案的落地路径,对比了同步异步的适用场景,结合权威报告数据指出异步技术能大幅提升系统吞吐量,同时梳理了开发中的常见错误与企业级落地实践,最后探讨了Java并发模型的未来优化方向。
- William Gu
- 2026-02-27

java如何确保原子性
本文围绕Java原子性保障展开,从底层JMM内存模型逻辑、内置四大实现方案、分布式场景适配、选型对比及实战避坑等多维度深入解析,结合权威行业报告数据,帮助开发者根据业务场景匹配最优原子性实现路径,降低并发冲突率,提升应用稳定性与吞吐量。
- Rhett Bai
- 2026-02-24

java中如何线程锁
本文系统梳理了Java线程锁的核心类型、底层实现原理、选型优化策略,结合权威行业报告数据与实战经验,拆解了锁的适用场景、常见坑点与避坑方案,帮助开发者落地高并发安全的Java应用,同时提供了企业级并发锁的标准化落地流程。
- Rhett Bai
- 2026-02-05

java如何同时并发
本文从Java并发的底层逻辑出发,拆解了线程模型与内存可见性原理,对比了原生线程、线程池、异步编排三类主流并发实现方案,分享了锁机制精细化优化、分布式并发控制的实战思路,还介绍了并发压测与bug排查方法以及2024年Java并发架构的升级趋势,帮助开发者搭建高效稳定的高并发Java应用
- Elara
- 2026-02-04

java 变量如何上锁
本文讲解Java变量上锁的底层逻辑,对比synchronized关键字与显式锁等多种上锁方式的特性、适用场景与性能差异,介绍volatile关键字与锁的搭配方案,分析上锁常见误区及规避方法,结合行业报告数据给出不同并发场景下的选型建议,帮助开发者实现线程安全的变量访问同时优化并发性能。
- Elara
- 2026-02-04

java如何重置线程
本文围绕Java线程重置展开,说明Java线程无法直接重置,主流方案是通过线程池间接实现重置。先讲解Java线程生命周期不可逆性和原生废弃方法的安全隐患,再拆解原生API下的中断优雅退出、Callable封装替代方案,对比不同方案的优劣。接着深入分析线程池架构下的批量重置实践,结合性能数据说明线程池复用可降低超60%的资源损耗,并给出性能管控与异常兜底策略。最后介绍主流框架适配策略与企业级方案落地流程,结合权威报告提供实战指导。
- Rhett Bai
- 2026-02-04

java socket如何并发
本文围绕Java Socket并发展开,介绍了单线程Socket的局限性和并发能力判定标准,拆解了传统BIO模型的并发瓶颈,对比了BIO、NIO、AIO三种模型的核心参数,讲解了NIO多路复用的工作流程与零拷贝优化机制,介绍了Netty框架的封装优势与并发防护机制,同时给出了系统参数和应用层的性能调优方案以及跨平台适配细节,指出多路复用模型和线程池组合是企业级Socket并发的最优实践。
- Rhett Bai
- 2026-01-31

python如何同时爬取多个网页
文章系统回答了如何用Python同时爬取多个网页:在I/O密集场景优先采用异步协程(asyncio+aiohttp/httpx)或线程池(requests+concurrent.futures),复杂工程需求可用Scrapy。核心实践包括连接池与并发上限、速率限制、超时与指数退避、URL去重、断点续抓与幂等落库,并遵守robots.txt与站点条款。文中提供协程与线程池示例代码、方案对比表、监控与优化清单,并强调在团队协作中通过工具记录策略与指标,逐步将脚本升级为可观测、可扩展的抓取平台。
- Rhett Bai
- 2026-01-14

python如何判断线程是否结束
本文系统阐述了在 Python 中判断线程是否结束的工程化方法:以 join() 作为最稳妥的完成判定,辅以 is_alive() 的非阻塞轮询;在线程池场景下以 Future.done()/result()/exception() 同时掌握完成状态与结果;在数据管道中采用 Queue.join() 定义“任务处理完毕”;并通过 Event 等协作信号实现可取消、可收尾。文章还对守护线程、异常传播与超时边界进行了澄清,给出方法对比表与实操清单,并强调观测性与团队协作的重要性,建议把并发结束判定纳入流程与工具(如 PingCode)以降低风险并提升可维护性。
- William Gu
- 2026-01-14
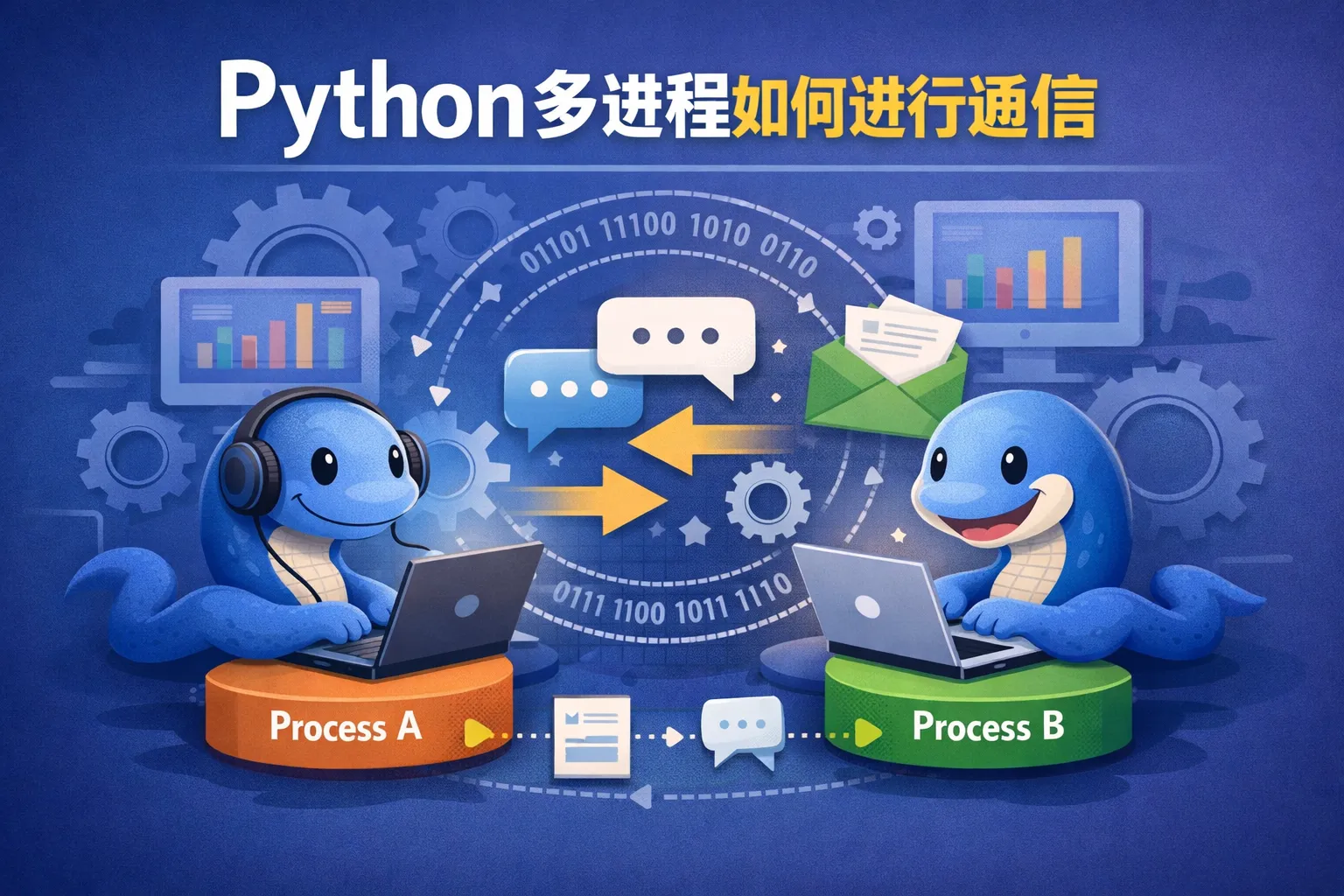
python多进程如何进行通信
本文围绕Python多进程通信的核心问题,给出可操作的选择与实施路径:在本地场景优先采用Queue、Pipe与Manager处理对象消息,数值密集用Value/Array或SharedMemory实现低拷贝;跨主机场景转向Socket或消息队列如ZeroMQ、Redis、RabbitMQ。重点强调序列化安全、锁与超时、背压与容错,并以日志与监控保障可观测性。结合明确的协议规范与工程流程,通信层可在性能、可靠性与可维护性之间实现稳态平衡。
- Elara
- 2026-01-14

python类中如何多线程调用
Python类中多线程调用需要在结构化封装的同时确保线程安全,尤其在共享资源访问时要使用锁机制。可根据任务属性选择直接创建线程、继承Thread类或利用线程池管理,并在IO密集型任务中获得明显性能提升。结合队列可实现生产者-消费者模式,在复杂项目中提高任务吞吐量与稳定性。未来趋势包括智能线程调度、协程与多线程融合,以及云原生多线程服务场景的拓展。
- Rhett Bai
- 2026-01-14

python子线程如何结束主线程
在 Python 中,子线程无法直接强制终止主线程,但可以采用共享变量轮询、线程事件(Event)或消息队列等协作式方法来通知主线程退出,从而确保程序的稳定性与数据完整性。这类机制在多线程应用中需要与资源释放、异常处理结合,避免出现状态不一致。在更复杂的场景下,可考虑使用多进程模型或集成项目协作平台如 PingCode,将控制策略嵌入自动化工作流。随着 Python 并发模型的演进,线程间通信与终止机制将更加安全且易于集成企业级应用。
- Elara
- 2026-01-14

python如何多线程执行任务
Python 多线程主要用于提升I/O密集型任务效率,通过threading或ThreadPoolExecutor等工具实现任务并发执行,能显著减少等待时间并提升系统吞吐量,但受制于GIL在CPU密集型场景中作用有限。有效的多线程方案需结合任务类型、线程同步机制和线程池调度优化,以保障资源安全与稳定性。未来多线程将更多与异步协程混合应用,尤其在分布式协作与实时数据处理中,与项目管理平台深度融合,形成高效任务模型。
- Elara
- 2026-01-14

Python如何同时运行多个程序
Python同时运行多个程序可通过多进程、多线程、协程等技术实现,需根据任务类型选择合适的并发模型。多进程适合CPU密集型任务,多线程适合I/O密集型,而协程则高效支持事件驱动与网络I/O。还可通过subprocess调用外部程序实现跨语言并行。结合任务调度系统与项目管理工具(如PingCode)能将多任务运行融入团队协作流程。未来趋势是混合并发模型与云原生环境结合,实现更大规模、高效率的任务并行。
- Joshua Lee
- 2026-01-14

Python多进程如何不重复
在 Python 多进程环境中避免任务重复,核心在于利用共享状态与唯一性校验机制来确保每个任务仅执行一次。可选策略包括使用 Manager 共享集合、队列结合唯一 ID 校验、Redis SETNX 锁以及数据库唯一索引,不同方法在性能和扩展性上各有优劣。在本地高并发场景中,集合与队列的组合表现优异;分布式场景中则更适合使用 Redis 锁。结合项目管理平台如 PingCode,可将任务唯一性控制集成到团队协作流程中。未来,去重机制将更加智能、云原生化,并减少跨节点同步成本。
- William Gu
- 2026-01-14

python异步是如何控制并发的
Python异步通过事件循环与协程机制高效控制并发,适用于大量I/O密集型任务,通过非抢占式调度减少线程切换与资源消耗。事件循环管理任务队列并在等待I/O期间切换其他任务,实现单线程下的高并发处理。与多线程、多进程相比,异步在降低GIL影响与提升网络服务吞吐量上更有优势,尤其在Web、API聚合和大型系统协作中表现突出。优化异步性能需明确任务类型、控制并发数量并灵活使用超时与批处理,未来异步将结合结构化并发与云原生环境进一步增强稳定性与可扩展性。
- William Gu
- 2026-01-14

python下是如何使用线程的
Python 中的线程是一种在同一进程内并发执行任务的机制,适用于提升 I/O 密集型任务的效率和程序响应性。常用 threading 模块创建和管理线程,可通过 target 函数或继承 Thread 实现,配合锁等同步工具避免资源竞争。在任务量大但时间短的场景中,ThreadPoolExecutor 提供高效调度。线程相比多进程更轻量,但受 GIL 限制不适合 CPU 密集型任务。合理规划线程数、优化锁使用并结合异步 I/O,可显著提高整体性能。未来趋势将走向线程与异步协程并用,并在统一任务管理平台中提升可维护性与可控性。
- William Gu
- 2026-01-14

python多线程是如何切换的
Python多线程的切换由CPython的GIL与操作系统调度共同决定:只有持有GIL的线程能执行字节码,解释器在约5毫秒的切换间隔或遇到I/O、sleep、锁等待等安全点释放GIL,其他线程再竞争获取;因此切换呈“协作式让渡+抢占式执行”的混合模式,I/O密集负载并发收益明显,CPU密集则建议采用多进程或释放GIL的扩展,未来PEP703的可选无GIL将改变并行版图。
- Rhett Bai
- 2026-01-14

python如何判断线程的状态
本文从 Python 标准库 threading 的 is_alive()、enumerate()、active_count()、join(timeout) 与属性 daemon/ident 入手,阐明如何判断线程存活与推进;在需要细粒度时,辅以 Event、Condition、Queue 构建自定义状态机,并以结构化日志与心跳将“活着”转化为“有进展”。对于线程池任务,推荐用 concurrent.futures 的 Future.done()/running()/cancelled() 与 result(timeout) 做任务级判定;生产环境结合超时、重试与退避治理,并以可视化与告警闭环提升可观测性。文章强调组合方法优于单一 API,引用官方文档与行业调研支撑实践,并建议在协作系统中同步关键状态以增强研发与运维的协同效率。
- Elara
- 2026-01-13