
java并行计算有什么优点
Java 并行计算的核心优势在于充分利用多核硬件资源,通过多线程与并发模型显著提升程序性能、系统吞吐量和响应速度。它不仅能在高并发场景下降低延迟、改善用户体验,还依托成熟的并发工具和明确的内存模型,保障并发执行的安全性与可预测性。结合良好的可扩展性和长期生态支持,Java 并行计算已成为构建高性能、可持续演进系统的重要基础能力。
 Joshua Lee
Joshua Lee- 2026-04-13

java程序并行有什么好处
Java 程序并行的核心价值在于充分利用多核硬件能力,通过同时执行多个任务来提升整体性能与系统弹性。并行不仅可以显著提高 CPU 利用率、缩短计算与 I/O 密集型任务的完成时间,还能在高并发场景下改善响应能力,降低单点阻塞带来的风险。从长期工程角度看,并行化设计有助于系统扩展与架构演进,是现代 Java 应用应对复杂业务和性能压力的重要基础能力。
- Joshua Lee
- 2026-04-13

如何开发超级处理器软件
本文系统阐述了开发超级处理器软件的核心方法与实践路径,强调其本质是一项以硬件体系结构为基础、以并行算法与工程治理为支撑的系统工程。文章指出,真正高效的超级处理器软件并非单纯追求代码速度,而是在理解处理器与互连特性的前提下,合理选择并行模型,重构算法与数据结构,并通过严谨的软件工程与性能优化方法实现长期可扩展性。最后结合不同开发路径对比与未来趋势,说明只有在性能、维护性与演进能力之间取得平衡,才能构建具备持续价值的超级处理器软件。
- Elara
- 2026-04-13

常见并行编程模型有什么
常见并行编程模型包括共享内存、消息传递、数据并行、任务并行、流式并行、MapReduce、GPU并行和混合并行等类型。不同模型在内存访问方式、扩展能力和编程复杂度方面存在差异,适用于单机多核、分布式集群、批处理计算或实时处理等不同场景。随着异构计算与人工智能的发展,混合并行与自动化并行框架将成为未来趋势。
- Joshua Lee
- 2026-04-10

常见并行编程模型有几种
常见并行编程模型主要包括共享内存、消息传递、数据并行、任务并行、流式并行、GPU 并行、MapReduce 以及混合并行模型等类型。不同模型在通信方式、扩展能力、编程复杂度与适用场景上存在明显差异。共享内存适合单机多核,消息传递适合分布式集群,数据与GPU并行适用于高密度计算,MapReduce适合大规模批处理,而混合模型则代表未来异构计算的发展方向。合理选择并行模型是构建高性能系统的关键。
- Elara
- 2026-04-10

支持编程的显卡有哪些
支持编程的显卡主要包括NVIDIA、AMD和Intel的主流独立显卡产品,它们通过CUDA、OpenCL或其他并行计算框架实现通用计算能力。NVIDIA在AI和科研计算领域生态成熟,AMD强调开放标准与性价比,Intel则在新兴计算模型上持续完善。选择时应结合具体编程场景、显存容量、算力指标与开发生态综合评估,而不仅仅关注图形性能。随着AI与高性能计算发展,显卡编程能力将持续增强并趋向开放化。
- William Gu
- 2026-04-10

并行式编程模型有哪些
并行式编程模型是提升系统性能与资源利用率的重要方法,主要包括共享内存模型、消息传递模型、数据并行模型、任务并行模型、流式并行模型以及Actor模型等。不同模型适用于不同计算架构与业务场景:共享内存适合多核环境,消息传递适用于分布式系统,数据与任务并行满足批量处理与复杂逻辑需求,而Actor与流式模型更适应高并发与实时处理。实际工程中往往采用多种模型结合,以在性能、扩展性与可维护性之间取得平衡。未来并行模型将向多模型融合与自动化调度方向发展。
- Joshua Lee
- 2026-04-10

gpu编程有什么用?
GPU编程的核心价值在于利用图形处理器的并行计算能力,大幅提升数据密集型与计算密集型任务的执行效率。相比CPU串行处理方式,GPU能够通过海量核心并行运算显著缩短人工智能训练、科学模拟与图形渲染等任务的处理时间。当前在高性能计算与人工智能领域,GPU已成为关键算力基础设施。随着云计算与异构架构发展,GPU编程正从专业领域走向更广泛应用,成为数字时代的重要底层能力。
- Joshua Lee
- 2026-04-10
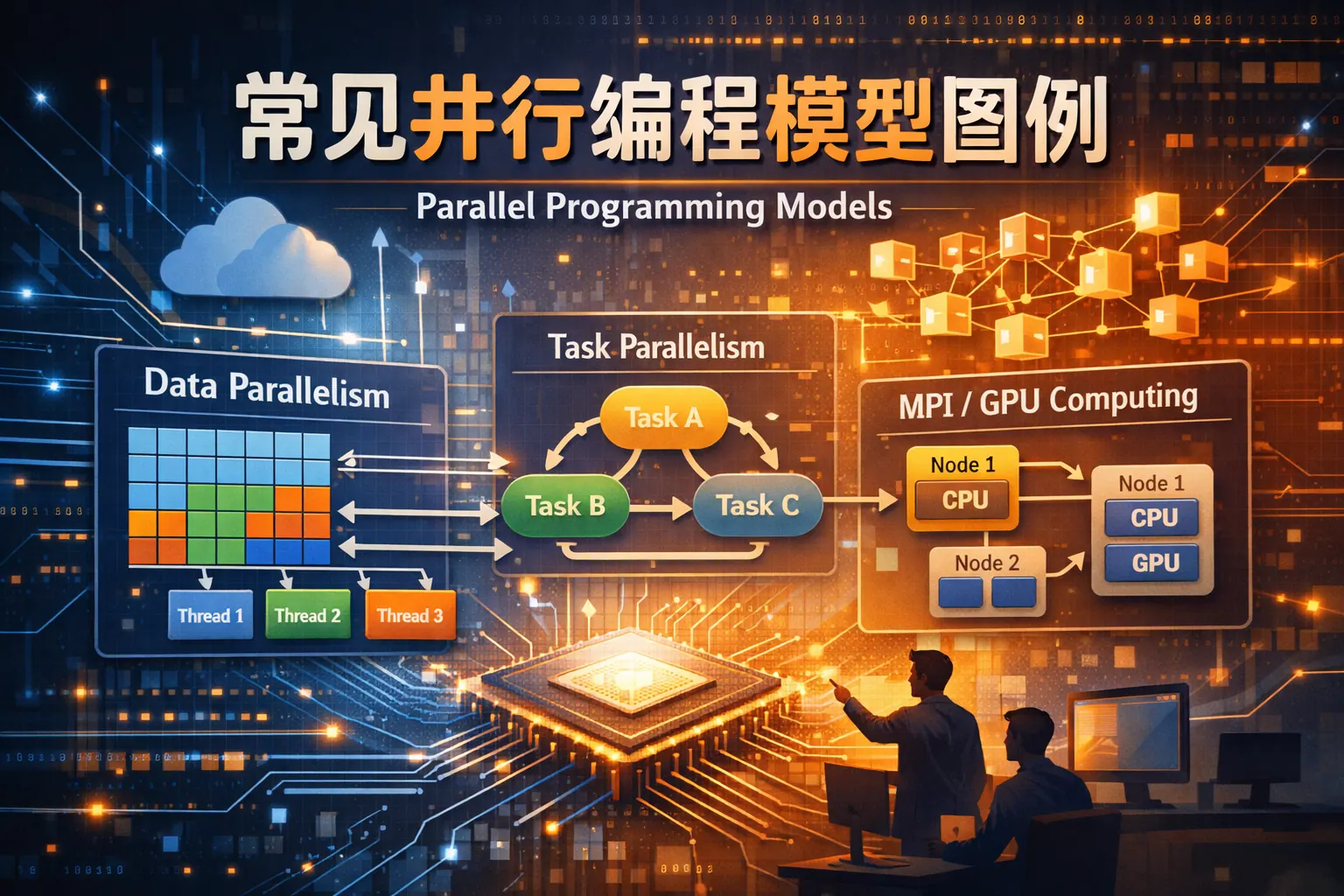
常见并行编程模型图例有
常见并行编程模型包括共享内存模型、消息传递模型、数据并行模型、任务并行模型、流水线模型、主从模型以及Actor与数据流模型等。这些模型在内存结构、通信方式与扩展能力上各有差异,适用于不同规模与场景的并行计算系统。理解其典型结构图示与核心机制,有助于构建高性能、可扩展的软件架构。随着多核与分布式计算的发展,混合型并行模型将成为未来趋势。
- Rhett Bai
- 2026-04-10

gpu编程有什么优势
GPU编程的优势主要体现在大规模并行计算能力、高吞吐量处理效率以及优异的能效比。在人工智能训练、科学计算和大数据分析等高并行场景中,GPU通过数千核心协同运算显著提升性能,同时具备良好的扩展性和成熟的软件生态。虽然不适用于复杂控制逻辑任务,但在数据密集型计算领域,GPU已成为关键算力基础设施,未来将在云计算与智能计算体系中持续发挥核心作用。
- William Gu
- 2026-04-10

gpu编程平台有哪些
GPU编程平台包括CUDA、OpenCL、ROCm、DirectCompute、Metal和WebGPU等,不同平台在硬件支持、生态成熟度与应用场景方面各有差异。CUDA在AI训练与高性能计算中应用广泛,OpenCL强调跨平台兼容,ROCm提供开放替代方案,Metal和DirectCompute适合系统级图形计算,而WebGPU代表浏览器端加速趋势。选择GPU编程平台应综合考虑硬件环境、性能需求与生态支持,并关注未来异构计算与云端GPU融合的发展方向。
- Elara
- 2026-04-10

如何让代码可以并行计算
让代码实现并行计算的关键在于拆分独立任务并利用多线程、多进程或分布式架构同时执行,从而提升资源利用率和整体性能。文章系统阐述了并行计算的原理、实现方式、任务拆分策略、多线程与多进程优化方法,以及GPU和分布式架构的应用场景,并结合性能瓶颈与Amdahl定律分析实际优化路径。最终指出,并行能力已成为现代软件架构设计的核心能力,需从系统层面整体规划。
- William Gu
- 2026-04-09

如何用显卡运行代码设置
用显卡运行代码的核心是利用GPU的并行计算能力,将计算密集型任务从CPU转移到支持CUDA或其他计算框架的显卡上执行。实现这一目标需要具备支持计算的显卡硬件、正确安装驱动和工具包,并在代码层面启用GPU设备,如使用CUDA编程或在PyTorch等框架中调用cuda接口。合理优化数据传输和显存管理,可以显著提升训练与计算效率。随着人工智能与高性能计算的发展,GPU加速已成为开发者的重要基础能力。
- William Gu
- 2026-04-08

如何使用gpu加速python代码
使用GPU加速Python代码的关键在于将计算密集型任务从CPU迁移到具备大规模并行能力的GPU,并借助深度学习框架、数组替代库或自定义并行编程工具实现高效计算。适合GPU优化的任务通常具备数据规模大、可并行性强的特点,例如矩阵运算和模型训练。实际应用中需要关注数据传输开销、显存管理和线程组织方式,合理选择技术路径并持续进行性能调优,才能真正获得稳定且显著的加速效果。
- Joshua Lee
- 2026-04-08

linux如何使用gpu加速代码
在 Linux 系统中使用 GPU 加速代码,核心是将计算密集型任务迁移到具备高并行能力的 GPU 上执行,常见方式包括使用 CUDA、OpenCL、ROCm 或基于 Python 框架的 GPU 后端。完整流程涵盖驱动安装、开发环境配置、代码并行化改造与性能调优。是否获得显著性能提升,取决于算法并行度、数据传输开销与线程配置优化程度。合理使用性能分析工具并控制主机与显存之间的数据交换,是实现高效 GPU 加速的关键。随着异构计算标准和容器化技术的发展,Linux 下 GPU 加速正变得更加普及和工程化。
- Joshua Lee
- 2026-04-08

python普通代码如何gpu加速
Python 普通代码实现 GPU 加速的关键在于将计算密集型任务迁移至支持 GPU 的计算库或框架,如使用 CuPy 替换 NumPy、通过 Numba 编译自定义函数、或借助 PyTorch 等张量框架完成设备迁移。真正的性能提升依赖于任务是否具备高并行特征以及是否有效控制数据传输开销。未来趋势是框架自动优化与异构计算融合,开发者更应关注算法结构与数据流设计。
- William Gu
- 2026-04-08

如何使用mpi程序编写代码
MPI 程序编写的关键在于理解分布式内存模型和显式消息传递机制,掌握初始化、进程编号获取、点对点与集合通信等核心函数结构,并通过合理的数据划分与通信优化实现高效并行计算。通过实例可以看出,MPI_Reduce、MPI_Bcast 等集合通信函数在实际开发中极为重要,而性能提升主要依赖减少通信开销和避免死锁。随着 MPI 标准持续演进,其在高性能计算和大规模分布式系统中的应用前景将更加广泛。
- Joshua Lee
- 2026-04-07

如何让代码在gpu运行
让代码在GPU上运行的关键在于确认硬件与驱动支持、选择合适的并行计算框架,并将可并行的数据密集型任务迁移到GPU执行环境中。GPU凭借大规模并行架构,在矩阵运算、深度学习训练和科学计算中能显著提升性能,但前提是算法结构适合并行化。开发者可通过CUDA进行底层优化,或借助主流框架快速启用GPU加速,同时注意显存管理与设备匹配问题。随着算力需求增长,GPU计算正成为开发者的重要基础能力。
- Joshua Lee
- 2026-04-07

如何使代码运行在gpu
要让代码运行在GPU上,关键在于理解并行计算原理、配置支持GPU的硬件与驱动环境,并在代码中显式调用GPU资源。GPU适合大规模并行任务,如深度学习和科学计算,但需注意版本匹配、显存管理和数据传输优化。未来随着云计算和异构架构发展,GPU加速将更加普及与标准化。
- Rhett Bai
- 2026-04-07

如何代码用gpu加速Python
Python 实现 GPU 加速的核心在于将大规模可并行的计算任务交由 GPU 执行,常见方式包括使用深度学习框架自动调用 CUDA、用 CuPy 替代 NumPy、借助 Numba 编写自定义 GPU Kernel,以及优化数据传输流程。GPU 适用于矩阵运算、深度学习训练和图像处理等高并行场景,但需避免频繁数据拷贝带来的性能损耗。未来趋势将从单卡加速走向多卡与异构计算协同。
- William Gu
- 2026-04-07