
java怎么判断有几个字符串
本文从工程语义出发解释了 Java 中“有几个字符串”的多种含义,涵盖数组、集合、文本切割、去重统计与频次统计等常见场景,强调应先明确统计口径再选择 API。通过对比不同实现方式的特点与复杂度,说明数据结构选择比语法技巧更关键,并结合权威资料给出可维护性的实践建议。
 Elara
Elara- 2026-04-14

java截取字符串有什么用
Java 截取字符串的作用在于从原始文本中提取对业务有价值的信息,是数据处理、业务规则解析、接口交互和日志分析中的基础能力。通过合理的字符串截取,Java 程序可以在不破坏原始数据的前提下完成校验、分类、统计和解析,从而提升系统性能、可维护性和稳定性。无论是在用户输入处理、业务编码解析,还是在日志与运维场景中,字符串截取都承担着连接非结构化文本与结构化逻辑的重要角色。
- Elara
- 2026-04-14

java 十进制转十六进制 有符号
Java 十进制转十六进制的有符号问题本质源于补码机制。Java 所有整数类型均采用补码表示,负数转换为十六进制时输出的是其补码位模式,而非带负号的数学表示。理解补码原理、符号扩展与类型提升,是正确处理负数十六进制输出的关键。在实际开发中,可根据业务需要选择补码输出或自定义带符号格式,并注意不同整型类型和无符号转换方法的差异。
- William Gu
- 2026-04-14

java判断有多少个字符串
本文系统讲解了在 Java 中判断“有多少个字符串”的多种业务语义与实现方式,指出该问题并非单一技术点,而是取决于数组、集合、文本或业务规则等不同场景。文章从数组和集合的基础统计讲起,逐步深入到非空字符串、文本单词、唯一字符串以及条件统计等高级需求,并对不同方法的性能和适用场景进行了对比分析。通过工程实践和未来趋势的讨论,强调了在 Java 开发中应从业务语义出发选择最合适的字符串统计方案。
- Rhett Bai
- 2026-04-14

Java统计高于平均分数有多少个
本文系统讲解了在 Java 中统计高于平均分数有多少个的实现方法,从问题本质出发,详细分析了数组、集合以及 Java 8 Stream API 三种常见实现思路,并对它们的适用场景和优缺点进行了对比说明。文章结合示例代码、工程实践和常见错误,强调先计算平均值再进行统计的核心逻辑,同时延伸到真实业务系统中的应用价值。通过本文,读者不仅可以掌握基础写法,也能理解该问题在实际项目中的长期意义与发展趋势。
- Joshua Lee
- 2026-04-14

java十六进制转有符号十进制
本文系统阐述了 Java 中十六进制转有符号十进制的原理与实践方法,核心在于明确整数位宽并正确理解二进制补码规则。文章从 Java 整数类型的底层表示出发,分析了为何同一十六进制值在不同类型下会得到不同结果,并结合示例与对比表说明强制类型转换、位运算及通用算法的适用场景。同时总结了常见错误与工程实践建议,强调在协议解析和底层开发中统一位宽与符号语义的重要性。
- William Gu
- 2026-04-13

java数据库去重有几种方法
Java 与数据库交互过程中,去重通常不止一种实现方式,而是可以从查询、写入、结构设计与应用层多个层面完成。常见方法包括 DISTINCT、GROUP BY、唯一索引、写入冲突处理、Java 集合去重以及批量清洗等,整体约有五到八种实践路径。核心原则是优先在数据库层面控制重复,其次再由 Java 补充复杂业务规则,从而在性能、数据一致性与系统可维护性之间取得平衡。
- Joshua Lee
- 2026-04-13

java中对数据进行排序有几种方法
本文系统梳理了 Java 中常见的数据排序方法,涵盖数组排序、集合排序、Comparable 自然排序、Comparator 定制排序以及 Stream 流式排序等主要方式。核心观点在于:Java 排序并不存在通用方案,开发者需要根据数据结构、排序规则复杂度以及是否允许修改原数据等因素进行选择。通过对不同排序机制的原理、特性与适用场景进行对比,可以在性能、可维护性和扩展性之间取得更合理的平衡,这也是现代 Java 开发中排序设计的关键所在。
- Elara
- 2026-04-13
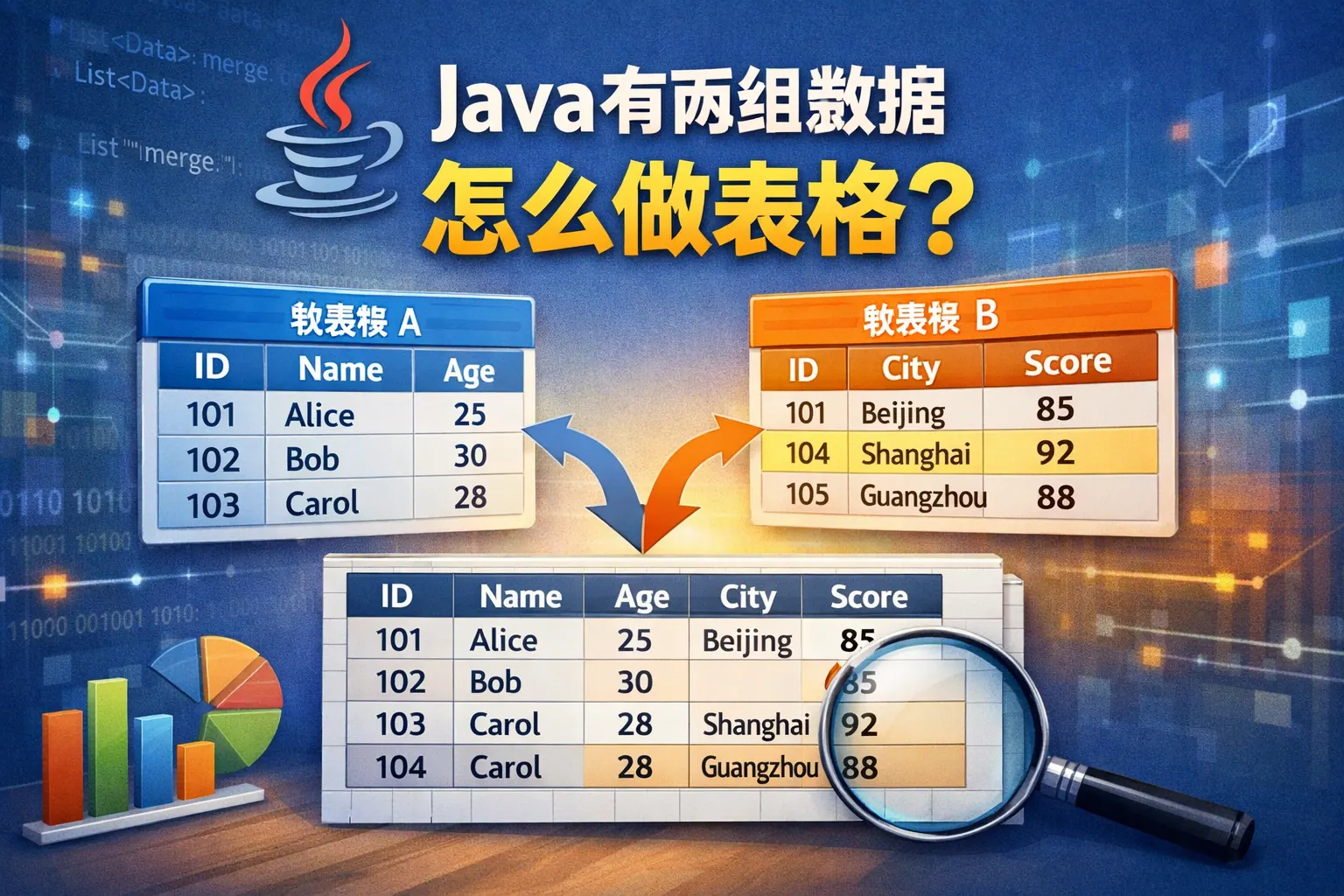
java有两组数据怎么做表格
在 Java 中将两组数据生成表格,关键在于先进行结构对齐,再根据使用场景选择合适方式,如二维数组打印、集合封装后渲染 HTML 表格,或借助报表库导出 Excel 文件。不同方法适用于控制台输出、Web 展示或文件下载等场景。合理设计数据模型、处理异常并优化性能,是实现稳定高效表格生成的核心。
- Elara
- 2026-04-13

java怎么查询xml有多少个标签
本文系统讲解了在 Java 中统计 XML 标签数量的核心思路与实现方式,重点分析了 DOM、SAX、StAX 和 XPath 四种常见解析方案在内存占用、性能和适用场景上的差异。文章强调,XML 标签统计本质是对元素节点的计数,需明确边界定义并兼顾安全配置。通过对比分析与工程实践建议,帮助开发者根据 XML 数据规模和业务需求选择合适的解析方式,从而在保证准确性的同时提升系统性能与可维护性。
- William Gu
- 2026-04-13

java中常用的流有几种类型
Java 中常用的流主要包括字节流、字符流、节点流和处理流,它们从不同维度解决数据传输与处理问题。字节流以字节为单位,适用于所有二进制数据;字符流面向文本并自动处理编码;节点流直接连接数据源,是 IO 操作的基础;处理流则在节点流之上提供缓冲、转换等增强能力。此外,Java 8 引入的 Stream API 属于数据计算层面的函数式流,与传统 IO 流概念不同但同样重要。理解这些流类型及其适用场景,是编写高质量 Java 程序的关键。
- Elara
- 2026-04-13

java解析xml有哪几种方法
Java解析XML主要包括DOM、SAX、StAX、JAXB以及第三方库等方式。DOM适合小型复杂结构文件,SAX和StAX适合大规模流式处理,JAXB适用于对象绑定场景,不同方法在内存占用、性能表现与开发复杂度上各有差异。实际选型应结合数据规模、性能要求与系统架构,同时注意安全配置与团队协作管理。未来趋势将更加注重流式处理能力与安全防护机制。
- Rhett Bai
- 2026-04-13

java判断数组中是否有不重复值
本文系统讲解了在 Java 中判断数组是否存在不重复值的多种实现思路,核心结论是通过频次统计即可可靠解决该问题。文章从问题定义入手,分析了双重循环、HashMap 计数、Set 特性、排序遍历以及 Stream API 等常见方案,并对它们的时间复杂度、内存开销和适用场景进行了对比。整体来看,基于 HashMap 的实现方式在性能与扩展性上更适合通用业务场景,同时强调了边界条件处理和工程实践中的注意事项。
- Rhett Bai
- 2026-04-13

java中处理数据的方式有哪些内容
本文系统梳理了 Java 中处理数据的主要方式,从基础内存数据结构、Stream 函数式处理、多线程并发模型,到 IO、序列化、数据库交互以及批处理和实时流式处理,全面说明了不同场景下的适用思路。文章强调,Java 数据处理并不存在单一通用方案,关键在于结合数据规模、实时性和系统复杂度进行选择。随着技术演进,Java 数据处理正逐步向并发化、异步化和流式化方向发展。
- Rhett Bai
- 2026-04-13

java中排序有哪几种方法
本文系统梳理了 Java 中常见的排序方法,从整体设计思想出发,深入解析了 Arrays 与 Collections 排序、Comparable 与 Comparator 接口、Stream 与并行排序等多种方式的适用场景与差异。通过对底层算法、稳定性和性能特点的对比,文章指出在实际开发中应优先使用标准库排序,并通过 Comparator 表达业务规则。最后结合工程实践,总结了排序方法的选择原则,并对 Java 排序未来的发展趋势进行了预测。
- William Gu
- 2026-04-13

java中字符串重复的有几个
在 Java 中,字符串“重复的有几个”取决于具体定义,既可以指重复字符的种类数量,也可以指重复出现的字符总数。Java 并未提供直接统计重复的内置方法,但可以通过 HashMap、Set 或 Stream 等方式在 O(n) 时间复杂度内完成统计。其中 HashMap 兼顾通用性与可维护性,是最常见的实现方案。实际开发中需先明确业务语义,再选择合适的数据结构和实现方式,避免概念混淆和性能浪费。
- Rhett Bai
- 2026-04-13

java二进制转有符号整数
Java二进制转有符号整数的核心在于理解补码表示与符号扩展规则。Java所有整数类型均采用补码存储,最高位为符号位,负数通过按位取反加一表示。在进行字符串解析、字节数组转换或位运算时,需要注意类型提升与符号扩展机制,合理使用掩码与强制类型转换,才能保证结果正确。掌握补码原理与位运算逻辑,是正确处理二进制数据和跨系统交互的关键能力。
- William Gu
- 2026-04-13

java怎么判断有几个数相同的数
本文系统讲解了在 Java 中判断“有几个数相同”的多种实现思路,从问题本质出发,分别分析了双重循环、Map 统计、排序比较以及 Java 8 Stream 等常见方法,并对它们的性能与适用场景进行了对比。文章指出,HashMap 和 Stream 是实际项目中最常用的方案,而浮点数和自定义对象场景则需要额外注意比较规则。通过工程化视角与权威资料引用,帮助读者在不同业务环境下做出更合理的技术选择。
- Elara
- 2026-04-13

java中的排序方式有哪几种
Java 中的排序方式可以从算法、语言机制和标准库三个层面来理解,包括基础排序算法、Comparable 与 Comparator 的对象排序机制,以及 Collections.sort、Arrays.sort 等内置实现。实际开发中更应关注标准库与接口化排序的适用场景,而不是手写算法本身。随着并行排序与算法优化的引入,Java 排序在性能与稳定性之间取得了更好的平衡。
- Rhett Bai
- 2026-04-13

java数值转字符串有什么作用
Java数值转字符串的核心作用在于将计算型数据转化为可展示、可传输和可持久化的文本格式,是连接计算逻辑与用户展示、接口通信之间的关键桥梁。它广泛应用于数据展示、日志记录、接口交互和系统集成等场景,同时在精度控制、格式统一和跨平台兼容方面发挥重要作用。合理选择转换方式并优化性能,有助于提升系统稳定性与可维护性。
- Elara
- 2026-04-13