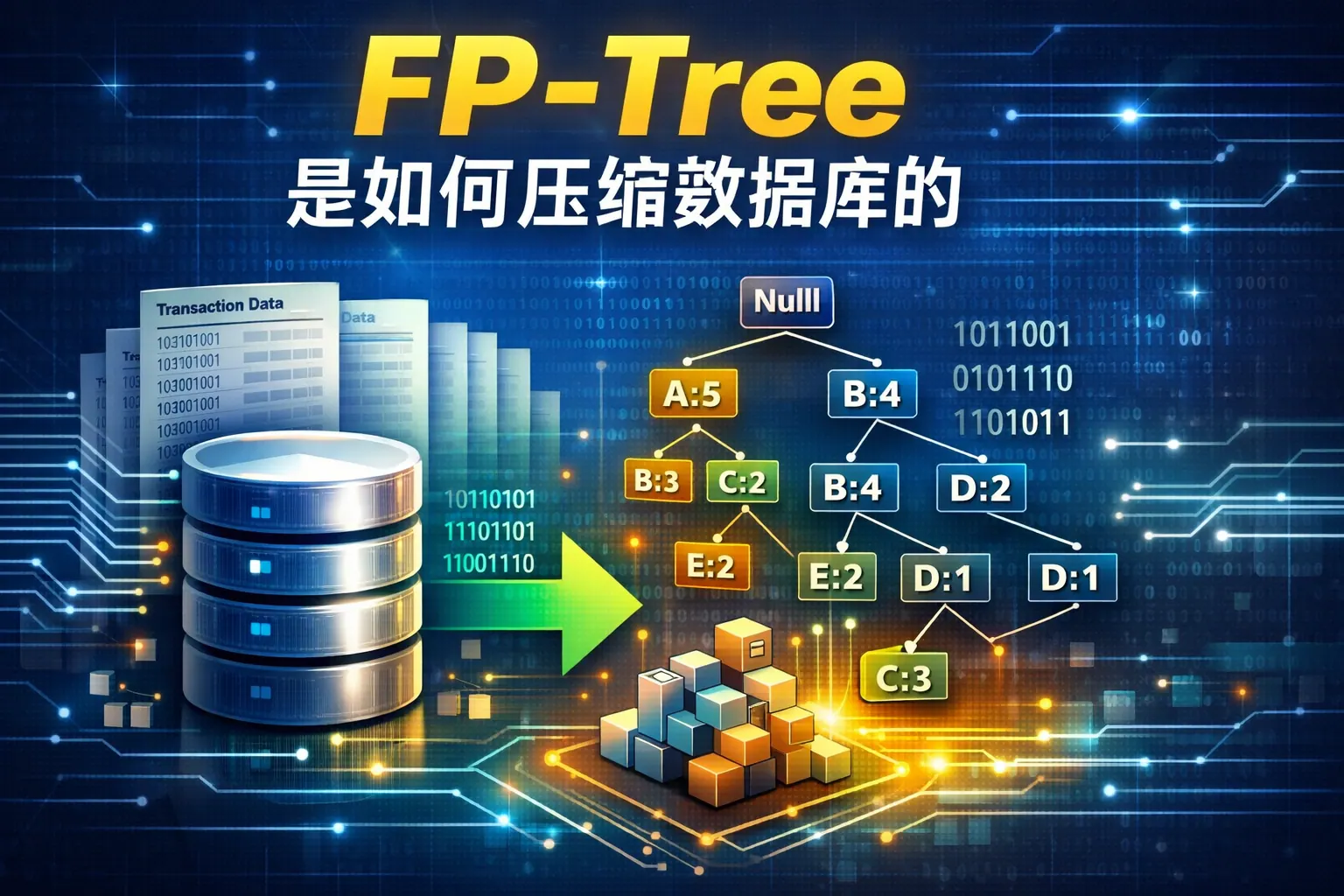
fptree是如何压缩数据库的
FP-Tree通过筛选频繁项、对事务排序并构建前缀共享的树形结构,实现对原始事务数据库的结构性压缩。其核心机制是路径复用与节点计数统计,使重复前缀只存储一次,从而减少数据冗余与扫描次数。相比传统算法,FP-Tree仅需两次扫描数据库即可完成构建,并通过头指针表与条件模式基递归挖掘进一步压缩搜索空间,在高相似度数据场景下压缩效果尤为明显。
 Joshua Lee
Joshua Lee- 2026-04-09

数据挖掘中python应用的实例
Python 在数据挖掘中的应用已覆盖数据采集、清洗、建模与可视化全流程,并在电商预测、金融风控、文本分析与客户分群等场景中形成成熟实践。依托完善的开源生态与机器学习工具,Python 能够快速构建高效的数据挖掘模型,同时支持向大数据环境扩展。未来随着自动化与智能化技术发展,Python 在数据分析与智能决策中的核心地位将持续增强。
- Rhett Bai
- 2026-03-29

python在数据挖掘的应用实例
本文系统梳理了 Python 在数据挖掘中的典型应用实例,从数据预处理、探索性分析到机器学习建模与文本挖掘,全面说明了 Python 如何支撑完整的数据挖掘流程。文章结合真实工具生态与权威研究指出,Python 的核心优势在于高效率、强扩展性与良好的业务解释能力。通过具体场景和对比分析可以看出,Python 已成为数据挖掘领域的基础语言,并将在未来的数据驱动决策与智能分析中持续发挥关键作用。
- Rhett Bai
- 2026-03-29

频繁模式挖掘的方法python
本文系统介绍了频繁模式挖掘的核心方法及其在 Python 中的实现方式,重点解析了 Apriori、FP-Growth 和 Eclat 三种主流算法的原理差异、性能特点与适用场景,并结合代码示例说明如何使用 Python 工具库完成频繁项集与关联规则挖掘。同时对算法优化策略、实际应用场景及未来发展趋势进行了深入分析,为数据分析与数据挖掘实践提供系统参考。
- Joshua Lee
- 2026-03-28

python的聚类分析数据挖掘
本文系统阐述了 Python 在聚类分析数据挖掘中的核心价值与实践方法,从算法原理、技术生态、数据预处理到行业应用进行了全面分析。文章指出,Python 依托成熟的科学计算与机器学习生态,使聚类分析能够高效揭示数据内在结构,并服务于业务决策与科学研究。同时强调了数据质量、特征工程与结果解释在聚类中的关键作用,并结合权威资料展望了聚类分析在自动化与智能化方向的发展趋势。
- Elara
- 2026-03-28

c语言如何找富豪
本文围绕用C语言挖掘公开富豪数据展开,先明确合规操作边界,再讲解数据请求、清洗、存储的核心技术路径,结合权威报告强调合规重要性,对比不同工具选型适配场景,给出断点续传、请求间隔控制等实战优化技巧,同时明确数据脱敏要求与合规自查机制,帮助从业者在合法范围内完成富豪公开数据的整合工作。
- Joshua Lee
- 2026-03-07

java如何聚集热词
本文围绕Java热词聚集展开,先介绍了其核心逻辑与应用价值,对比了主流分词框架的技术差异,梳理了企业级落地的全流程步骤,还结合行业案例拆解了实际应用场景,同时给出了热词优化与合规风控的关键要点,帮助开发者快速掌握Java热词聚集的实战方法,为企业业务决策提供数据支撑。
- Rhett Bai
- 2026-02-06

java如何挖掘数据
本文从技术选型、数据采集、清洗建模、成本优化四个维度,详解Java数据挖掘的全流程落地方案,结合行业权威数据对比不同工具适配场景,给出模块化复用与合规化处理的实战技巧,帮助企业提升数据挖掘效率与成本控制能力。
- Joshua Lee
- 2026-02-04

人工智能大数据如何挖掘
本文系统阐述人工智能大数据挖掘的全流程与落地要点,强调以数据治理和湖仓一体为基础,结合监督、无监督、深度学习与强化学习的混合建模,并通过特征工程与可解释性提升模型质量;在工程化层面,采用开源与云服务的混合平台建设MLOps闭环,以A/B测试与监控保障效果稳态;同时引入隐私合规、联邦学习与差分隐私构建负责任AI框架,最终以指标化评估将挖掘成果嵌入业务,实现可持续价值。
- Elara
- 2026-01-17

大模型如何做数据挖掘
本文阐明大模型做数据挖掘的实操路径:以嵌入为通用特征层,结合提示工程、RAG与参数高效微调三种策略,并通过工具调用把语义推理与SQL/算法执行连接起来;在工程侧,构建向量数据库与数据治理的稳定底座,建立评估与A/B闭环,强化合规与成本优化;针对分类、聚类、关联与异常等任务,采用“生成—验证”与“检索—规划—执行—自检”的组合范式,实现高一致性与可解释的业务落地,并面向多模态、可验证推理与联邦协作等趋势持续演进。
- Joshua Lee
- 2026-01-16

python如何对聚类的簇分析
Python聚类簇分析是将无标签数据集划分为相似特征簇群后,通过统计指标、可视化工具与领域规则验证有效性与商业价值的全流程操作,涵盖数据预处理、簇划分、质量评估、可视化分析、业务解读与优化等环节,可结合Scikit-learn等工具落地,借助PingCode提升跨团队协作效率,未来将朝着自动化解读与跨模态融合方向发展
- Elara
- 2026-01-14

如何用python找数据中的特征
本文介绍了使用Python挖掘数据特征的全流程方案,包括基于统计分析挖掘结构化数据特征、针对非结构化数据的专属特征提取方法、通过机器学习模型筛选高价值特征、落地验证特征有效性以及工具链整合提升效率等内容,结合KDnuggets 2023和Gartner 2024的权威调研数据与工具对比表格,提供了可落地的实践路径,并提及了跨团队协作工具和未来发展趋势。
- William Gu
- 2026-01-14

如何利用python进行数据挖掘
本文详细解析了Python数据挖掘的核心生态系统,结合权威行业报告阐述了从数据采集、清洗到建模优化与部署的全流程落地方法,介绍了Python数据挖掘的合规性风控要点与团队协作工具应用方式,对Python数据挖掘的未来发展趋势进行了预测。
- William Gu
- 2026-01-14

如何用python找高频词
这篇文章详细讲解了使用Python进行高频词提取的核心流程与实现方案,涵盖原生Python的基础实现、NLP专用库的进阶挖掘方法与企业级场景的落地策略,结合Gartner与Statista的权威数据验证Python生态的行业优势,并通过PingCode实现项目流程管理优化,同时介绍了高频词提取的去噪策略与避坑指南,最后预测了结合大语言模型的未来发展趋势。
- Joshua Lee
- 2026-01-14

python如何做数据聚类
这篇文章讲解了使用Python开展数据聚类项目的核心流程、主流算法选型、调优策略以及协作管理方法,结合Gartner和Forrester的行业报告验证了特征标准化、参数调优对聚类效果的重要性,同时提及可使用PingCode辅助跨团队聚类项目协作,介绍了Python数据聚类在电商用户分群、工业设备异常检测等场景的实际应用,并预测了大模型结合聚类算法和联邦聚类的未来发展趋势。
- Elara
- 2026-01-14

如何用python提取高频词
Python提取高频词的核心流程分为文本预处理、分词、停用词过滤、词频统计与可视化五步,结合nltk、spaCy等NLP工具可适配学术研究、媒体热点追踪等多元场景。通过定制语料库与加权统计策略可提升提取精准度,借助PingCode等工具可简化研发文档的高频词提取流程。未来Python高频词提取将向自动化、智能化方向发展,大模型将实现全流程自动处理并挖掘词汇语义关联。
- William Gu
- 2026-01-14

如何用python进行数据挖掘
本文详细阐述了使用Python进行数据挖掘的全过程,涵盖数据采集、预处理、特征工程、模型训练与评估、可视化和部署等环节,并对常用的Python工具库进行了功能对比。文章强调了数据质量对分析结果的重要性,并指出在企业应用中可以结合项目协作系统如PingCode实现数据与任务的联动管理。未来趋势包括云化、自动化、低代码以及更注重模型可解释性与隐私保护,帮助企业更高效地开展数据驱动决策。
- William Gu
- 2026-01-14

python中如何选取特征词
本文系统解析了在Python中选取特征词的多种方法,包括基于统计的TF、TF-IDF、卡方检验、互信息,以及基于模型的决策树、词向量分析、主题建模与Attention机制,并强调了分词、停用词去除等预处理的重要性。结合实际案例展示了如何用scikit-learn实现特征词排序。未来特征词选取将更多依托大语言模型与跨领域共享策略,并可能嵌入到研发项目管理平台实现端到端的数据驱动协作。
- Elara
- 2026-01-14

python如何统计频繁项集
本文系统回答了在Python中统计频繁项集的实践路径:依据业务与数据密度选择Apriori或FP-Growth,并在mlxtend、efficient-apriori、pyfpgrowth与PySpark FPGrowth四类工具中匹配场景;通过支持度、置信度与提升度联合筛选,配合数据清洗、采样与并行优化提升稳定性;在生产落地中引入监控、回滚与合规治理,并可在团队协作中借助PingCode记录参数与评审;未来将向分布式、隐私保护与可解释化方向演进。
- Joshua Lee
- 2026-01-13

如何用python进行聚类
本文系统讲解了用Python进行聚类的完整路径:先做标准化、编码与降维,再依据数据形态选择KMeans、DBSCAN、层次聚类或GMM,并用轮廓系数、Calinski-Harabasz与Davies-Bouldin联合评估;随后以scikit-learn示例代码展示从试参到可视化与持久化的流水线;最后覆盖生产化、协作与合规要点,并给出常见问题的排查与加速策略,帮助读者高效落地聚类方案。
- Joshua Lee
- 2026-01-13