
java连接数据库有哪几种方式
Java连接数据库主要包括JDBC直连、连接池方式、ORM框架方式、JNDI数据源方式以及响应式数据库连接方式。JDBC是基础接口但性能有限,连接池通过复用连接显著提升效率,ORM框架提升开发效率并成为企业级主流方案,JNDI适用于传统应用服务器环境,而响应式方式更适合高并发场景。实际选择应结合系统规模、性能需求和团队能力综合评估。
 William Gu
William Gu- 2026-04-14

java数据库连接池有哪几种
Java数据库连接池主要包括JDBC原生连接池、主流开源连接池(如HikariCP、DBCP、C3P0)、应用服务器内置连接池以及基于框架集成的连接池方案。不同类型在性能、管理方式和适用场景上存在差异。当前主流项目多采用HikariCP以满足高并发与低延迟需求,而传统企业系统则常使用服务器内置或DBCP方案。合理选择连接池有助于提升系统性能与稳定性。
- Joshua Lee
- 2026-04-14

java如何让返回值有两个选项
Java 方法只能返回一个值,但可以通过封装对象、record、数组或 Map 等结构实现逻辑上的多个返回结果。在实际开发中,自定义类或 record 是更规范、可维护性更强的方式,适用于业务系统接口设计;数组和 Map 适合简单或临时场景。合理封装数据结构,比单纯追求“两个返回值”更重要。随着 Java 版本演进,数据类表达能力增强,返回多个值将更加简洁高效。
- Rhett Bai
- 2026-04-14

监听器有哪几种及其作用Java
Java 监听器是基于事件驱动模型实现对象间解耦通信的重要机制,主要包括 AWT/Swing 监听器、Servlet 监听器、JavaBeans 监听器以及自定义监听器等类型。它们分别应用于桌面开发、Web 生命周期管理、组件通信和业务模块解耦,核心作用是监听状态变化并自动响应。随着架构演进,监听器机制正逐步扩展为事件驱动架构的重要基础,在企业级系统和分布式环境中发挥越来越关键的作用。
- William Gu
- 2026-04-14

java抽象类与类有什么区别
Java抽象类与普通类的核心区别在于是否可实例化、是否支持抽象方法以及在继承体系中的定位不同。抽象类用于定义规范与框架,不能直接创建对象,可包含抽象方法并强制子类实现;普通类用于提供完整功能实现,可以直接实例化。抽象类强调结构设计与扩展能力,普通类强调具体业务逻辑实现。合理区分二者,有助于构建清晰、可维护、可扩展的系统架构。
- Rhett Bai
- 2026-04-14

java客户端前端有什么开发工具
Java客户端前端开发工具主要包括传统桌面框架、现代桌面技术以及基于Web的前后端分离架构。Swing适用于维护旧系统,JavaFX适合现代桌面应用,Eclipse RCP适用于大型模块化系统,而Spring Boot结合Vue或React已成为企业级主流方案。随着Web技术和跨平台容器发展,Java客户端前端正向融合化和轻量化方向演进,企业应根据业务场景与团队能力选择合适工具。
- Rhett Bai
- 2026-04-14

java中的类可以有多个直接父类
Java类不支持多个直接父类,只能通过单继承扩展一个父类,这是为了避免菱形继承带来的歧义与复杂性。虽然不支持类多重继承,但Java允许实现多个接口,并通过接口默认方法和组合模式实现类似多继承的功能。单继承结构使类型体系更加清晰,虚方法调用路径更确定,也降低了维护难度。在实际开发中,应优先使用接口与组合,而非构建复杂的继承层级。随着架构演进,接口驱动与组合设计将成为主流趋势。
- Joshua Lee
- 2026-04-14
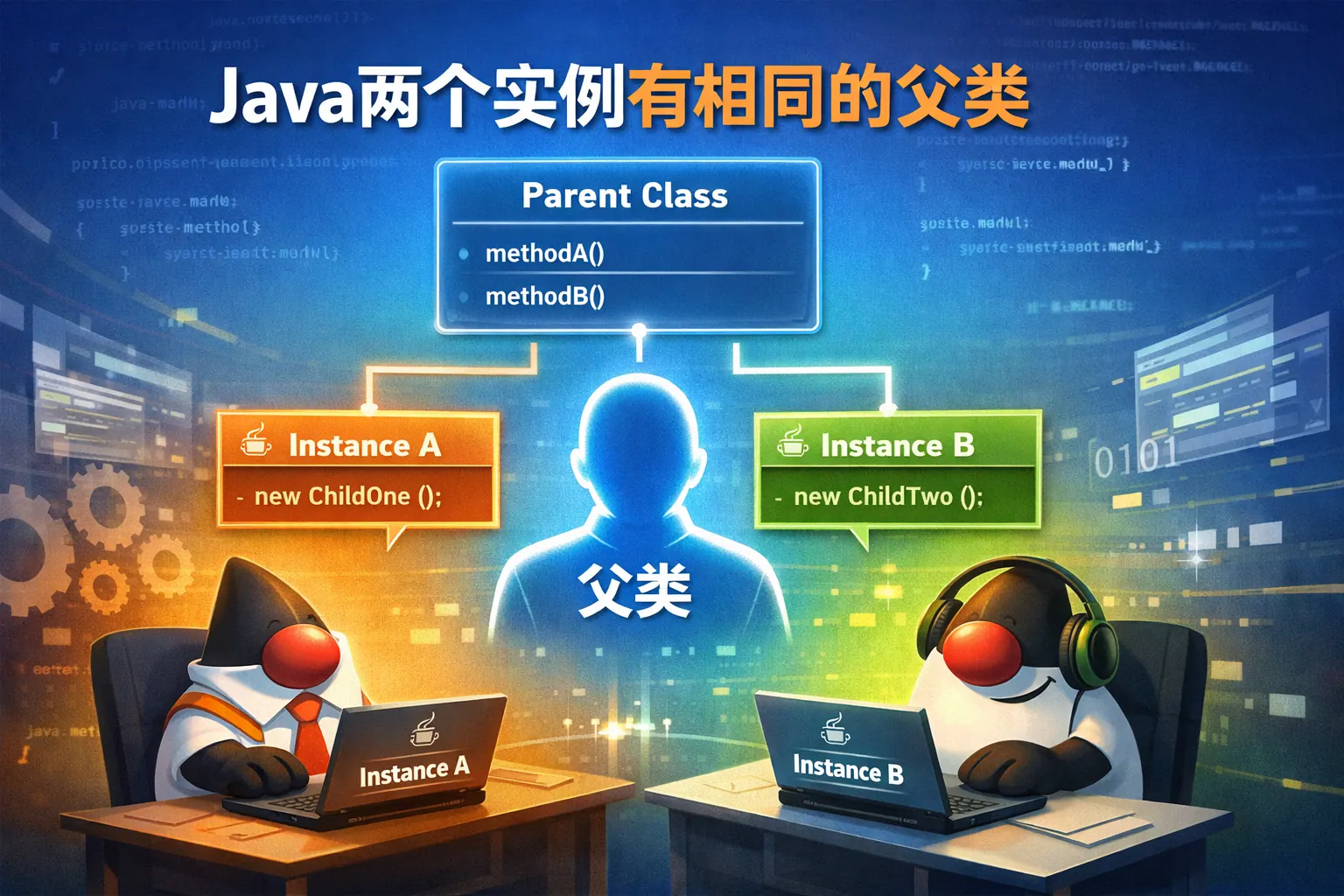
java两个实例有相同的父类
当两个实例拥有相同父类时,意味着它们共享统一的类型结构与行为定义,是Java继承与多态机制的体现。这种设计有助于代码复用、统一管理与扩展开发,但前提是父类抽象合理、符合里氏替换原则。合理运用继承可以提升系统可维护性,而过度继承则会增加耦合度。未来Java通过密封类等特性,使继承结构更加安全可控。理解相同父类的设计意义,是掌握面向对象架构能力的关键。
- Joshua Lee
- 2026-04-13

java的类加载器有以下哪几种
Java类加载器主要分为启动类加载器、平台类加载器、应用程序类加载器以及可扩展的自定义类加载器,它们通过层级结构和双亲委派机制协同完成类的加载与隔离。启动类加载核心库,平台类加载平台模块,应用程序类加载用户代码,自定义类加载器用于插件化与动态扩展。理解类加载器体系,有助于掌握JVM原理并解决类冲突等实际问题。
- Elara
- 2026-04-13

java连接数据库的方式有几种
Java连接数据库主要包括原生JDBC、基于连接池的DataSource方式、Spring JDBC封装、MyBatis半自动映射、JPA/Hibernate全自动ORM、JNDI容器管理模式以及响应式R2DBC等方式。不同方案在性能控制、开发效率和适用场景上存在明显差异。当前企业开发通常采用连接池结合ORM或MyBatis的模式,以兼顾性能与效率,而响应式连接方式代表未来高并发架构的发展方向。合理选择数据库连接技术,是构建高性能Java系统的关键。
- William Gu
- 2026-04-13

java的数据库连接池有哪些
Java常见数据库连接池包括HikariCP、Druid、Apache DBCP、C3P0和Tomcat JDBC Pool,其中HikariCP以高性能和低延迟著称,Druid强调监控与统计能力,DBCP和C3P0多见于老系统,Tomcat JDBC Pool适合容器环境。选型应结合并发规模、监控需求与系统架构,未来趋势是轻量化与可观测能力并重。
- Joshua Lee
- 2026-04-13

java第三方缓存技术有什么
Java第三方缓存技术主要包括本地缓存、分布式缓存和嵌入式集群缓存三大类,典型方案涵盖Caffeine、Ehcache、Redis、Memcached以及Hazelcast等。不同缓存技术在部署方式、扩展能力与一致性模型方面存在明显差异,本地缓存强调低延迟,分布式缓存强调共享与扩展。合理选择缓存方案并设计完善的缓存策略,是提升Java系统性能和稳定性的关键。未来缓存技术将更加云原生化与智能化。
- Elara
- 2026-04-13

java连接数据库的方式有哪些
Java连接数据库的方式包括原生JDBC、连接池技术、JNDI数据源、ORM框架、Spring数据访问抽象以及响应式数据库访问等。JDBC是基础标准,连接池提升性能,ORM和Spring框架提高开发效率,而响应式方式适用于高并发场景。企业级系统通常结合连接池与ORM框架使用,在性能、可维护性和开发效率之间取得平衡。未来发展趋势将更加注重高性能、声明式编程以及云原生架构适配。
- Rhett Bai
- 2026-04-13

JAVA自定义注解的成员有啥用
本文系统解释了 Java 自定义注解中“成员”的真实作用与工程价值,指出注解成员本质上是用于承载结构化元数据的配置接口,而非行为逻辑。通过分析语法层面、编译期处理、运行期反射以及架构设计中的实际应用,文章说明了成员如何让注解从简单标记升级为可表达规则与语义的工具。同时结合成员类型、默认值设计和使用场景对比,阐明了合理设计注解成员对可维护性和扩展性的影响,并对其在未来 Java 工程实践中的发展趋势进行了预测。
- William Gu
- 2026-04-13

JAVA8函数式编程有什么好处
Java8函数式编程通过引入Lambda表达式、Stream流和函数式接口等特性,显著提升了代码的可读性、表达能力与开发效率,同时增强了并行处理能力和系统稳定性。它减少样板代码,强化不可变性与纯函数思想,使代码更易测试与维护,并契合现代高并发与数据处理需求。虽然需要避免滥用复杂链式调用,但整体来看,函数式编程已成为Java生态的重要发展方向,对企业级开发具有长期价值。
- Rhett Bai
- 2026-04-13

java设计模式到底有什么用
Java设计模式的核心价值在于提升系统可维护性、扩展能力与代码结构质量。它通过抽象与解耦帮助开发者构建高内聚、低耦合的系统架构,在企业级项目中尤为重要。设计模式不仅优化代码实现,更提升架构思维与团队协作效率。合理应用模式能够降低长期维护成本,而滥用则会增加复杂度。随着软件系统不断演进,掌握设计模式已成为开发者向架构能力进阶的重要基础。
- Joshua Lee
- 2026-04-13

java解析xml有哪几种方法
Java解析XML主要包括DOM、SAX、StAX、JAXB以及第三方库等方式。DOM适合小型复杂结构文件,SAX和StAX适合大规模流式处理,JAXB适用于对象绑定场景,不同方法在内存占用、性能表现与开发复杂度上各有差异。实际选型应结合数据规模、性能要求与系统架构,同时注意安全配置与团队协作管理。未来趋势将更加注重流式处理能力与安全防护机制。
- Rhett Bai
- 2026-04-13

java的工程模式有什么用
Java工程模式的核心价值在于通过结构化设计降低系统耦合、提升扩展能力和可维护性,并为团队协作提供统一的设计语言。常见的创建型、结构型与行为型模式在实际项目中广泛应用,有助于系统长期稳定演进。但工程模式应按需使用,避免过度设计。随着架构复杂度提升,工程模式仍将是Java开发中的关键能力。
- William Gu
- 2026-04-13

在java中可以有多少个类
Java 中可以有多少个类并没有固定答案,因为语言规范本身未设定上限。真正决定类数量的因素是 JVM 的元空间大小、系统内存、类加载器管理机制以及运行环境资源。在实际工程中,数千到数万类都很常见,只要合理配置内存并优化架构设计,就能支持大量类的加载。因此,问题的关键不在于类的最大数量,而在于如何在资源允许范围内实现结构清晰、可维护的系统设计。
- Elara
- 2026-04-13

java项目前端服务器有几台
Java 项目前端服务器的数量没有统一标准,核心取决于业务访问量、并发峰值、可用性要求和架构模式。小型或内部系统通常 1 台即可运行,而面向公网的系统一般从 2 台起步,通过负载均衡避免单点故障。随着前后端分离、云化和自动伸缩的普及,前端服务器数量正从“固定规划”转向“动态调整”,合理的评估方法和持续监控,比单纯追求更多服务器更重要。
- William Gu
- 2026-04-13