
n个数 有多少三位数 java
文章系统讲解了“n个数能组成多少个三位数”的计算方法,核心在于区分是否允许重复以及是否包含0等条件。在不同约束下,可分别使用排列公式或乘法原理进行推导,如不允许重复时使用P(n,3)=n(n-1)(n-2),若包含0还需扣除首位为0的情况。实现方式上,Java可采用公式法实现高效计算,也可使用三重循环枚举所有结果。实际开发中应优先选择数学推导法以保证性能与准确性。掌握排列组合原理与代码实现,是算法能力的重要基础。
 Joshua Lee
Joshua Lee- 2026-04-14

判断二维数组是否有重复元素java
本文系统讲解了在 Java 中判断二维数组是否存在重复元素的多种实现思路,从基础的多层循环比较到利用 HashSet 提升性能,分析了不同方法在时间复杂度、空间消耗和适用场景上的差异。同时结合实际开发场景,强调了对象类型去重时 equals 与 hashCode 的重要性,并从工程实践角度讨论了性能与可维护性的平衡。整体而言,文章帮助读者在理解原理的基础上,选择更符合自身业务需求的二维数组重复元素判断方案。
- Elara
- 2026-04-14

判定两条线是否有交点java
本文系统讲解了在 Java 中判定两条线是否存在交点的问题,从线的类型区分入手,结合向量叉积与跨立实验原理,说明了线段相交的数学基础与工程实现方法。文章给出了完整的 Java 示例代码,并分析了共线、端点接触、数值精度等常见边界情况。同时结合实际应用场景,说明该判定在图形学、GIS 和路径规划中的重要性,并对未来几何算法工程化趋势进行了展望。
- Rhett Bai
- 2026-04-14

java四个数字有多少种组合
Java 中“四个数字有多少种组合”并没有固定答案,关键取决于是否允许数字重复、是否考虑顺序以及数字的取值范围。如果不重复且不考虑顺序,数量通常较少;不重复但考虑顺序时数量显著增加;允许重复且考虑顺序是最常见的业务模型;允许重复但不考虑顺序则多用于理论分析。只有先明确数学模型,再进行 Java 实现,才能避免逻辑错误并满足真实业务需求。
- William Gu
- 2026-04-14

java有向带权图的邻接表
本文系统讲解了 Java 中有向带权图的邻接表实现方式,核心观点是邻接表通过“顶点到出边集合”的映射,高效表达方向与权重信息,在稀疏图与工程场景中具备明显优势。文章从概念、数据结构设计、实现思路、复杂度对比及工程实践等方面展开,说明邻接表在空间利用、算法适配性和可扩展性上的价值,并结合权威资料论证其合理性,帮助读者在 Java 项目中正确、长期地使用这一结构。
- Rhett Bai
- 2026-04-13
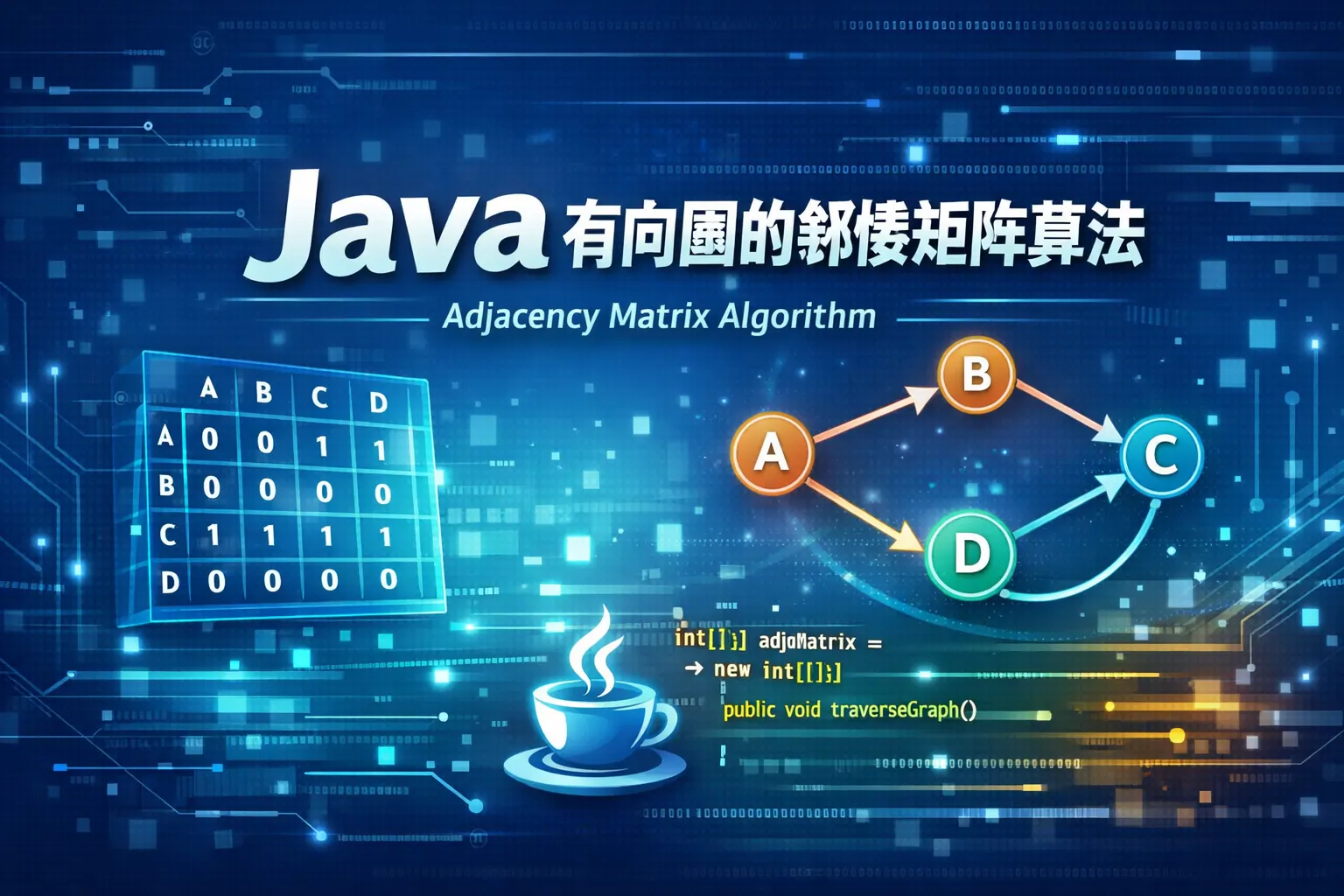
java有向图的邻接矩阵算法
本文系统讲解了 Java 中有向图邻接矩阵算法的原理与实现方式,指出邻接矩阵通过二维数组直观表达顶点间的方向关系,适合顶点数量明确、边关系频繁查询的有向图场景。文章从数据结构设计、矩阵构建、DFS 与 BFS 遍历、经典算法应用到工程实践进行了全面分析,并通过对比说明邻接矩阵与邻接表的适用边界。整体强调其实现稳定、逻辑清晰的特点,同时也客观分析了空间复杂度带来的限制与未来趋势。
- Joshua Lee
- 2026-04-13

查找是否有重复字符串 算法JAVA
本文系统讲解了在 Java 中查找是否存在重复字符串的核心思路,重点指出基于哈希结构的方法在性能与可维护性上的优势。通过对暴力遍历、HashSet、排序比较及 Map 计数等方案的分析与对比,明确了不同业务场景下的选择依据,并结合实现细节与工程实践,帮助读者在真实项目中高效、可靠地解决重复字符串问题。
- Joshua Lee
- 2026-04-13

java 有向图 邻接矩阵 邻接表
本文围绕 Java 语言中有向图的两种核心表示方式——邻接矩阵与邻接表,系统解析了它们的结构原理、实现思路与适用场景。文章指出,邻接矩阵以空间换时间,适合频繁判断边关系的稠密图;邻接表则以高空间效率和遍历性能见长,更适合大规模稀疏图与主流图算法。通过实现分析、性能对比与工程实践建议,帮助开发者在实际项目中根据访问模式和扩展需求做出理性选择。
- William Gu
- 2026-04-13

笼子里有两种动物Java计算
本文围绕“笼子里有两种动物”的经典问题,系统讲解了如何将现实描述抽象为数学模型,并通过 Java 程序进行计算求解。文章从问题背景入手,分析了二元一次方程在 Java 中的表达方式,对枚举法与代数解法进行了对比,并讨论了异常情况处理与模型扩展思路。通过这些内容,读者可以理解该问题背后的建模逻辑及其在教学与实际开发中的应用价值。
- Rhett Bai
- 2026-04-13

java中常用的排序算法有哪些
本文系统梳理了 Java 中常用的排序算法体系,从基础的冒泡、插入、选择排序,到工程实践中常用的快速排序、归并排序、堆排序,再到突破比较下界的计数、桶和基数排序,全面分析了它们的思想、复杂度与适用场景。文章同时结合 Java 标准库的排序实现策略,说明了不同数据类型背后的算法选择逻辑,并通过对比表帮助读者建立选型认知。整体强调:理解排序算法原理,是正确使用 Java 排序能力与进行性能优化的关键基础。
- Elara
- 2026-04-13

java有哪几种经典排序算法
本文系统梳理了 Java 中常见的经典排序算法,涵盖冒泡、选择、插入、希尔、归并、快速与堆排序等核心模型,从算法思想、时间与空间复杂度、稳定性及工程适用性等多个维度进行分析。通过对比可以看出,不同排序算法各有边界条件和优势场景,Java 开发中并不存在放之四海而皆准的选择。深入理解这些经典排序算法,有助于正确评估性能取舍、理解 JDK 内部实现,并为复杂业务场景下的算法决策提供坚实基础。
- William Gu
- 2026-04-13

java能够用到的算法有哪些
Java开发中可应用的算法种类丰富,包括排序、查找、递归分治、动态规划、图算法、字符串处理、加密算法与并发算法等。Java标准库内置了高性能实现,如TimSort、双轴快速排序和红黑树结构,同时支持哈希算法与并发工具类。掌握这些算法不仅能提升程序性能与系统稳定性,也有助于解决复杂业务问题。未来算法能力将与高并发和分布式架构深度结合,成为后端开发的重要基础能力。
- Elara
- 2026-04-13

java中的搜索算法有哪些
Java中的搜索算法包括顺序查找、二分查找、插值查找、斐波那契查找、哈希查找、二叉搜索树查找以及图搜索等类型。不同算法适用于不同数据结构与业务场景:无序数据适合顺序或哈希查找,有序数据适合二分查找,频繁动态更新适合平衡树结构,而复杂关系数据适合DFS或BFS。理解时间复杂度与数据结构特点,是正确选择搜索算法、提升系统性能与可扩展性的关键。随着数据规模扩大,搜索算法将与分布式与高并发架构深度结合发展。
- Elara
- 2026-04-13
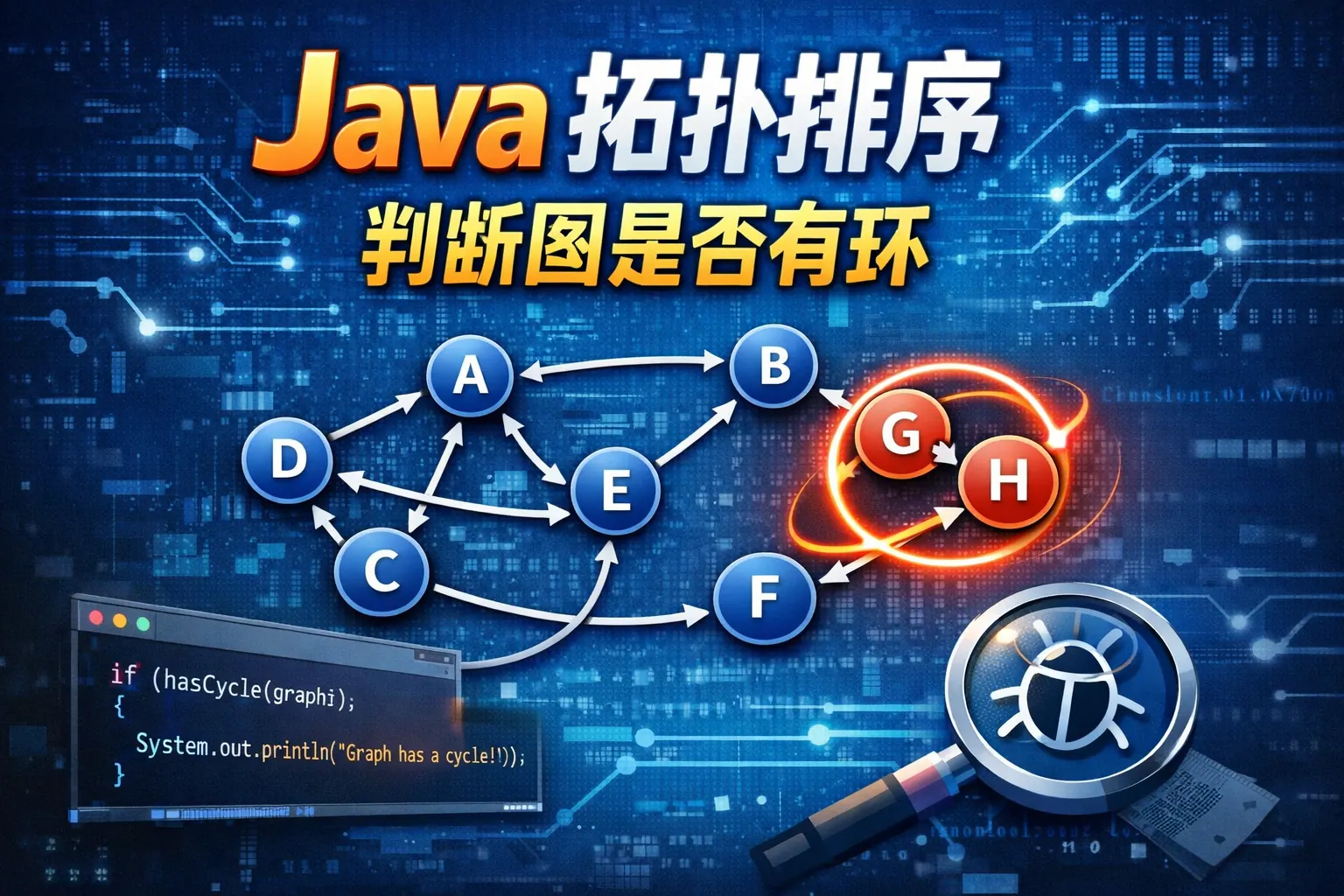
java 拓扑排序判断图是否有环
本文系统阐述了在 Java 中利用拓扑排序判断有向图是否存在环的原理与实现方式,核心结论是:若拓扑排序无法覆盖全部节点,则图中必然存在环。文章从拓扑排序的基本概念出发,深入分析了入度法与 DFS 判环两种常见思路,并结合工程实践讨论了它们在任务调度、依赖校验等场景中的应用价值。通过对比不同算法的适用条件与实现细节,强调理解图结构与依赖关系的重要性,为构建稳定、可维护的 Java 系统提供了方法论参考。
- Elara
- 2026-04-13

java数据结构简单算法有哪些
本文系统回答了“Java 数据结构简单算法有哪些”这一问题,核心观点是:简单算法并非低价值,而是构建 Java 编程能力的基础。文章从数组、链表、栈、队列、哈希表、排序与查找等多个角度,梳理了常见且高频的简单算法类型,并结合 Java 语言特性说明其实现意义与适用场景。通过对比分析可以看出,这些算法在性能理解、逻辑训练和工程实践中都具有长期价值,是进一步学习复杂算法与系统设计的关键前提。
- William Gu
- 2026-04-13

java冒泡排序法有什么用
Java 冒泡排序法的作用主要体现在学习和理解层面,而不是实际性能优势。它通过直观的比较和交换过程,帮助学习者掌握数组操作、循环控制和算法复杂度等核心概念。在真实开发中,冒泡排序很少作为通用方案使用,但在数据规模很小、数据近乎有序或需要高度可读性的场景下仍有一定价值。更重要的是,冒泡排序常被用于算法教学、面试考察和编程思维训练,是Java开发者建立算法认知体系的重要基础。
- Elara
- 2026-04-13

判断有向图是否存在环java
本文系统讲解了在 Java 中判断有向图是否存在环的核心思路与实现方式,重点分析了基于深度优先搜索和基于拓扑排序两种主流算法。文章从工程背景出发,说明有向图判环在任务依赖、流程调度中的重要性,并通过完整 Java 示例展示关键实现细节。通过对比分析两种方法的适用场景与优缺点,帮助读者在实际项目中做出合理选择,最终总结了有向图判环在复杂系统中的发展趋势与实践价值。
- Rhett Bai
- 2026-04-13

判断有向图是否有环的算法java
本文系统讲解了在 Java 中判断有向图是否存在环的核心算法与实现方式,重点分析了基于深度优先搜索和基于拓扑排序两种主流思路。通过原理说明、代码示例与工程对比,阐明了有向环在依赖建模中的实际意义,以及不同算法在稳定性和适用场景上的差异。文章指出,DFS 更适合快速检测与教学场景,而拓扑排序在工程系统中更具可扩展性,并对未来大规模依赖分析中的发展趋势进行了展望。
- William Gu
- 2026-04-13

java中排序有哪几种
本文系统梳理了 Java 中常见的排序方式,从比较排序与非比较排序的整体分类出发,深入解析了 Java 标准库在不同数据类型下采用的具体排序实现及其工程考量。通过对 TimSort、双轴快速排序等机制的对比,说明了稳定性、性能与适用场景之间的权衡关系,并结合 Comparable 与 Comparator 机制,帮助读者理解如何在真实项目中做出合理的排序选择。文章最后展望了 Java 排序在并行化与工程优化方向上的发展趋势。
- Elara
- 2026-04-13

java有向图的存储结构有什么
本文系统介绍了 Java 中有向图的主要存储结构,包括邻接矩阵、邻接表、逆邻接表、边集数组以及基于对象引用的面向对象结构。核心观点在于,不同存储方式在空间复杂度、查询效率和扩展能力方面差异明显,应结合图的规模、稀疏度与算法需求进行选择。文章通过原理解析与对比分析说明,邻接表是最通用方案,而在特定场景下组合使用多种结构,能够在性能与可维护性之间取得更优平衡。
- Elara
- 2026-04-13