
表示有T组测试数据java
在Java中表示有T组测试数据,核心做法是先读取整数T作为测试组数,然后通过循环结构逐组读取并处理每一组输入数据。开发者需要根据数据规模选择合适的输入方式,如Scanner适合小规模数据,BufferedReader更适合大数据场景,同时注意循环边界、变量初始化与IO优化问题。理解这种多组测试结构不仅有助于通过算法题,也有助于提升批量数据处理与程序结构设计能力。
 Elara
Elara- 2026-04-13

立扣上的代码如何运行
在立扣上运行代码主要依赖在线判题系统,用户通过选择语言、编写函数、点击运行或提交,由服务器编译并执行测试用例进行校验。理解运行机制、区分运行与提交、本地模拟执行方法,以及常见报错原因,是提高通过率的关键。同时需注意环境差异与算法复杂度问题。随着在线编程平台发展,代码运行正向智能化和云端化方向演进。
- Rhett Bai
- 2026-04-08

如何练习陀螺仪代码
练习陀螺仪代码应从理解MEMS陀螺仪原理开始,逐步完成数据读取、零偏校准、姿态解算与算法优化,并通过互补滤波等融合方法提高精度。在实际项目中结合可视化调试与模块化设计,才能真正掌握陀螺仪开发能力。随着传感器技术与算法融合发展,系统化练习路径将成为提升嵌入式与姿态控制能力的重要方式。
- Elara
- 2026-04-08

如何根据数据写代码建模
根据数据写代码建模的关键在于从问题定义出发,经过数据探索、预处理、特征工程、模型选择与评估优化,逐步构建可验证与可复现的算法模型。建模并非简单调用算法库,而是围绕数据结构和业务目标进行系统化设计。文章详细拆解完整流程,结合代码示例与模型对比,帮助读者掌握从数据到模型落地的实践方法,并指出未来自动化与工程化趋势。
- Rhett Bai
- 2026-04-07

如何调试在oj中的代码
在 OJ 中调试代码的核心在于理解评测机制、掌握常见错误类型并构建系统化排查流程。通过本地环境复现、设计边界测试用例、分析算法复杂度以及优化输入输出,可以有效定位 WA、TLE、RE 等问题。调试能力本质上是算法理解能力与测试思维的综合体现,未来随着题型复杂度提升,系统化调试与性能分析能力将更加重要。
- Elara
- 2026-04-03

如何在力扣网测试代码
在力扣网测试代码的关键在于理解在线判题机制,合理使用“运行”和“提交”功能,并主动构造边界测试用例以减少错误。无论使用网页版编辑器还是本地IDE调试,都需要关注时间复杂度、空间复杂度和输出格式要求。通过系统化训练和科学测试方法,可以显著提升代码通过率和算法能力。随着智能评测技术的发展,未来在线算法平台将更加智能化和高效化。
- Elara
- 2026-04-03

python训练过的模型再训练
本文系统回答了“Python 训练过的模型能否再训练”这一问题,核心结论是:在大多数场景下,模型不仅可以再训练,而且合理再训练往往比从零开始更高效。文章从概念区分、应用场景、技术路径与风险控制等角度,详细分析了继续训练、微调与增量学习的差异,并结合主流 Python 框架的实现方式说明了实践要点。同时指出,再训练并非万能,当数据分布或任务发生根本变化时,重新训练可能更优。整体强调了再训练在模型生命周期管理中的长期价值与未来趋势。
- Rhett Bai
- 2026-03-28

python推荐算法的实际应用
本文系统梳理了Python推荐算法在真实业务中的实际应用价值与落地方式,涵盖电商、内容平台、在线教育及企业内部系统等多个场景。文章指出,Python推荐算法的核心意义在于降低用户决策成本、提升业务效率,并通过协同过滤、内容推荐与混合模型实现差异化目标。同时也分析了工程化落地中的数据质量、性能与公平性挑战,并对未来推荐系统向可解释性与长期价值优化的发展趋势进行了展望。
- William Gu
- 2026-03-28

交换链表当中的元素python
本文系统讲解了在 Python 中交换链表元素的多种方法,包括交换节点值与交换节点指针两种核心思路,并详细解析了指定节点交换、两两交换以及按位置交换等经典问题。通过代码示例与复杂度分析,帮助读者理解链表结构本质与指针操作技巧,同时总结常见错误与优化建议,为算法学习与工程实践提供完整参考。
- Rhett Bai
- 2026-03-28

python怎么input图节点
在 Python 中输入图节点,核心是根据图的类型选择合适的数据结构,最常见且高效的方式是使用邻接表,通过 input() 或文件读取节点数与边信息构建图结构。对于稠密图可使用邻接矩阵,而在数据分析场景下可以借助图处理库实现更复杂的图操作。不同输入方式在空间复杂度、执行效率和扩展性方面存在差异,应根据具体规模与应用场景选择最优方案。
- Elara
- 2026-03-25

c语言如何定义一个无穷大的书
C语言并不存在真正的无限大数值,但可以通过标准库宏和浮点特殊值来表示“无穷大”。整数类型通常使用limits.h中的INT_MAX或LLONG_MAX作为逻辑最大值,浮点类型则可使用math.h中的INFINITY或HUGE_VAL。开发中应避免手写大常量,优先采用标准宏以确保可移植性与安全性,并注意整数溢出属于未定义行为。合理区分整数与浮点语义,是正确实现“无穷大”定义的关键。未来趋势是结合标准库与高精度计算库提升数值安全性。
- Joshua Lee
- 2026-03-23

c语言指针中 测试数据有多组如何做
在 C 语言指针题目中遇到测试数据有多组时,本质是通过循环结构让同一段指针处理逻辑重复执行。常见方式包括已知测试组数 T、以 EOF 作为结束条件以及使用特殊终止标志控制输入结束。核心在于将单组数据的指针操作封装进循环内部,并确保每组数据互不干扰。熟练掌握循环控制与指针结合的方法,是解决多组输入问题的关键能力。
- Joshua Lee
- 2026-03-23

c语言如何判断鞍点
这篇文章围绕C语言判断鞍点展开,先讲解鞍点的数学定义与编程适配要点,拆解标准化判断流程,对比基础实现与预处理优化方案的效率差异,结合权威报告数据介绍进阶优化技巧,同时梳理了数组越界、重复输出等常见错误的调试方法,还覆盖了动态数组与批量测试的多场景拓展实现,帮助开发者掌握严谨高效的鞍点判断逻辑与落地代码框架。
- Rhett Bai
- 2026-03-07

c语言如何求pi
本文讲解了C语言求解圆周率PI的主流算法,对比了级数展开、蒙特卡洛抽样和高精度库调用三种方案的性能差异,结合权威行业报告数据给出了入门教学和工业级项目的选型建议,并分享了跨平台适配的优化技巧与合规注意事项。
- Elara
- 2026-03-07

c语言如何输出素数
本文讲解了C语言输出素数的基础实现逻辑与进阶优化方案,对比了基础循环与埃拉托斯特尼筛法的性能差异,结合权威行业报告的数据支撑,介绍了跨平台适配、工业级落地和加密场景拓展等内容,帮助开发者搭建高效合规的素数输出程序,同时覆盖内存受限和大规模输出等不同场景的优化思路。
- William Gu
- 2026-03-07

如何用c语言求素数和
本文围绕C语言求素数和展开,先介绍了素数求和的核心逻辑与不同场景的需求差异,拆解了暴力枚举法、埃拉托斯特尼筛法、欧拉筛法三种主流实现方法,通过对比表格直观展示了三种算法的性能差异,指出埃拉托斯特尼筛法是综合性能最优的选择,还提供了企业级优化方案与跨平台适配技巧,帮助开发者根据场景选择合适的实现方案。
- Elara
- 2026-03-04

java如何查找最长的递增数列
本文从Java开发者实战视角出发,讲解了最长递增子序列的核心概念,拆解了动态规划和贪心加二分查找两种主流解法的原理与代码实现,通过对比表格呈现了二者的性能差异与适配场景,结合权威行业报告给出生产环境调优技巧和面试避坑指南,帮助开发者高效掌握这一高频算法考点并落地应用。
- Elara
- 2026-02-27

java如何实现协同过滤算法
这篇文章围绕Java实现协同过滤算法展开,介绍了协同过滤的两类核心实现路径及落地前提,对比了基于用户与基于物品的协同过滤的差异,讲解了Java开发协同过滤的技术选型,详细拆解了两种算法的代码实现全流程,结合权威行业报告给出了工程化改造、性能优化与合规风控方案,最后介绍了项目部署与效果验证方法,为企业级推荐系统落地提供了实战指南。
- William Gu
- 2026-02-27
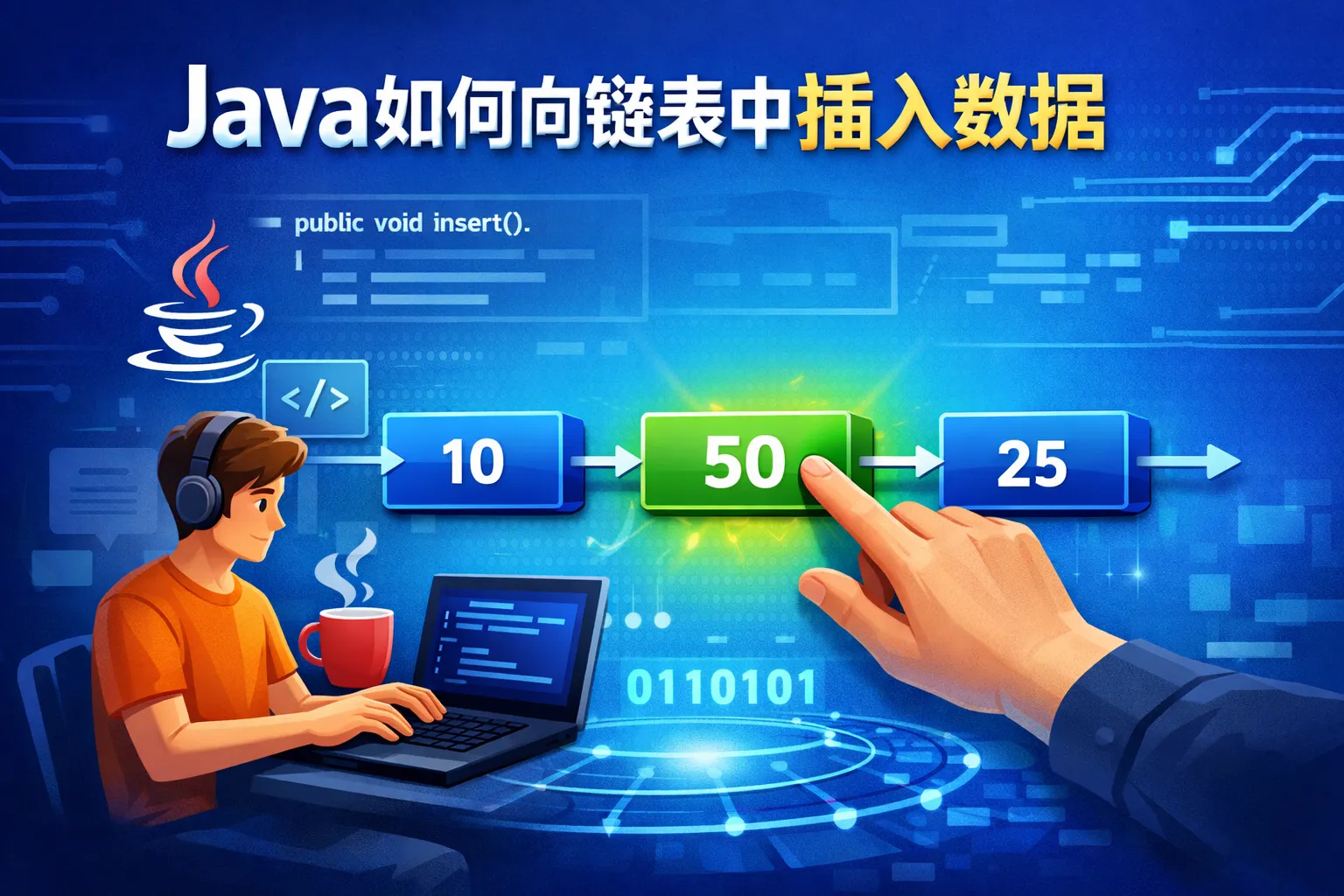
java如何向链表中插入数据
本文围绕Java链表插入数据展开,讲解了核心逻辑、三种主流实现方法、场景成本对比、优化技巧和避坑指南,结合权威报告数据和实战经验说明不同插入方法的适用场景与性能差异,帮助开发者提升Java链表插入的开发效率与系统性能。
- Rhett Bai
- 2026-02-27

java如何实排班表时间算法
本文围绕Java排班表时间算法展开,从核心设计逻辑、经典算法落地、多规则冲突处理、性能优化以及成本效率对比多个维度,详细拆解了算法的实现路径和实战技巧,结合权威行业报告数据对比不同算法的适配场景,帮助企业降低人力闲置率、规避合规风险,提升排班效率。
- Elara
- 2026-02-27