
java有N个非零且各不相同的整数
文章系统讲解了在 Java 中处理 N 个非零且各不相同整数的实现方法与优化思路,涵盖数据结构选择、时间复杂度分析、排序与统计应用、大规模数据优化策略以及异常处理设计。重点强调使用 HashSet 进行唯一性校验、通过负数计数判断乘积符号、避免整数溢出,并结合性能与内存消耗进行结构选型。内容兼顾算法实现与工程实践,适用于面试题与实际开发场景。
 William Gu
William Gu- 2026-04-14

java数轴x有两个点的序列A
在Java中处理数轴上两个点构成的序列,本质是解决一维有序数据结构的算法问题,核心方法包括合理的数据建模、排序预处理以及线性遍历优化。通过使用数组或自定义区间类封装数据,并结合排序算法,可以高效完成距离计算、区间合并与重叠判断等任务,时间复杂度通常可控制在O(n log n)。在工程实践中,还需关注边界校验、异常处理与性能优化,尤其是在大数据量场景下合理使用并行排序与内存优化策略,从而实现高性能与高可维护性的算法实现。
- Elara
- 2026-04-14

n中取m个数有多少种取法java
本文系统讲解了“n中取m个数有多少种取法”的数学原理与Java实现方式。组合问题本质为C(n,m)=n!/(m!(n-m)!),并对比了阶乘法、循环优化法、递归法、动态规划及BigInteger实现的优缺点与适用场景。文章结合算法复杂度分析与工程实践建议,帮助开发者根据数据规模选择合适的实现方式,提升组合数计算的效率与稳定性。
- William Gu
- 2026-04-14

JAVA有m总数n从中选用的数
本文系统讲解了在 Java 中从 m 个元素中选 n 个元素的实现方法,包括数学公式计算、递归回溯、位运算枚举与迭代生成等方式,并对不同算法的时间复杂度与适用场景进行了对比分析。文章强调在小规模数据下可直接枚举组合,而在大规模数据下应结合剪枝与并发优化策略,同时建议根据实际业务需求选择最合适的实现方案,以提升性能与可维护性。
- Elara
- 2026-04-13

Java判定字符串图中是否有环
Java 中判定字符串图是否存在环,关键在于将字符串关系抽象为有向或无向图,并选择合适的图论判环算法。只要完成字符串到图节点的映射,DFS 与拓扑排序等经典方法即可直接应用。DFS 判环因实现简单、对字符串友好,在工程中最为常见;拓扑排序则适合同时需要依赖顺序的场景。明确图的方向性、保证节点完整性,并避免常见实现误区,是确保字符串图判环准确性和稳定性的核心。
- William Gu
- 2026-04-13

Java有两根同样长的蜡烛
“两根同样长的蜡烛”问题本质是时间推理与逻辑建模题,核心在于利用双端燃烧压缩时间,而非依赖匀速计算。通过同时点燃一根蜡烛两端与另一根单端,可精确计时45分钟。这类问题考察抽象思维、约束处理与结构设计能力,强调通过改变系统结构实现目标,在编程与系统设计中具有重要启示意义。
- Rhett Bai
- 2026-04-13
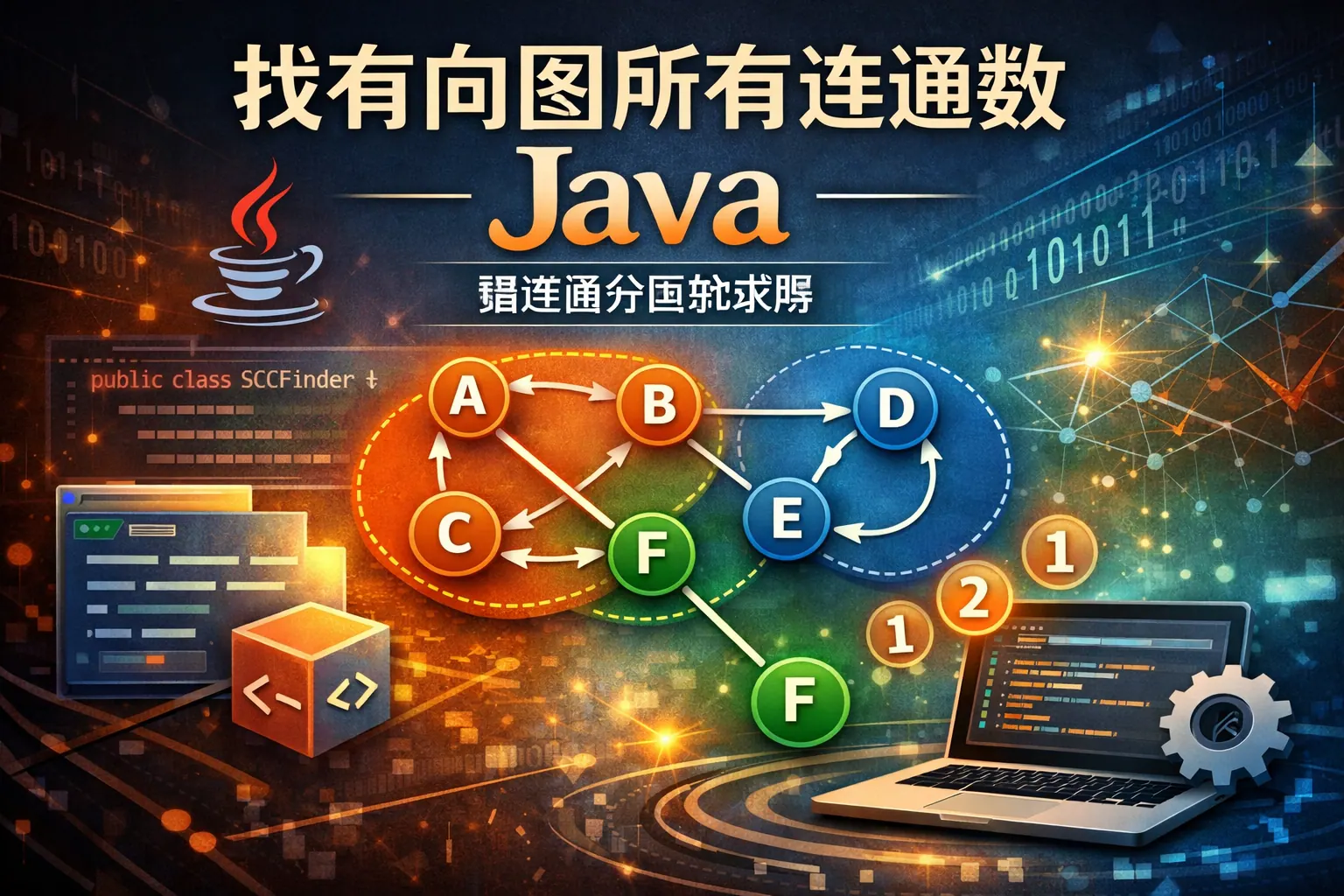
找有向图所有连通数java
本文系统讲解了在 Java 中查找有向图所有连通数的完整思路,明确区分了弱连通分量与强连通分量两种核心定义,并分析了各自的适用场景与工程意义。文章详细介绍了弱连通分量的 DFS/BFS 实现方式,以及强连通分量中 Kosaraju 和 Tarjan 两种经典算法的实现要点与取舍依据,同时通过对比表格帮助读者快速决策。最后结合 Java 工程实践,总结了常见误区与未来发展趋势,为实际项目中的图连通性分析提供了清晰、可落地的参考。
- Elara
- 2026-04-13

java判断两个矩形有重合区域
Java 判断两个矩形是否存在重合区域,本质是比较它们在 X 轴和 Y 轴方向上的区间是否同时相交。只要两个矩形在水平方向与垂直方向均存在交集,就说明存在重叠区域;若任意一个方向不相交,则一定不重合。常用实现方式包括自定义坐标比较公式或使用 Java 内置 Rectangle 类的 intersects 方法。在大规模场景中,可结合空间分区结构优化性能,并通过完善的边界条件处理与单元测试提升算法可靠性。掌握该方法是图形计算与碰撞检测的基础能力。
- Elara
- 2026-04-13

找有向图所有连通条数java
在 Java 中统计有向图连通条数,关键在于区分弱连通分量与强连通分量。弱连通可通过将有向边视为无向边后使用 DFS 或并查集实现,强连通则需借助 Tarjan 或 Kosaraju 算法,时间复杂度均为 O(V+E)。在实际开发中,应根据业务需求选择算法类型,并结合数据规模优化存储结构与遍历方式。掌握强连通与弱连通统计方法,有助于解决依赖分析、结构划分与系统架构优化等问题。
- Elara
- 2026-04-13

java排序算法到底有什么用
Java排序算法的意义远不止数据排列,它直接关系到系统性能、查找效率与用户体验,是数据处理与性能优化的基础能力。不同排序算法在时间复杂度、稳定性和空间消耗上存在显著差异,合理选择排序策略能够提升系统响应速度与扩展能力。在集合框架、大数据处理与并行计算场景中,排序算法都是关键技术基础。随着数据规模扩大,并行与自适应排序将成为重要发展方向。掌握排序算法,本质上是掌握高效数据处理能力。
- Joshua Lee
- 2026-04-13
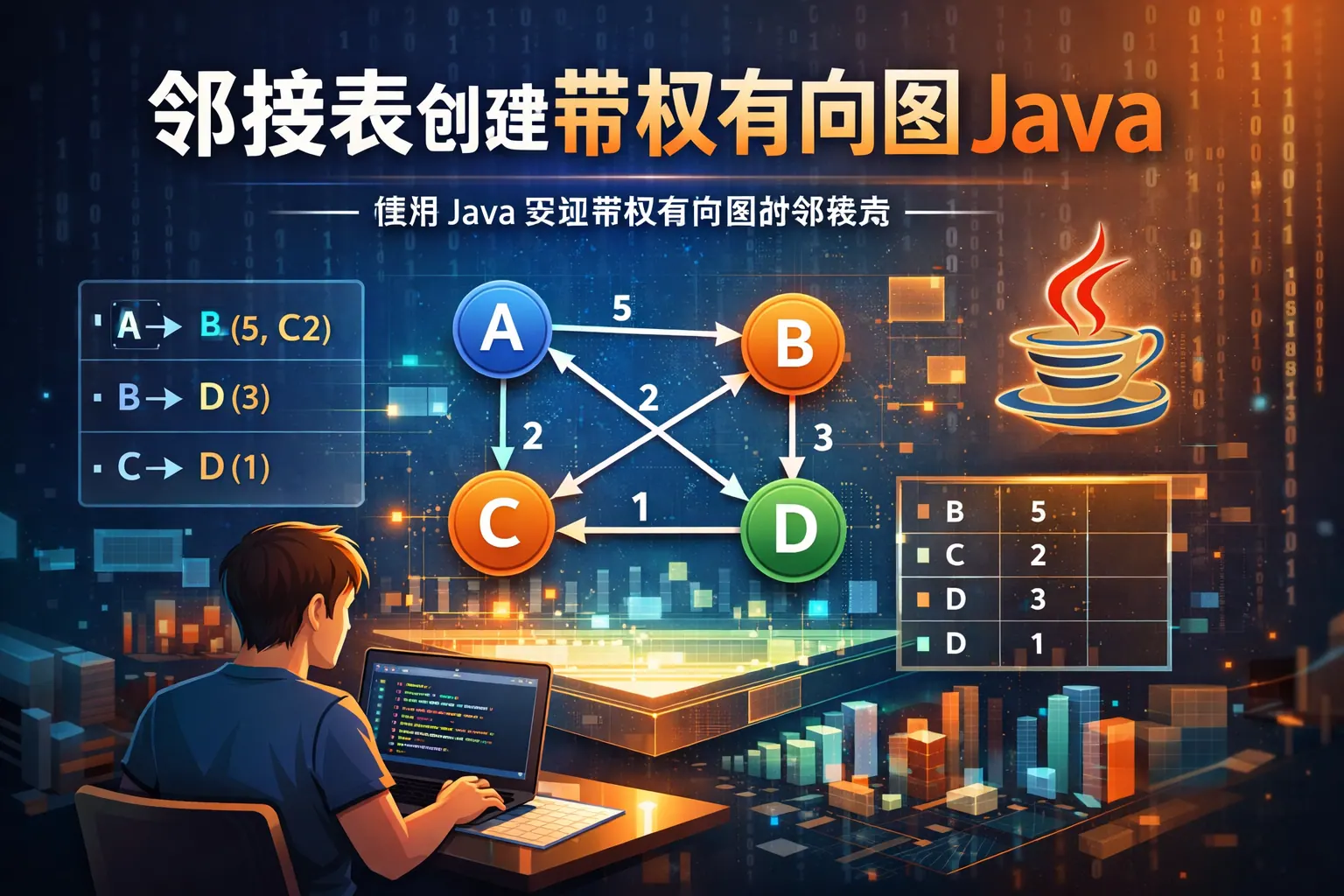
邻接表创建带权有向图java
本文系统讲解了在 Java 中使用邻接表创建带权有向图的方法,包括数据结构设计、完整代码示例、邻接表与邻接矩阵对比分析以及常见算法支持。文章重点说明了如何通过 Map 与 Edge 类构建高效的图结构,并结合工程实践介绍优化策略与常见问题排查方式,适合需要实现图算法或进行复杂关系建模的开发者参考。
- Elara
- 2026-04-13

java比较二进制是否有重复
本文系统讲解了在 Java 中判断二进制数据是否重复的多种方法,包括位运算、HashSet、BitSet、字节数组比较、SHA-256 哈希以及布隆过滤器等方案,并通过性能对比表分析不同方法的时间复杂度、空间消耗与适用场景。文章指出,小规模数据适合使用位运算或 HashSet,大规模整数推荐 BitSet,文件内容可通过哈希算法校验,而超大规模场景可采用布隆过滤器进行近似判重。最后结合工程实践与未来趋势,提出分布式与近似算法将成为主流方向。
- Joshua Lee
- 2026-04-13

Java建立两个链表升序有输入
本文系统讲解了如何在 Java 中建立两个升序链表并实现有序输入,涵盖节点结构定义、有序插入算法、双指针合并方法及性能分析。通过示例代码与对比表格,深入说明了不同构建方式的复杂度差异与适用场景,并结合权威资料解析链表在动态数据维护中的优势与局限,帮助开发者全面掌握升序链表的实现与优化思路。
- William Gu
- 2026-04-13

java查找有向图中所有的环
本文系统讲解了在 Java 中查找有向图所有环的核心思路,从环的定义与工程意义入手,分析了 DFS、强连通分量及 Johnson 算法在不同规模场景下的适用性。文章强调通过先缩小搜索空间再枚举环路,可以在保证结果完整性的同时有效控制性能开销,并结合 Java 实现细节讨论了内存与效率优化方向,为实际项目提供了可落地的技术参考。
- Elara
- 2026-04-13

java有重复数字的排列组合
本文系统讲解了Java中处理有重复数字的排列组合问题的实现思路与优化方法,重点介绍了排序加剪枝、Set去重以及基于计数的回溯三种方案,并对时间复杂度与性能进行了对比分析。文章通过代码示例说明排列与组合在去重逻辑上的差异,并结合复杂度理论与实践建议,帮助开发者在算法面试与工程开发中更高效地解决重复元素场景下的全排列与组合问题。最终强调剪枝策略与复杂度控制是核心能力。
- Elara
- 2026-04-13

Java中非分布式算法有哪些
Java中的非分布式算法是指运行在单机JVM环境中的算法体系,包括排序、查找、递归、分治、动态规划、图算法、字符串处理以及并发控制等类型。这类算法不涉及跨节点通信和一致性协调,核心关注时间复杂度与空间复杂度优化,是构建高性能Java应用的基础。理解其原理与适用场景,有助于提升系统运行效率并优化业务逻辑结构。
- Rhett Bai
- 2026-04-13

java有向图两个顶点可达
本文系统讲解了在 Java 中判断有向图两个顶点是否可达的核心思路与工程实现方式,从基本概念、图的数据结构表示入手,深入分析了 DFS、BFS 等常用算法在可达性判断中的适用场景与差异,并结合多次查询、强连通分量等高级策略探讨了性能优化方法。文章同时提醒了实际开发中的常见误区,并从系统设计角度展望了有向图可达性分析在复杂业务中的演进方向,帮助读者在算法理解与工程落地之间建立完整认知。
- Joshua Lee
- 2026-04-13

邻接表存储有向图的算法java
本文系统讲解了在 Java 中使用邻接表存储有向图的算法实现方式,重点说明其数据结构原理、Map 与数组两种实现形式、时间与空间复杂度分析,以及在 DFS、BFS 等图算法中的应用优势。通过对比邻接矩阵,指出邻接表更适合稀疏图场景,并结合工程实践给出优化建议与未来趋势判断,帮助开发者全面掌握有向图邻接表的实现思路与性能特征。
- Elara
- 2026-04-13

有向图连通分量的个数java
在 Java 中统计有向图连通分量个数,核心在于区分强连通分量与弱连通分量。强连通分量要求任意两点互相可达,常用 Tarjan 或 Kosaraju 算法实现,时间复杂度为 O(V+E);弱连通分量则忽略方向,可通过 DFS 或 BFS 统计。实际开发中更推荐 Tarjan 算法,效率高且适用于大规模图结构。根据业务需求选择算法,并注意性能与递归深度问题,是实现稳定图计算模块的关键。
- Joshua Lee
- 2026-04-13

判断数组中是否有重复元素Java
在 Java 中判断数组是否存在重复元素,可以通过 HashSet、排序后比较、HashMap 统计或 Stream API 实现。其中 HashSet 方法在时间复杂度 O(n) 和实现简洁性之间取得良好平衡,是常用方案;排序方法适合可修改原数组的场景;Map 适合统计频次需求;布尔数组适用于元素范围可控的大规模数据场景。开发时应根据数据规模、性能要求与内存限制选择合适策略。
- Elara
- 2026-04-13