
三大抽样分布表是数据库
三大抽样分布表并不是数据库,而是统计推断中的概率分布工具,包括正态分布表、t分布表和F分布表,用于查找临界值与进行假设检验。数据库则是用于存储和管理数据的信息系统,强调结构化管理与高效查询。两者在功能、学科属性与应用场景上存在本质区别,但在现代数据分析中形成协作关系:数据库提供数据来源,抽样分布提供推断依据。理解这种差异有助于构建清晰的统计与数据认知体系。
 William Gu
William Gu- 2026-04-09

python概率统计怎么使用
Python 概率统计的核心是借助 NumPy、SciPy、Pandas 与 Matplotlib 等科学计算库完成随机变量生成、概率分布建模、描述性统计、假设检验与蒙特卡洛模拟等任务。通过掌握常见分布函数、统计推断方法与数据可视化技巧,可以在科研、金融和商业分析中高效开展数据分析工作。未来,Python 概率统计将进一步与自动化建模和智能分析深度融合,成为数据时代的重要基础能力。
- Joshua Lee
- 2026-03-25

python怎么计算均值方差
Python 计算均值和方差可以通过 statistics、NumPy 和 pandas 等多种方式实现,其中 statistics 适合小规模数据,NumPy 在科学计算中性能最佳,pandas 则更适用于数据分析场景。不同方法默认计算的是样本方差还是总体方差,需要特别注意 ddof 参数设置。对于大规模或高精度需求场景,推荐使用优化过的数值计算库以保证效率和稳定性。掌握这些方法及其差异,有助于提升数据分析与建模的准确性与专业性。
- William Gu
- 2026-03-25

人工智能概率统计如何
本文系统阐释人工智能中概率统计的落地方法,核心在于用似然、后验与校准量化不确定性,并将其融入训练、评估与治理闭环;通过频率学派与贝叶斯互补,结合MCMC、变分推断与蒙特卡洛,在推荐、风控、医疗与A/B测试中实现可解释、可审计与稳健决策;配合国内外框架与云平台,以监测、漂移管理与风险阈值构建工程化最佳实践。
- Elara
- 2026-01-17

python中如何进行f检验
本文系统阐述了在Python中进行F检验的完整路径,包括使用SciPy执行单因素ANOVA与方差齐性检验、用Statsmodels进行回归框架下的整体与嵌套模型F检验,以及借助Scikit‑learn在特征选择中计算F统计量。文章强调先进行正态性与方差齐性检查,再选择经典或稳健方法(如Welch ANOVA),并在显著性结果之外同步报告效应量与多重比较。同时提供实用代码示例、库选择对比与结果报告规范,提醒常见误区与性能考量,并建议在团队与研发流程中整合版本控制与项目管理系统将统计检验留痕,提升复现与合规。
- Rhett Bai
- 2026-01-14

python如何做幂律分布
本文系统回答了在Python中进行幂律分布分析的完整方法:以最大似然估计与KS检验为核心,配合log-log可视化与CCDF稳健观察尾部,利用powerlaw库自动搜索xmin并进行似然比检验,与对数正态和指数等替代分布比较模型优劣;同时给出NumPy/SciPy与NetworkX的工程化实践、性能优化与协作建议,并通过网络度分布的案例展示了从数据清洗、参数拟合到结果解读的完整流程与常见陷阱的规避策略。
- Joshua Lee
- 2026-01-14

python如何查正态分布积分表
在Python中查正态分布积分表的高效方法是用库函数替代静态查表:通过scipy.stats.norm的cdf/ppf/sf/isf及其log变体即可完成概率查询与分位数反查,非标准正态只需指定均值与标准差。该方法精度高、可批量、可复现,在极端尾部使用sf/isf或log版本更稳定;受限环境可用mpmath或erf近似但需注明误差。工程实践中建议函数化封装、版本与参数记录,并将查询过程纳入协作与审计流程,可在研发项目中通过PingCode轻量集成以提升可追溯性。
- William Gu
- 2026-01-13

python如何做卡方检验
本文系统阐述在Python中进行卡方检验的完整路径,包括选择检验类型(适合度、独立性、齐性)、构建频数或交叉表、调用scipy.stats的chisquare与chi2_contingency、检查期望频数与独立性假设、解释χ²、自由度与p值,并用Cramér’s V补充效应量。通过Pandas完成数据清洗与表格生成,结合可视化与报告模板固化流程;当期望频数过低时建议使用精确检验或合并类别。文章还给出工程化与团队协作建议,在研发场景中可用PingCode沉淀统计方案与审计记录,提升复现性与合规性,并引用权威来源(SciPy, 2024;ASA, 2016)增强可信度。
- Elara
- 2026-01-13

python如何添加置信区间
本文系统阐述在Python中添加置信区间的路径:依据数据与假设选择参数法(SciPy/Statsmodels)、Bootstrap或贝叶斯可信区间,并用Matplotlib、Seaborn、Plotly进行可视化叠加。核心做法是明确指标类型与分布条件,计算点估计与标准误或重采样后取分位点,输出区间并在图形中呈现置信带或误差条;在工程化落地时需固定随机种子、记录方法元数据并进行覆盖率验证,团队协作可借助项目管理平台提升复用与合规性。
- Joshua Lee
- 2026-01-13

python如何进行卡方检验
本文系统说明了在Python中进行卡方检验的完整流程:根据问题类型选择拟合优度或独立性/同质性检验,使用SciPy的chisquare与chi2_contingency计算统计量与p值,并结合Cramér’s V效应量与标准化残差解释结果;通过Statsmodels开展功效分析与多重比较校正,在期望频数过小情形使用精确检验;以数据清洗、版本固定与协作管理提升工程化与合规性,必要时借助平台记录分析资产,形成可复审的闭环。
- Elara
- 2026-01-13

python 如何做方差分析
本文系统说明在Python中进行方差分析的完整流程:先明确实验设计与统计假设,使用SciPy与statsmodels完成单因素与双因素/交互建模,重复测量可借助Pingouin,并进行正态与方差齐性检验。随后依据显著性开展Tukey或Games-Howell事后检验,计算eta/omega等效应量,结合seaborn完成可视化与标准化报告。文章强调将ANOVA分析封装为可复现管线,并在项目协作系统中固化模板以提升合规与协作效率,体现Python生态在数据分析中的可持续优势。
- William Gu
- 2026-01-13

python集中量数如何计算
本文系统回答了“python集中量数如何计算”的问题:基于统计语义与分布假设,选择算术均值、中位数、众数、几何/调和均值、加权与截尾/温莎化均值,并用 Python 的 statistics、NumPy、Pandas 与 SciPy 进行实现,结合缺失值处理、分组与在线计算形成工程化方案。文章强调鲁棒统计在含异常与偏态数据中的价值,提供自助法置信区间与敏感性分析以确保稳健结论,并通过案例说明电商、金融与制造的选型逻辑;在团队层面,建议将口径、代码与验证流程沉淀到协作平台以确保可追溯与一致性。
- Rhett Bai
- 2026-01-13

python如何绘制正态分布图
本文系统阐述用Python绘制正态分布图的完整流程:以NumPy与SciPy生成或拟合参数,结合Matplotlib与Seaborn呈现PDF、CDF、直方图与KDE,并用QQ图与统计检验评估正态性;在Plotly中实现交互以支持演示与仪表盘;同时给出风格统一、高分辨率导出、资产化管理与团队协作的实践建议,并结合行业趋势强调将统计与可视化治理融入研发流程以提升决策效率与复盘价值。
- William Gu
- 2026-01-13
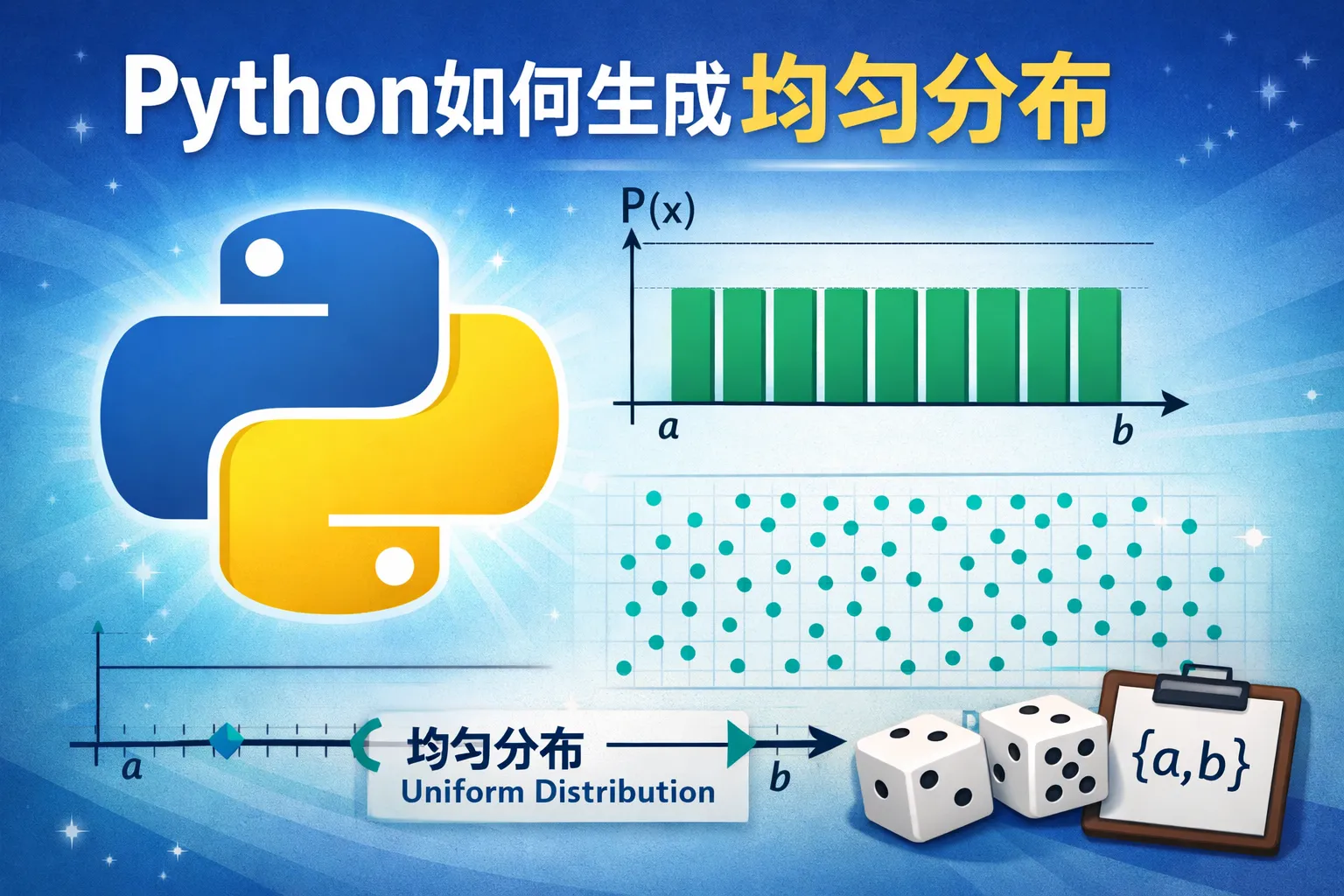
python如何生成均匀分布
本文系统回答了在Python中生成均匀分布的实现路径与工程要点:使用random或NumPy在[0,1)采样并线性映射到目标区间,离散场景用randrange/integers,安全需求选用secrets以避免偏差;批量与高维场景采用NumPy的Generator实现向量化与SeedSequence并行隔离;通过直方图与KS/卡方检验验证均匀性,注意区间端点、浮点精度与取模偏差;在工程落地中进行种子与版本化管理、并行种子隔离、结果审计与流程化协作,必要时将采样脚本与报告纳入项目管理平台以保障复现性与合规性。
- William Gu
- 2026-01-13

如何用python进行t检验
用Python做t检验的关键是先明确假设与数据结构,完成正态性与方差齐性等前提诊断,再在SciPy或Statsmodels中选择一元、独立或配对t检验并合理设置单尾/双尾与Welch修正。结果解释应结合p值、置信区间与效果量(如Cohen’s d),必要时做功效分析与多重比较校正,并以可视化增强可读性。在工程实践中,通过模块化管线、版本锁定与协作平台固化流程,可提升统计结论的可重复性与合规性。
- William Gu
- 2026-01-13

python如何生成标准正态分布
本文系统介绍了在Python中生成标准正态分布的可行路径:以NumPy的Generator.normal与SciPy的norm.rvs为通用方案,结合种子与SeedSequence实现可重复性;在GPU场景使用torch.randn或JAX的random.normal;通过直方图、QQ图与K-S、Shapiro-Wilk检验验证分布;在大规模任务中采用向量化、分块与内存控制并关注并行随机流隔离;利用线性变换、Cholesky与Box–Muller扩展到任意与多元正态;最后给出工程化落地、合规与未来趋势建议。===
- Joshua Lee
- 2026-01-13

如何利用python进行置换检验
本文以Python为工具详解置换检验的核心流程与常见场景,强调通过构造零假设下的可交换数据并反复置换生成经验分布来估计p值与显著性,涵盖两样本、配对、相关与回归模型标签置换的实操代码与优化策略。文章提出向量化、并行、JIT与蒙特卡洛近似等提速方法,给出结果可视化与多重比较校正的规范,并提示可交换性、数据泄露与置换次数不足等常见陷阱。结合ASA与scikit-learn的权威参考,给出在真实项目中融入协作与复现的建议,指出未来将向大规模近似置换、因果化设计与标准化报告演进。
- Elara
- 2026-01-12

如何用Python计算胜率
本文系统阐述了用Python计算胜率的完整方法论:以明确口径和时间窗为前提,用pandas/NumPy聚合出胜率点估计,并通过statsmodels或SciPy计算Wilson等置信区间与显著性检验;在分层、加权与时序平滑中控制混杂与波动,结合A/B或贝叶斯方法避免提前窥探与小样本偏差;同时以数据质量校验、指标元数据治理与自动化管道确保可复现与可审计,在跨团队协作中沉淀口径与变更记录,从而把胜率变成稳定、可决策的指标体系。
- Rhett Bai
- 2026-01-07

python如何生成列联表
本文系统阐述了用Python生成列联表的完整路径:以pandas的crosstab、pivot_table与groupby.size为核心构建交叉频数与比例,结合SciPy进行卡方与Fisher检验并用Cramer's V衡量效应量,再通过seaborn与statsmodels以热力图和马赛克图可视化解读。文章强调数据清洗、合理分箱与归一化方式对结果的影响,并给出高维与大规模场景下的性能优化建议,同时提供工具对比与协作落地思路,在研发与数据产品团队中可借助项目协作系统如PingCode沉淀分析流程与结论,提升复用与合规。
- William Gu
- 2026-01-07
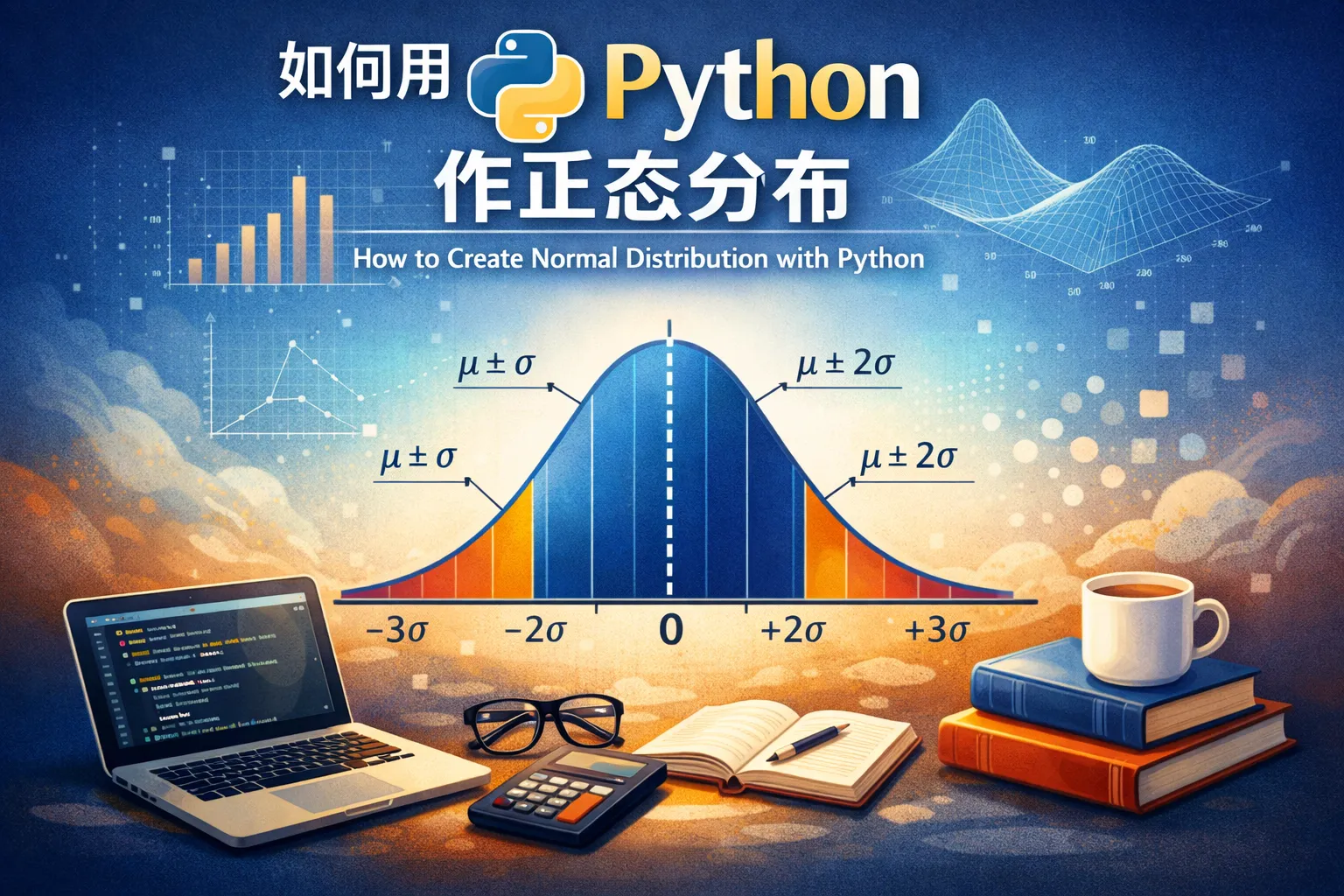
如何用python作正态分布
本文系统阐述用Python作正态分布的完整流程:先用NumPy生成样本并固定随机种子确保可复现;再用SciPy的norm对象进行概率密度、累积分布与分位点计算,并通过fit完成最大似然参数估计;随后结合Shapiro、D’Agostino、Anderson检验与Q-Q图综合判断正态性;在Matplotlib/Seaborn中绘制直方图与KDE并叠加理论曲线,直观评估拟合优劣;最后将脚本与报告纳入协作与治理,必要时可在研发项目管理中使用PingCode承载流程与文档。文章兼顾A/B测试、质量控制与风险评估等场景,并强调非正态数据的稳健策略与工程化落地。
- Elara
- 2026-01-07