
java分词器有什么用
Java分词器是将连续文本拆分为语义词语单元的基础工具,在搜索系统、数据分析、推荐系统和SEO优化中发挥关键作用。尤其在中文场景下,分词器决定了搜索匹配精度与语义理解效果。通过词典匹配、统计模型或深度学习等技术,Java分词器能够提升文本处理质量,并为企业构建智能化系统奠定基础。随着语义计算能力提升,分词技术将向更高层次的语义理解方向发展。
 William Gu
William Gu- 2026-04-13

java分词器有哪些
Java分词器包括IK Analyzer、HanLP、THULAC、Ansj、Jieba Java版本及Lucene分词器等。搜索场景更适合IK与Lucene体系,语义分析更适合HanLP与THULAC,轻量项目可选Ansj或Jieba。选型应结合性能需求、准确率与业务场景,通过实际语料测试验证效果,并关注未来向深度语义理解演进的趋势。
- Joshua Lee
- 2026-04-13

java 有哪些分词
Java 分词主要可以归纳为基于规则、基于词典、基于统计模型以及多策略混合四大类。它们在实现复杂度、分词精度、新词识别能力和性能消耗方面各有侧重,没有放之四海皆准的方案。实际项目中,Java 分词往往需要结合业务场景进行取舍,并与搜索、分析等上层系统协同设计。随着技术发展,分词正朝着智能化和服务化演进,但多种分词方式长期共存仍将是常态。
- Elara
- 2026-04-13

分词如何调用开源代码
调用开源分词代码的核心流程包括选择合适工具、安装依赖、阅读API文档、代码集成以及自定义优化。不同分词工具在算法原理、性能表现和适用场景上存在差异,开发者需结合业务需求进行选择。在实际应用中,可通过加载自定义词典、训练模型和优化部署方式提升分词效果。同时应关注开源协议与数据合规问题。未来分词技术将与语义理解深度融合,在搜索与文本分析领域持续发挥关键作用。
- Joshua Lee
- 2026-04-08

如何用python做分词代码
在 Python 中实现分词可以根据语言类型选择不同方法:英文分词可使用 split() 或正则表达式,中文分词通常借助 jieba 等分词库完成。实际应用中应根据业务需求选择合适的分词模式,并通过自定义词典和性能优化提升效果。分词广泛应用于数据分析、搜索优化与自然语言处理,是文本处理的基础能力。
- Elara
- 2026-04-08

如何通过代码拆解字根
通过代码拆解字根的关键在于构建结构数据库与可计算模型,并结合规则匹配、结构树解析或深度学习算法实现自动化分解。实现过程中需解决数据来源、结构歧义与性能优化问题,并通过分层架构提升系统扩展性。该技术在输入法优化、OCR增强和教育软件中具有广泛应用前景,未来将向智能化与知识图谱融合方向发展。
- Elara
- 2026-04-07

python训练词向量的详细过程
本文系统梳理了在 Python 中训练词向量的完整过程,从词向量的基本原理、主流模型类型,到语料准备、核心参数设定、训练流程与效果评估方法,全面解释了词向量如何通过上下文预测学习语义结构。文章强调语料质量与参数理解的重要性,分析了不同规模语料下的训练策略差异,并总结了常见误区与优化实践。最后结合行业趋势指出,尽管上下文动态表示不断发展,经典词向量在轻量化与工程实践中仍具有长期价值。
- William Gu
- 2026-03-29

制作词典的python自动标注
本文系统讲解了如何使用 Python 实现词典自动标注,从规则方法、统计模型到系统架构设计,完整覆盖数据准备、标注流程、评估优化与未来趋势。文章强调构建结构化数据体系与“规则+模型”结合的重要性,并通过实际案例说明自动标注在现代词典制作中的应用价值。最终指出,随着语义理解技术发展,词典自动标注将向智能化与深层语义分析方向演进。
- William Gu
- 2026-03-29

基于python的自动问答系统
基于Python的自动问答系统通过自然语言处理、语义检索与生成模型,实现对用户问题的自动理解与精准回答。文章系统梳理了自动问答系统的核心架构、技术路径、工具选型、算法流程与性能评估方法,对比规则式、检索式与生成式三种模式的优劣,并结合企业落地实践与未来趋势进行深入分析,指出检索增强生成将成为智能问答系统的主流发展方向。
- Elara
- 2026-03-29
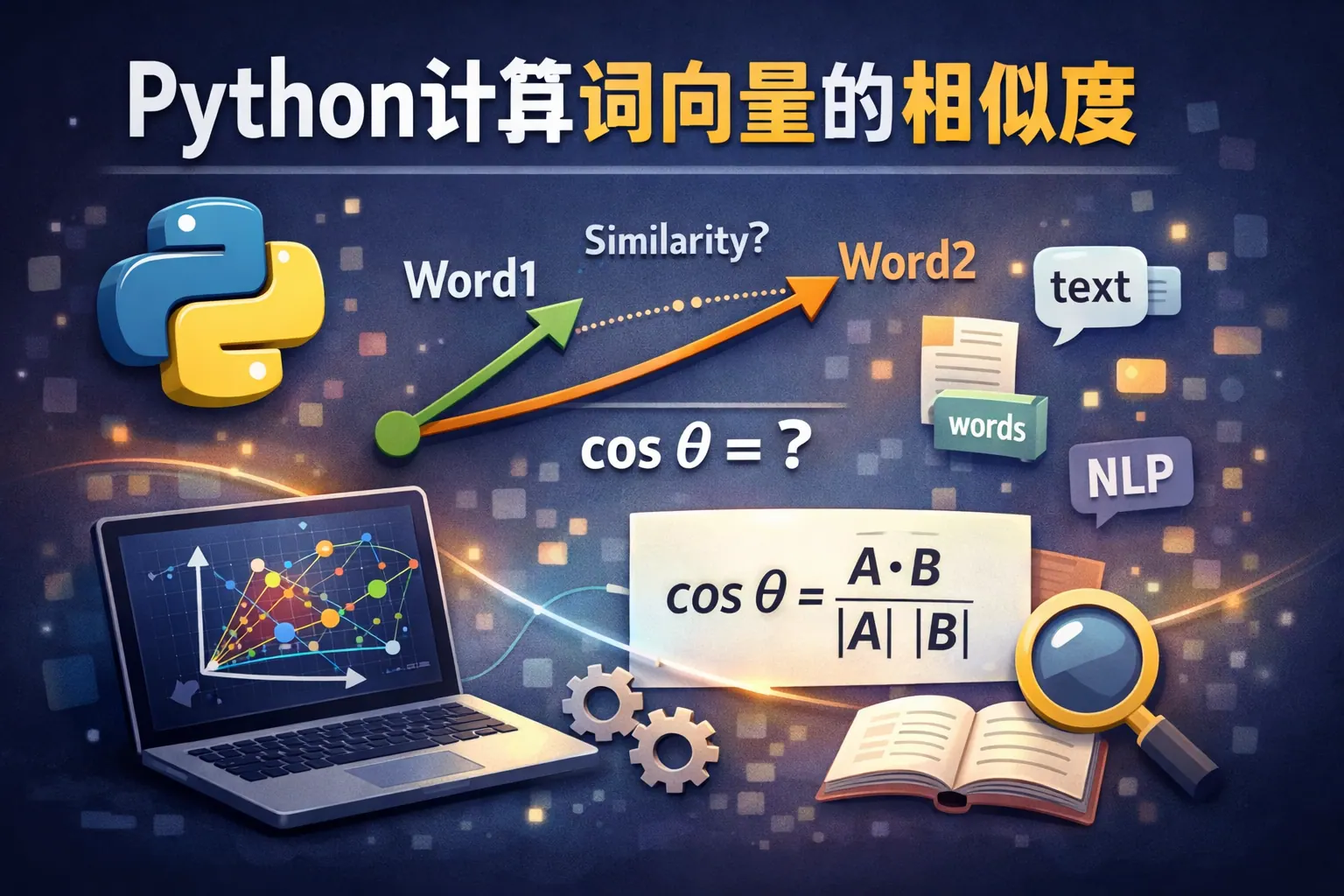
python计算词向量的相似度
本文系统讲解了在 Python 中计算词向量相似度的核心思路与实践方法,从词向量的基本概念出发,分析了常见模型与相似度算法,并结合 Gensim 与 scikit-learn 等工具说明具体实现路径。文章同时讨论了中文语境下的特殊问题、评估与优化策略,以及未来语义计算的发展趋势,帮助读者在真实应用中更准确、稳定地使用词向量相似度能力。
- Rhett Bai
- 2026-03-29

怎么去掉python中的停用词
Python去除停用词的核心方法是分词后结合停用词表进行过滤,常用工具包括NLTK、spaCy和scikit-learn,不同工具适用于教学、工业级应用或机器学习建模场景。中文处理需结合分词与自定义停用词表。是否删除停用词应根据任务类型决定,在深度学习和语义搜索场景中应谨慎处理,避免破坏语义结构。
- Joshua Lee
- 2026-03-28

python提供了常见的摘要算法
本文系统梳理了 Python 生态中常见的文本摘要算法,明确回答了“Python 是否以及如何提供摘要算法”这一问题。文章从抽取式与生成式两大范式出发,依次介绍了词频统计、TextRank、主题模型以及深度学习摘要在 Python 中的实现思路、优势与局限,并结合工程实践分析了不同算法在真实产品中的组合使用方式。整体来看,Python 凭借成熟的库生态与高开发效率,已成为摘要算法落地的主流选择,未来将在事实一致性与系统融合层面持续演进。
- Joshua Lee
- 2026-03-28

python基于词性标注的词频统计
本文系统阐述了 Python 环境下基于词性标注的词频统计方法,从概念定义、实际价值到常见工具与实现思路进行了全面分析。通过引入词性信息,词频统计能够有效过滤噪音词,突出承载语义的核心词汇,从而显著提升文本分析结果的可解释性与业务相关性。文章结合中英文处理场景,对不同统计策略、工具差异和数据清洗方法进行了对比,并指出该方法在主题分析、舆情监测和信息检索中的长期应用价值。
- William Gu
- 2026-03-28

python中创建停用词的程序
本文系统梳理了在 Python 中创建停用词程序的多种方法,从原生词表、第三方库支持到面向业务的自定义与统计自动生成方案,全面分析了各自的优劣与适用场景。文章强调,停用词并非简单的高频词删除,而是一种对文本信息密度的工程化管理手段。在实际项目中,通过多来源融合、模块化设计和持续迭代机制,Python 停用词程序能够显著提升文本处理、搜索与建模效果,并具备良好的长期维护价值。
- William Gu
- 2026-03-28

python 如何提取单词的词根
Python 提取单词词根主要有两种方式:词干提取和词形还原。词干提取基于规则裁剪后缀,速度快但语义准确度一般,适合搜索与信息检索;词形还原则依赖词典和词性分析,还原结果更准确,适合自然语言处理任务。常用工具包括 NLTK、WordNet 和 spaCy,选择时应根据数据规模、精度需求与性能要求综合判断。随着语言模型发展,词根提取的重要性有所变化,但在文本规范化和搜索系统中仍具有关键价值。
- William Gu
- 2026-03-28

python设置简单的问答系统
本文系统性介绍了如何使用 Python 构建一个简单的问答系统,从概念定义、整体架构到具体实现思路进行了完整梳理。文章指出,简单问答系统的核心在于可控性和可维护性,而非复杂语义理解,并重点分析了基于规则、关键词匹配与向量相似度的实现方式。通过架构拆解、对比表格和示例设计,说明了不同方案的适用场景与优化路径。最后结合应用场景与发展趋势,强调轻量级 Python 问答系统在特定领域内仍具长期价值。
- Elara
- 2026-03-28

哈工大ltp的python使用
本文系统介绍了哈工大 LTP 在 Python 环境下的使用方式与实践价值,核心观点是:LTP 通过统一而模块化的 Python 接口,为中文分词、词性标注、命名实体识别、依存句法和语义角色标注等任务提供了稳定且高效的解决方案。文章从项目背景、安装配置、接口设计到具体功能模块,全面分析了其在科研与工程场景中的优势与限制,并通过对比说明了 LTP 在中文 NLP 工具体系中的定位。整体来看,LTP 更适合作为系统级语言分析基础设施,在 Python 生态中具备长期使用价值。
- William Gu
- 2026-03-28
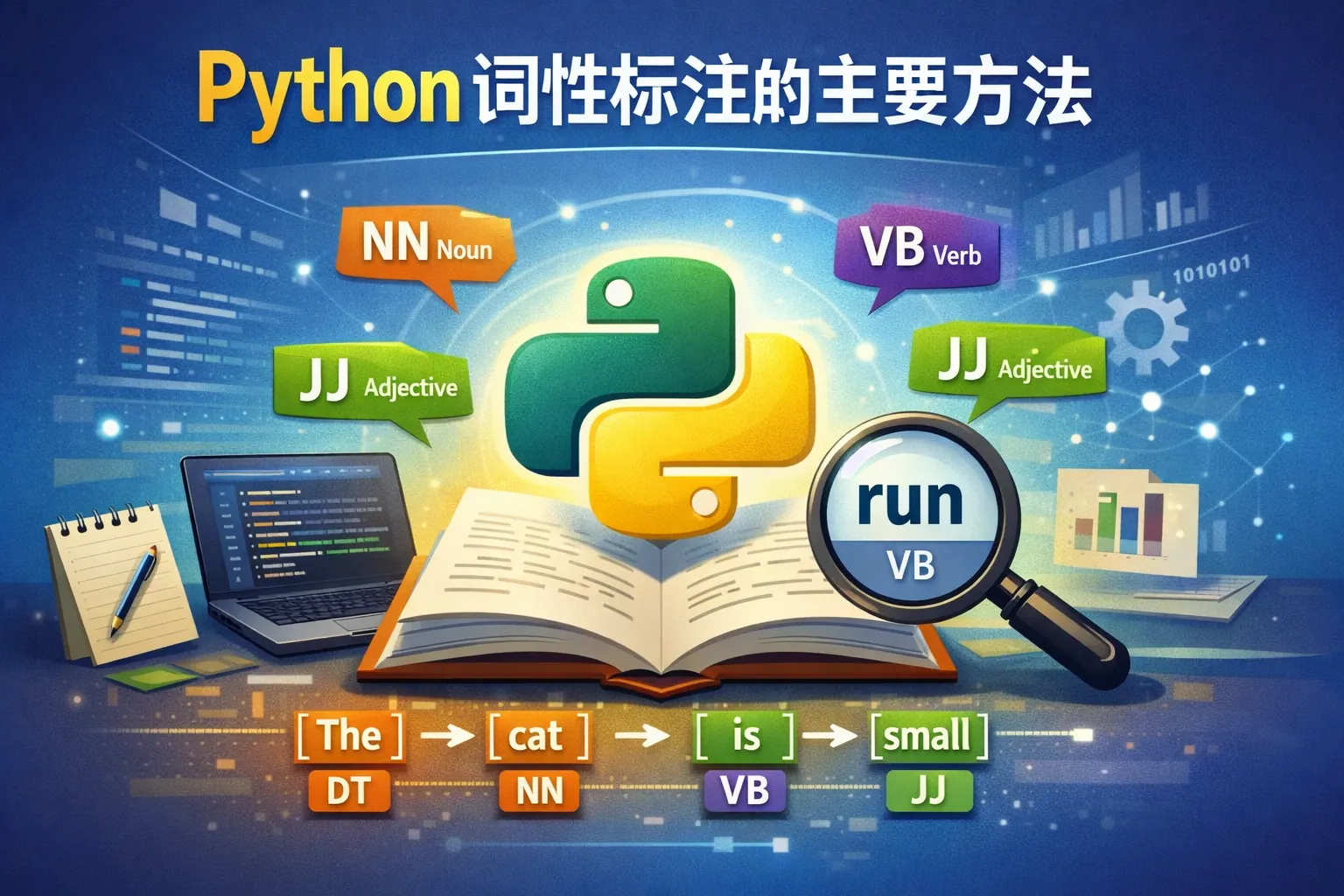
python词性标注的主要方法
文章系统梳理了 Python 词性标注的主要方法,指出当前技术体系主要包括规则方法、统计模型、CRF、深度学习以及预训练语言模型五大路线。通过对各方法原理、优缺点和适用场景的深入分析,可以看出深度学习和预训练模型在准确率和泛化能力上占据优势,而规则和统计方法在可解释性和资源受限场景中仍具价值。整体而言,Python 词性标注技术正朝着高精度、低标注成本和跨领域应用方向持续演进。
- William Gu
- 2026-03-28

python提取单词之间的信息
本文系统讲解了如何使用 Python 提取单词之间的信息,从字符级正则匹配到分词后的距离统计,再到基于自然语言处理的语义与句法关系分析。文章强调,不同层级的“单词之间的信息”对应不同技术手段,实际应用中应根据文本复杂度和业务目标进行选择。在搜索、内容分析和 SEO 场景下,合理利用词间关系有助于提升文本理解质量与相关性判断。未来,规则方法与轻量语义分析的结合将成为主流方向。
- Elara
- 2026-03-28

python基于统计的分词方法
本文系统介绍了 Python 环境下基于统计的中文分词方法,从词频与互信息等基础统计思想入手,逐步解析隐马尔可夫模型、条件随机场等经典概率模型在分词任务中的原理与实现逻辑。文章对比了不同统计分词范式在数据依赖、精度与工程成本上的差异,并结合实际文本场景分析其表现优劣。同时,探讨了统计分词与规则、词典融合的实践趋势,以及评估与持续优化的核心思路。整体来看,统计分词仍是中文自然语言处理的重要基础,其思想在未来模型演进中依然具有长期价值。
- Elara
- 2026-03-28