
java中需要强制类型转换的有哪些
Java 中只有在编译器无法确认类型安全时才需要强制类型转换,主要包括基本数据类型的缩小转换、引用类型的向下转型、接口还原为实现类、Object 类型恢复为具体类型以及泛型擦除后的类型处理。这些转换本质上是开发者对潜在风险的显式确认,使用不当容易引发运行期异常。合理的类型设计和约束可以显著减少强制类型转换的数量,从而提升代码的稳定性与可维护性。
 Joshua Lee
Joshua Lee- 2026-04-14

java标识符不合法的有哪些
Java 标识符不合法主要体现在数字开头、包含非法字符、使用关键字或字面量、以及作用域冲突等方面。这些问题在编译期即可暴露,本质源于 Java 语言规范对词法和语义的严格定义。虽然部分写法在语法上看似可行,但从工程实践和长期维护角度看仍存在风险。系统理解这些不合法情形,有助于减少低级错误,提升代码可读性,并为大型项目建立稳定的命名和信息架构基础。
- Elara
- 2026-04-14
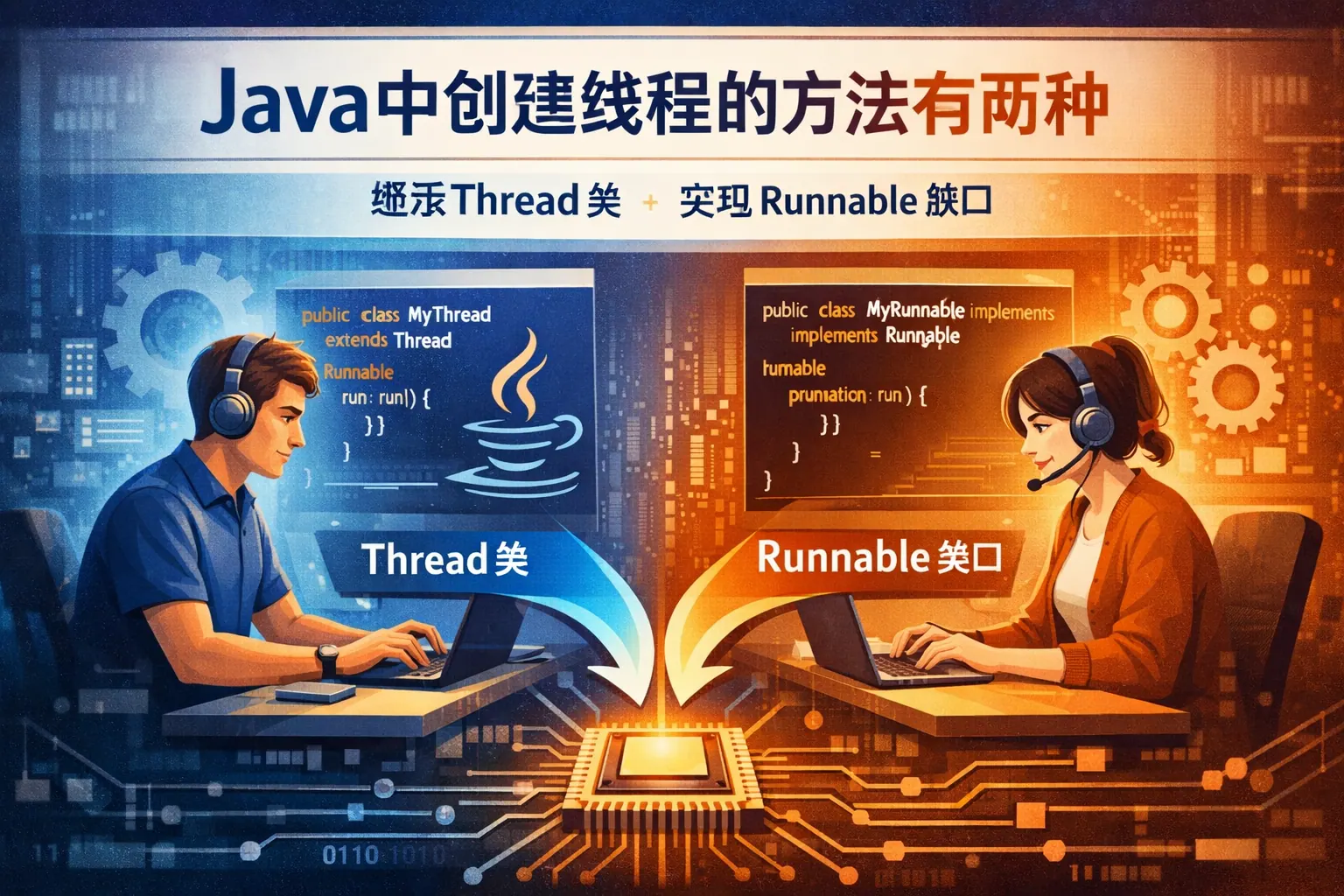
java中创建线程的方法有两种
Java 中创建线程主要有两种方式:继承 Thread 类和实现 Runnable 接口。前者将线程与任务耦合在一起,结构直观,适合初学者理解线程基本模型,但受单继承限制,扩展性较弱;后者通过任务与线程分离的设计,实现了更高的灵活性和复用性,更符合现代 Java 工程实践。从 JVM 角度看,两种方式在底层实现和性能上并无本质差异,真正影响系统表现的是线程管理策略。随着并发框架的发展,实现 Runnable 的思想已成为 Java 并发体系的重要基础,理解这两种方式对长期掌握并发编程仍具有核心价值。
- Elara
- 2026-04-14

在java中创建线程有两种方法
本文系统阐述了 Java 中创建线程的两种主要方法:继承 Thread 类与实现 Runnable 接口。文章从 Java 线程模型的设计背景出发,深入分析了两种方式在结构设计、执行机制和工程实践中的差异,指出继承 Thread 更适合理解原理和简单示例,而实现 Runnable 更符合面向对象设计原则,具备更高的复用性与扩展性。结合权威文档与实践经验,文章强调任务与线程解耦是 Java 并发发展的核心方向,并展望了以任务为中心的并发模型在未来 Java 开发中的长期价值。
- William Gu
- 2026-04-13

JAVA参数名可以有下划线么
Java 参数名在语法上是可以包含下划线的,只要符合 Java 标识符规则且不使用单独的“_”。这一点在 Java 语言规范中已有明确说明。但在实际开发中,主流 Java 命名规范更倾向于使用小驼峰命名,以保证代码一致性和可维护性。下划线参数名通常只在与外部系统字段映射或边界层适配时才有一定合理性。综合来看,理解其合法性并不等于推荐使用,遵循团队规范和社区共识,仍然是更稳妥的选择。
- Rhett Bai
- 2026-04-13

java子类调用父类的方法有哪些
本文系统梳理了 Java 中子类调用父类方法的主要方式,包括隐式继承调用、super 显式调用、构造方法中的父类调用以及静态方法的特殊处理规则。核心观点在于:是否能够以及如何调用父类方法,取决于继承关系、访问控制符和是否发生方法重写。理解这些机制,有助于正确运用多态、提升代码复用能力,并避免常见的设计与运行期问题。
- Elara
- 2026-04-13

java重写父类的有参构造
本文系统阐述了 Java 中子类无法重写父类有参构造的根本原因,指出构造方法不参与方法重写与多态机制,只能通过 super(参数) 显式调用父类构造完成初始化。文章结合语言规范、常见误区、构造规则对比及工程实践建议,帮助开发者正确理解继承体系中的构造调用逻辑,并强调清晰构造设计在长期维护中的重要性。
- William Gu
- 2026-04-13

java父类中有有参构造函数
本文系统解析了 Java 中父类只有有参构造函数时对子类产生的影响,明确指出子类必须显式调用 super(参数) 才能通过编译。文章从语言规范、编译错误成因、设计取舍和工程实践多个角度展开,说明该机制旨在保证对象初始化完整性与安全性。同时结合官方规范与行业共识,强调父类构造函数设计在大型项目中的重要性,并对未来 Java 构造函数设计趋势进行了展望。
- William Gu
- 2026-04-13

java对标识符有什么规定
Java 对标识符的规定主要体现在字符组成、关键字限制、大小写敏感性以及对 Unicode 的支持上,目的是确保语法严谨并兼顾国际化。只要标识符以合法字符开头、不与关键字或保留字冲突,就能被编译器正确识别。但在实际开发中,仅满足语法并不够,结合社区通行的命名规范,才能真正提升代码可读性和长期维护效率。
- Rhett Bai
- 2026-04-13

java的lang包有哪些类
java.lang 包是 Java 语言最核心的基础包,自动导入且贯穿所有 Java 程序运行全过程。它包含 Object、String、基本类型包装类、Thread、Throwable、Class、System 等关键类,分别支撑对象模型、字符串处理、数值体系、并发机制、异常处理与运行时管理。理解这些类的职责与设计取舍,有助于编写更稳定、高性能且易维护的 Java 代码。未来 java.lang 将继续保持高度稳定,作为 Java 平台长期演进的基础支点。
- William Gu
- 2026-04-13

java 变量名称可以有减号
Java 变量名称不能包含减号,这是由 Java 语言规范明确规定的。减号在 Java 中属于算术运算符,而非合法标识符字符,一旦出现在变量声明中就会被编译器解析为表达式,从而导致语法错误。与 JSON、CSS、URL 等允许使用减号的命名场景不同,Java 变量名必须遵循标识符规则,只能使用字母、数字、下划线和美元符号,并且不能以数字开头。实际开发中应使用驼峰命名法或下划线作为替代方式,这不仅符合语法要求,也有助于提升代码可读性和长期可维护性。
- William Gu
- 2026-04-13

java的标识类型有什么规定
Java 的标识符类型规定本质上是对类、方法、变量等命名规则的系统约束,既包括语法层面的合法性要求,也包含工程实践中的命名约定。标识符必须以字母、下划线或美元符号开头,不能与关键字、保留字或字面量冲突,并且区分大小写。在此基础上,Java 社区形成了类用大驼峰、方法和变量用小驼峰、常量全大写等通用规范。这些规定虽不全部由编译器强制执行,却在实际开发中极大提升了代码的可读性、协作效率和长期维护价值,是理解和掌握 Java 语言不可忽视的基础内容。
- Rhett Bai
- 2026-04-13

java的引用有哪几种
Java 引用并非只有一种形式,而是通过强引用、软引用、弱引用和虚引用四种模型,精细控制对象的生命周期与回收时机。强引用保障对象长期存活但易引发内存泄漏,软引用适合缓存场景,弱引用强调 GC 友好性,虚引用则用于回收通知与资源管理。理解这些引用类型,有助于在实际开发中平衡性能、稳定性与内存安全,是深入掌握 JVM 内存管理的关键基础。
- Elara
- 2026-04-13

java中构造方法有什么特点
构造方法是 Java 中用于对象初始化的特殊方法,其名称必须与类名一致且没有返回值,只能在对象创建时由 JVM 自动调用。它支持重载但不支持继承和重写,并通过访问修饰符、构造链和继承规则保障对象初始化的安全性与一致性。理解构造方法的特点,是掌握 Java 面向对象设计和编写高质量类结构的重要基础。
- Rhett Bai
- 2026-04-13

java表示不合法的有
Java 中“不合法的表示”主要指不符合语言规范的标识符、字面量或语法写法,尤其以标识符错误最为常见,例如以数字开头、包含非法字符、使用关键字作为名称等都会直接导致编译失败。此外,错误的数值、字符和字符串字面量同样属于不合法表示。需要注意的是,部分写法在语法上合法,但在工程规范中被视为不合理甚至禁止。理解这些规则,有助于减少编译错误、提升代码质量,并适应不同 Java 版本带来的规范变化。
- Rhett Bai
- 2026-04-13

java中构造器有什么
Java 构造器是对象创建时自动执行的初始化机制,用于保证实例在生命周期起点就具备合法且一致的状态。它与类同名、无返回值,支持重载但不能被继承或重写。Java 构造器既可以通过默认生成简化开发,也能通过访问控制与参数设计实现精细化的对象创建策略。合理使用 this 与 super 能确保初始化顺序清晰可控。在工程实践中,构造器不仅是语法结构,更是影响系统稳定性、可维护性和设计质量的重要基础。
- Rhett Bai
- 2026-04-13

java 定义同步方法有哪些
本文系统梳理了 Java 中定义同步方法的主要方式,包括实例同步方法、静态同步方法、同步代码块以及基于显式锁的等效实现,分析了它们在锁对象、作用范围和适用场景上的差异。文章结合 Java 内存模型说明了同步方法在可见性与互斥性上的作用,并给出了实际开发中的选择建议,帮助读者在并发安全与性能之间做出合理权衡。
- Elara
- 2026-04-13

java继承子类有哪些部分
Java 中子类并不会继承父类的全部内容,而是有明确边界。子类可以继承父类中非 private 的成员变量和实例方法,并在构造过程中通过 super 调用复用父类的初始化逻辑,但构造方法本身不会被继承。访问修饰符决定了继承的可见范围,静态成员和常量在语义上不属于真正的继承,也不支持多态。理解这些规则,有助于正确使用继承、避免设计误区,并为后续学习多态和系统架构设计打下坚实基础。
- Joshua Lee
- 2026-04-13

java的锁有哪些类
Java 提供了一整套层次分明的锁与并发控制类,用于解决多线程环境下的数据一致性与执行顺序问题。整体上可分为内置锁 synchronized、显式互斥锁如 ReentrantLock、读写锁如 ReentrantReadWriteLock,以及配合使用的 Condition 条件变量和原子类等并发工具。它们在可重入性、公平性、性能与使用复杂度上各有取舍,适用于不同并发场景。理解这些锁类的设计思想和适用边界,比单纯记忆类名更重要,也是编写高质量 Java 并发程序的基础。
- William Gu
- 2026-04-13

native方法java有哪些
Java 中的 native 方法是通过 JNI 调用本地代码的特殊方法,主要用于补足 Java 在系统级能力、性能和硬件访问方面的不足。它们广泛存在于 Object、System、Thread、Class 等核心类中,承担对象管理、线程调度、时间获取和类加载等关键职责。对大多数业务开发而言,native 方法是透明且无需直接使用的基础设施,但正是这些方法保证了 Java 在跨平台前提下依然具备高性能与稳定性。
- Joshua Lee
- 2026-04-13