在编程中,当一个字符串被转换为数字时,之所以会得到NaN(非数值)这个特殊结果,其根本原因在于该字符串的内容,无法被程序的解析引擎,依据既定的语法规则,成功地、无歧义地,解释为一个合法的数值。NaN是计算机浮点数算术标准中,一个用于表示“无效运算结果”的、特殊的“哨兵值”。它的出现,是一种明确的信号,旨在告知开发者,一次预期的数学转换或运算失败了。
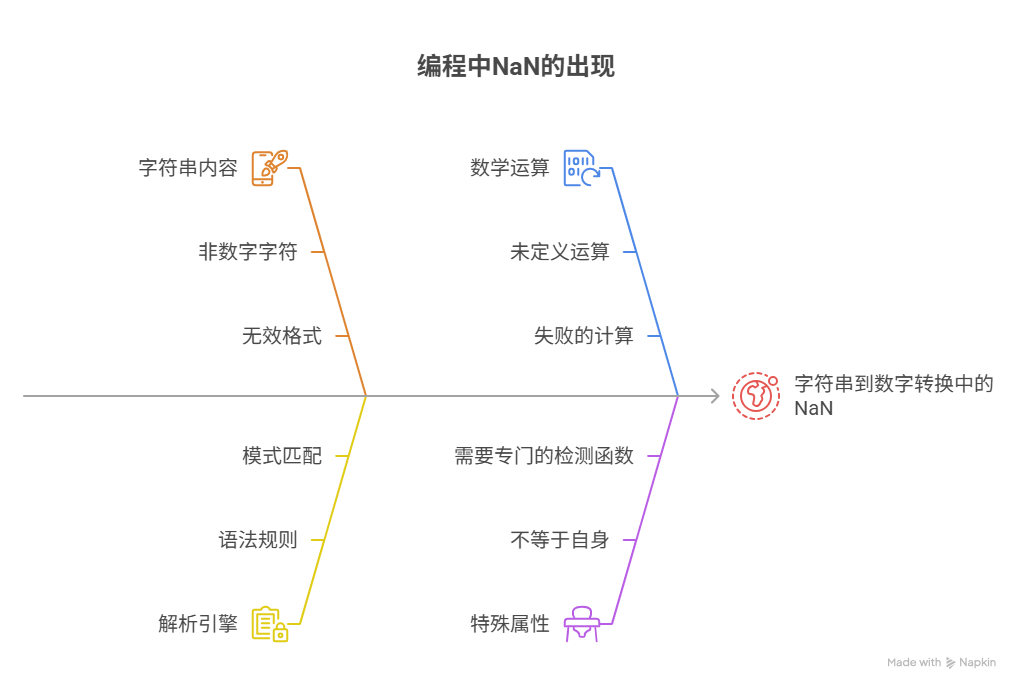

导致这种失败的常见场景涵盖:因为该字符串的“内容”无法被解析为一个合法的数字、它是数值标准中定义的特殊“非数字”值、用于表示一次“失败”的或“未定义”的数学运算结果、它具有“不等于自身”的独特性质、以及开发者必须使用专门的函数来检测它。例如,当程序试图将"你好"这样一个纯文本字符串转换为数字时,由于其中不包含任何有效的数字信息,解析引擎无法为其匹配任何一个数值形态,因此,只能返回NaN,以表示此次“转换”操作的失败。
一、NaN的“身份”:它到底是什么?
在深入探讨“为何”会产生NaN之前,我们必须首先,清晰地,理解NaN的“真实身份”。它并非一个传统意义上的“错误消息”,而是一个被国际标准所明确定义的、具有特殊属性的“数值”。
1. 一个特殊的“数字”
NaN,其字面意思是“非数值”(Not-a-Number)。然而,在许多编程语言(特别是JavaScript)中,一个最令人困惑、也最关键的知识点是,如果你去检测NaN的数据类型,你会发现,它本身,恰恰就是“数字”类型。
typeof NaN 在JavaScript中的结果是 'number'。
这个看似矛盾的设计,其背后的逻辑是:NaN,是在“数字运算”这个“域”内,所产生的一个结果。它代表的是一个“无法被表示为具体数字”的、数学上无效的状态。它仍然属于“数值”的范畴,就像“无穷大”也是数值概念的一部分一样。
2. 国际标准中的“哨兵”
NaN的“出身”,极其“高贵”。它并非某个编程语言的“私生子”,而是源于所有现代计算机硬件都必须遵守的、最底层的“IEEE 754 浮点数算术标准”。 在这个标准中,设计者们,预留出了一些特殊的二进制编码,用于表示一些“非正常”的数值状态。NaN就是其中最重要的一个“哨兵值”。它的主要职责,是用来表示那些**数学上“未定义”或“无实数解”**的运算结果。
例如,在数学中,0除以0,其结果是“未定义的”。在遵循IEEE 754标准的计算机中,0 / 0 的运算结果,就是NaN。
同样地,对一个负数,求其平方根(例如 Math.sqrt(-1)),在实数范围内,是无解的。其运算结果,也是NaN。
NaN的存在,使得这些无效的数学运算,不会直接导致整个程序的崩溃,而是会返回一个带有“污染”标记的特殊值。这个被“污染”的值,会在后续的计算中,持续地“传播”下去(任何与NaN进行的数学运算,其结果,依然是NaN),从而,为开发者,提供了一条可供追溯的“线索”。
二、“解析”的过程:计算机如何“阅读”字符串
现在,我们回到最初的问题:为何将一个字符串,转换为数字,会和0/0这类数学运算,产生关联呢?这是因为,“字符串到数字的转换”,在计算机内部,是一个被称为“解析”(Parsing)的、复杂的“翻译”过程。
1. 从“字符序列”到“数值”
对于人类而言,“123.45”这个字符串,和数字123.45,在意义上,几乎是等同的。但对于计算机而言,它们是两种完全不同的数据类型,其在内存中的存储方式,也截然不同。
字符串"123.45",是一系列字符编码(例如,'1', '2', '3', '.', '4', '5')的有序序列。
而数字123.45,则是一个遵循IEEE 754标准的、64位的二进制浮点数。
“解析”,就是由程序内置的“解析引擎”,去逐一地,读取字符串中的每一个字符,并尝试,依据一套严格的“语法规则”,来将其,重新构建为一个二进制的“数值”的过程。
2. 严格的“语法规则”
这个“解析引擎”,在工作时,就像一个极其严谨的、不懂变通的“语法警察”。它所能“看懂”的、合法的“数字字符串”,其语法规则,通常是:
可以有一个可选的、位于最前端的“正负号”(+ 或 -)。
其后,是一串连续的“数字”(0-9)。
中间,可以包含最多一个“小数点”(.)。
在科学记数法中,还可能包含一个e或E。
当,且仅当,一个字符串的全部内容,都严格地,符合这套语法规则时,解析,才能成功。
3. 失败的“时刻”
一旦解析引擎,在读取字符串的过程中,遇到了任何一个,不符合上述语法规则的“意外”字符,并且,它也无法,从当前的解析状态中,恢复过来,那么,这次“翻译”工作,就会被立即宣告“失败”。而为了向程序的其他部分,传递这个“失败”的信号,解析引擎,就会返回那个预先定义好的、代表“无效运算结果”的“哨兵值”—— NaN。
三、常见“元凶”:哪些字符串会“变身”NaN
基于上述的解析原理,我们可以系统性地,归纳出,哪些类型的字符串,在进行整体转换时,必然会“变身”为NaN。
1. 完全的非数字字符串 这是最显而易见的情况。当字符串中,不包含任何有效的数字信息时,解析必然失败。
Number("你好,世界") -> NaN
Number("abc") -> NaN
2. 以非数字字符开头的字符串 像Number()这样较为严格的转换函数,要求整个字符串,都必须是数值表示。
Number("a123") -> NaN
Number("$99.9") -> NaN (因为包含了货币符号)
3. 包含“混入”的非数字字符的字符串
Number("123a45") -> NaN (因为中间混入了字母a)
Number("1,000,000") -> NaN (因为包含了用于格式化的“千位分隔符”逗号)
4. 包含多个小数点的字符串 一个合法的数字,最多只能有一个小数点。
Number("12.34.56") -> NaN
一个特殊的“陷阱”:空字符串或纯空格字符串 值得注意的是,在JavaScript中,Number("")(空字符串)的转换结果,是 0,而非NaN。Number(" ")(纯空格字符串)的结果,同样是 0。这是语言规范中的一个特殊约定,也常常是导致一些“静默”的、难以排查的逻辑错误的根源。
四、NaN的“诡异”特性与处理
NaN,不仅其产生过程,需要被理解,其自身的“行为特性”,也同样充满了“陷阱”,特别是在“比较”运算中。
1. “不等于自身”的独特性质
在IEEE 754标准中,NaN,具有一个独一无二的、极其特殊的性质:它,不等于,任何值,包括它自己。
NaN == NaN -> false
NaN === NaN -> false
这个设计的背后,有一定的逻辑考量:因为NaN,是所有“无效运算”结果的集合。那么,“0/0”所导致的那个NaN,与“Math.sqrt(-1)”所导致的那个NaN,它们俩,在数学上,显然是不“相等”的。因此,标准,干脆就规定,任何NaN,都不与任何东西相等。
2. 为何 == 和 === 会“失效”?
这个“不等于自身”的特性,直接导致了,我们无法,使用常规的“相等”运算符,来判断一个变量,是否是NaN。
JavaScript
let result = Number("abc"); // 此时 result 的值是 NaN
if (result === NaN) { // 这个判断,将永远为假!
// 这里的代码,永远不会被执行
}
这是一个极其致命的、无数初学者都会掉入的“陷阱”。
3. 正确的“检测”方法
为了解决这个问题,编程语言,都提供了专门的、用于检测NaN的“官方”函数。
全局函数 isNaN():这是一个历史悠久的函数。但它有一个“缺陷”:它在进行判断前,会尝试,将传入的参数,强制地,转换为数字。这会导致一些“误判”。
isNaN("你好") -> true (因为"你好"被强制转换为数字时,得到NaN)
Number.isNaN():这是在现代JavaScript中,被强烈推荐的、更严谨、更可靠的方法。它,不会,进行任何类型转换。只有当传入的参数,其类型是“数字”,且其值,就是NaN时,它才会返回true。
Number.isNaN("你好") -> false
Number.isNaN(NaN) -> true
五、在实践中“防范”:建立健壮的转换机制
要系统性地,避免因NaN而导致的程序错误,我们必须在实践中,建立起一套“防御性”的、健壮的转换与校验机制。
第一原则:永远不要“信任”外部输入。所有来自用户输入框、外部接口、数据库查询结果的字符串,在被用于数学运算之前,都必须被视为是“不可信的”、“有毒的”。
第二原则:采用“先转换,后校验”的安全模式。JavaScript// 一个健壮的、推荐的实践范例 function calculateTotal(priceStr, quantityStr) { // 1. 显式地,进行类型转换 const price = Number(priceStr); const quantity = Number(quantityStr); // 2. 严格地,进行NaN校验 if (Number.isNaN(price) || Number.isNaN(quantity)) { // 3. 如果校验失败,立即中止,并返回一个明确的错误 throw new Error("输入参数无效,价格和数量必须是合法的数字。"); } // 4. 只有在校验通过后,才继续执行核心的业务逻辑 return price * quantity; }
第三原则:将规范“文档化”与“工具化”。团队的编码规范中,必须有专门的章节,来规定“如何安全地,进行字符串到数字的转换”。这份规范,可以被沉淀在像 Worktile 或 PingCode 的知识库中。同时,可以通过配置静态代码分析工具,来自动地,检查出那些使用了“不安全”的、全局isNaN函数的代码。
常见问答 (FAQ)
Q1: NaN 和 null 以及 undefined 有什么区别?
A1: NaN(非数值),是一个特殊的“数字”,用于表示无效的数学运算结果。null(空值),通常,是由开发者,主动地,赋予一个变量的,用以明确表示“此处应无值”的意图。而**undefined(未定义),则通常表示一个变量已被声明,但从未被赋予任何值**的“默认”状态。
Q2: 为什么 typeof NaN 的结果是 'number'?
A2: 因为NaN,是在“数字”这个数据类型的“域”内,被定义的一个特殊值。它本身,是数值计算失败后的一种“数值”状态表示,所以,其类型,被归类为number。
Q3: parseInt("100px") 的结果是100,为什么 Number("100px") 的结果是 NaN?
A3: 这是因为两者解析规则的“严格程度”不同。parseInt 更“宽容”,它会从字符串的开头开始解析,直到遇到第一个非数字字符为止。而 Number() 函数则更“严格”,它要求整个字符串,都必须是一个合法的数字表示,否则,就会返回NaN。
Q4: 除了字符串转换,还有哪些操作也可能会产生NaN?
A4: 任何数学上“未定义”的运算,都会产生NaN。最常见的,还包括:0 / 0(零除以零)、Math.sqrt(-1)(对负数求平方根)、以及**Infinity - Infinity**(无穷大减去无穷大)等。
文章包含AI辅助创作,作者:mayue,如若转载,请注明出处:https://docs.pingcode.com/baike/5214567
