程序在处理少量数据时运行如飞,一旦数据量激增,性能便急剧下降甚至崩溃,这一现象的根源,在于程序内部的“处理成本”与“数据规模”之间,形成了一种“非线性”的增长关系。一个设计欠佳的程序,其处理成本的增长速度,可能远超数据量的增长速度。导致这种性能瓶颈的五大核心“元凶”通常包括:算法的时间复杂度过高、不合适的数据结构选择、内存的频繁分配与垃圾回收、磁盘或网络输入输出的瓶颈、以及数据库查询的低效。
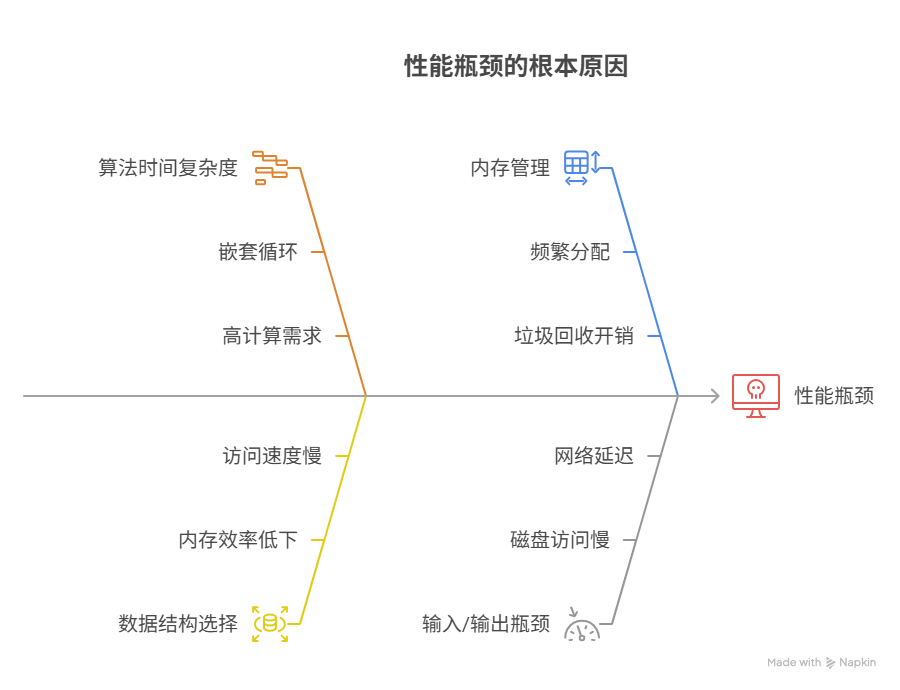

其中,算法的时间复杂度过高,是最根本、也最具决定性的因素。例如,一个采用了“嵌套循环”来进行数据匹配的算法,其计算量,会随着数据量N的增长,而成N的平方(N²)级别增长。当N从100增加到10000时(数据量增加100倍),其计算量,将从1万次,暴增到1亿次(计算量增加10000倍),性能的急剧下降,便不可避免。
一、问题的本质:从“线性增长”到“指数爆炸”
要理解性能为何会“急剧”下降,我们必须首先,在脑中,建立一个关于“成本增长”的数学模型。程序的性能,并非一个非黑即白的“快”或“慢”的状态,而是一条描述“处理时间(或资源消耗)”随“输入数据规模”变化的“增长曲线”。
1. 算法复杂度的“标尺”
在计算机科学中,我们使用“大O表示法”来描述这条曲线的“增长趋势”,即算法的时间复杂度。
理想状态 O(1) – 常数时间:无论处理10条数据,还是1000万条数据,程序的执行时间,都基本保持不变。这是最理想的性能。
优秀状态 O(log n) – 对数时间:执行时间,随着数据规模的对数增长。即使数据量翻倍,执行时间的增长也微乎其微。例如,在有序数组中进行二分查找。
良好状态 O(n) – 线性时间:执行时间,与数据规模,成正比增长。数据量增加10倍,耗时也大致增加10倍。这是大多数简单操作的、可接受的性能表现。
危险状态 O(n²) – 平方时间:这是导致性能“急剧下降”的、最常见的“罪魁祸首”。执行时间,与数据规模的平方,成正比。数据量增加10倍,耗时将暴增至100倍。
灾难状态 O(2ⁿ) – 指数时间:执行时间,随着数据规模,呈指数级爆炸。这类算法,通常只适用于处理极小规模的数据。
2. 性能“拐点”的出现
一个O(n²)的算法,在处理n=10这样的小数据量时,其计算量可能只有100次,速度飞快,与O(n)算法的10次计算,在体感上,几乎没有差别。这使得,这类性能问题,在开发和单元测试阶段,极易被“忽略”。 然而,当程序被部署到生产环境,开始处理n=100,000的真实数据时,O(n²)算法的计算量,将飙升至100亿次,而O(n)算法,则只有10万次。两者之间的性能差异,将是天壤之别。这个从“感觉很快”到“慢到卡死”的突变点,就是性能的“拐点”。
正如计算机科学巨匠高德纳(Donald Knuth)所言:“过早的优化是万恶之源。” 但他后面还有半句话常被忽略:“然而,我们不应错过那关键3%的机会。” 这提醒我们,虽然不应在所有代码上都过度追求性能,但对于那些处于“核心路径”的、需要处理大量数据的代码,对其复杂度的预先分析和优化,是至关重要的、必不可少的“关键机会”。
二、元凶一:算法的“时间复杂度”
这是最根本的、也是决定性能上限的内在因素。
1. “嵌套循环”的陷阱
一个嵌套了两层的、且内外两层循环的次数,都与数据规模N相关的循环,其时间复杂度,天然地,就是O(n²)。
场景示例:在一个包含N个用户的列表中,找出所有“同名”的用户对。Java// 一个时间复杂度为 O(n²) 的低效实现 for (int i = 0; i < userList.size(); i++) { for (int j = i + 1; j < userList.size(); j++) { if (userList.get(i).getName().equals(userList.get(j).getName())) { System.out.println("发现同名用户: " + userList.get(i).getName()); } } }
解决方案:改变算法思路,常常可以用“空间”换“时间”。我们可以使用一个“哈希表”(一种特殊的数据结构),来将这个问题的复杂度,从O(n²),优化到O(n)。Java// 一个时间复杂度为 O(n) 的高效实现 Map<String, Integer> nameCounts = new HashMap<>(); for (User user : userList) { String name = user.getName(); nameCounts.put(name, nameCounts.getOrDefault(name, 0) + 1); } // ... 再遍历一次哈希表,找出计数大于1的名字
2. 低效的“查找”与“排序”
在处理数据时,不恰当地,使用了一些“教科书”级别的、但性能低下的基础算法。例如,在一个巨大的、未排序的列表中,反复地进行“线性查找”(其复杂度为O(n))。
三、元凶二:数据结构的“错配”
算法的性能,与其操作的“数据结构”,是紧密耦合、互为表里的。选择一个与操作场景“不匹配”的数据结构,同样会引发性能灾难。
场景:高频的“成员资格”检查
问题:你需要反复地,检查某个用户ID,是否存在于一个包含了100万个“黑名单”ID的列表中。
低效的结构(列表):如果你将这100万个ID,存储在一个普通的“列表”或“数组”中,那么,每一次检查,程序,都需要从头到尾,遍历这个列表,其单次操作的复杂度是O(n)。
高效的结构(哈希集合):如果你将它们,存储在一个“哈希集合”中,那么,每一次检查,程序,都只需要进行一次哈希计算,其单次操作的平均复杂度,是**O(1)**,即与黑名单的规模大小,无关。
场景:频繁的“中间插入”
问题:你需要在一个包含了大量元素的列表中,频繁地,在其中间位置,插入新的元素。
低效的结构(数组):如果你使用“数组”来实现,那么,每一次的中间插入,都将迫使数组,将其后续的所有元素,都向后“挪动”一个位置。这个操作的复杂度是O(n)。
高效的结构(链表):如果使用“链表”,则只需要修改前后两个节点的“指针”即可,其操作复杂度是O(1)。
四、元凶三:内存的“瓶颈”与“颠簸”
当数据量,大到一定程度时,内存的“容量”和“管理效率”,就会成为新的、严峻的瓶颈。
1. 一次性加载“巨型”数据 一个最常见的、导致程序因“内存溢出”而直接崩溃的错误,就是试图,将一个远超内存容量的“巨型”文件(例如,一个10GB的日志文件),一次性地,全部读取到内存中,来进行处理。
【解决方案】:必须采用“流式处理”或“分块处理”的方式。即,每次只读取文件的一小部分(例如,10MB)到内存中进行处理,处理完毕后,再读取下一块,直至文件末尾。
2. 频繁的“对象创建”与“垃圾回收” 在Java, C#, Go等具有“自动内存管理”的语言中,我们无需手动释放不再使用的内存,这个工作,由一个名为“垃圾回收器”的后台进程来完成。
问题:如果我们的代码,在一个处理大量数据的、紧凑的循环中,不必要地,创建了数以百万计的、生命周期极短的“临时对象”,那么,这就会给“垃圾回收器”,带来巨大的压力。
后果:垃圾回收器,可能会被频繁地触发。而在许多垃圾回收算法的执行过程中,都需要或多或少地,暂停我们应用程序的正常运行(即所谓的“Stop-the-World”)。这种由垃圾回收,所引发的、周期性的“程序卡顿”,在高并发、大数据量的场景下,是性能急剧下降的一个重要元凶。
五、元凶四:输入输出的“等待”
在很多时候,我们的程序,之所以“慢”,并非因为中央处理器在“拼命计算”,而恰恰是因为,它在“无所事事地,等待”数据的到来。这种“等待”,就是“输入输出”瓶颈。
1. 数据库的“慢查询” 这是在Web应用和后台服务中,最普遍、最致命的性能瓶颈。
未加“数据库索引”的查询:当你在一个拥有数千万行记录的“订单”表上,试图根据一个“用户ID”,去查询其订单时,如果没有为“用户ID”这个列,建立“索引”,那么,数据库,就不得不,像翻阅一本没有目录的字典一样,从第一行到最后一行,进行一次完整的“全表扫描”。这个操作的耗时,是灾难性的。
N+1查询问题:这是一个在使用对象关系映射框架时,极其常见、但又很隐蔽的性能杀手。
场景:你首先,查询出了100个“部门”。然后,在一个循环中,去逐一地,获取每一个部门下的“员工”。
后果:这个过程,最终,会向数据库,发起了101次查询(1次查询部门,N=100次查询每个部门的员工)。而一个高效的实现,本应通过一次“连接查询”,只用1次查询,就获取到所有需要的数据。
2. 低效的文件读写与网络调用
- 在处理大文件时,一次只读写一个字节,远比使用“缓冲”技术,一次读写一个数据块,要慢得多。
- 在一个循环中,向另一个服务,发起了1000次独立的网络调用,其总耗时,必然远高于,将这1000个请求,合并为一次“批量”调用。
六、如何“预防”与“定位”
1. 预防策略:将性能“内建”于流程
性能测试:不能等到上线后,才第一次面对“大流量”的考验。负载测试、压力测试等性能测试活动,必须被前置到开发和测试周期中来。
代码审查:在进行代码审查时,必须将“性能”和“复杂度”,作为一个与“功能正确性”同等重要的审查维度。一个有经验的架构师,能够轻易地,从代码中,嗅出“嵌套循环”、“N+1查询”等潜在的性能“坏味道”。
架构设计:一个需要处理海量数据的系统,其可扩展性,必须在最初的架构设计阶段,就被充分地、系统性地考虑。
2. 定位策略:当性能下降时
性能分析工具:这是诊断性能瓶颈的、最专业、也最强大的“手术刀”。一个“性能分析器”,能够直接地,告诉你,在你的程序运行时:
哪个函数,消耗了最多的中央处理器时间?
哪个对象,占据了最多的内存空间?
哪个数据库查询,被执行的次数最多,且平均耗时最长? 这能够帮助我们,极其精准地,定位到那个“最热”的、最需要被优化的代码点。
日志分析:在关键的业务流程的“入口”和“出口”,都打印一行带有“时间戳”的日志。通过分析线上日志,计算出各个环节的“平均耗时”,我们就可以快速地,定位到整个流程中最慢的那个“瓶颈”环节。
在实践中,这些预防和定位活动,都需要工具的支撑。例如,团队的编码规范(其中应包含性能相关的最佳实践),可以被沉淀在像 Worktile 这样的平台的知识库中。而性能测试的结果、性能分析报告、以及因此而产生的“性能优化”任务,则可以在像 PingCode 这样的研发管理工具中,被作为专门的工作项,进行指派、跟踪和管理,确保每一个性能问题,都能被闭环解决。
常见问答 (FAQ)
Q1: 算法的“时间复杂度”和“空间复杂度”有什么区别?
A1: “时间复杂度”,衡量的是,一个算法的执行时间,随数据规模增长的趋势。而“空间复杂度”,衡量的是,一个算法在运行过程中,所需要额外占用的内存空间,随数据规模增长的趋势。有时,我们可以通过“增加空间复杂度”(例如,使用一个哈希表),来换取“降低时间复杂度”。
Q2: 是不是应该在项目一开始,就对所有代码进行性能优化?
A2: 不是。这恰恰是高德纳所警示的“过早优化”。在项目初期,代码的“清晰性”和“正确性”,远比“性能”更重要。我们应该在完成了功能,并通过性能测试或线上监控,明确地,定位到了真正的“性能瓶颈”之后,再对那些“关键的少数”代码,进行针对性的优化。
Q3: “数据库索引”为什么能极大地提升查询性能?
A3: 一个“索引”,就如同书籍的“目录”。如果没有目录,要找一个知识点,你需要从第一页,翻到最后一页。而有了目录,你就可以通过几次快速的查找,直接定位到它所在的页码。数据库索引,正是通过一些高效的数据结构(如B+树),为数据表的某个(或某些)列,创建了一个类似的“快速查询目录”。
Q4: 什么是“N+1查询”问题?
A4: “N+1查询”问题,是指在查询一个“主”对象列表(1次查询)后,又在一个循环中,为每一个“主”对象,都单独地,去查询其关联的“子”对象(N次查询),最终,总共,执行了N+1次数据库查询。这是一种极其低效的数据访问模式,应通过“连接查询”或“批量预加载”等技术,将其,优化为1-2次查询。
文章包含AI辅助创作,作者:mayue,如若转载,请注明出处:https://docs.pingcode.com/baike/5214695
