一条SQL查询语句在数据量较小时运行如飞,一旦数据量激增其性能便急剧下降到无法忍受的地步,这一现象的根源通常在于该查询的“执行计划”随着数据量的变化,从一种高效的“精确定位”模式,退化为了一种低效的“暴力遍历”模式。导致这种性能“断崖”的五大核心“元凶”涵盖:缺失或失效的“数据库索引”、不恰当的“连接查询”与“笛卡尔积”、查询中包含了“非索引优化”的操作、不合理的“数据库表结构”设计、以及数据库服务器自身的“硬件资源”瓶颈。
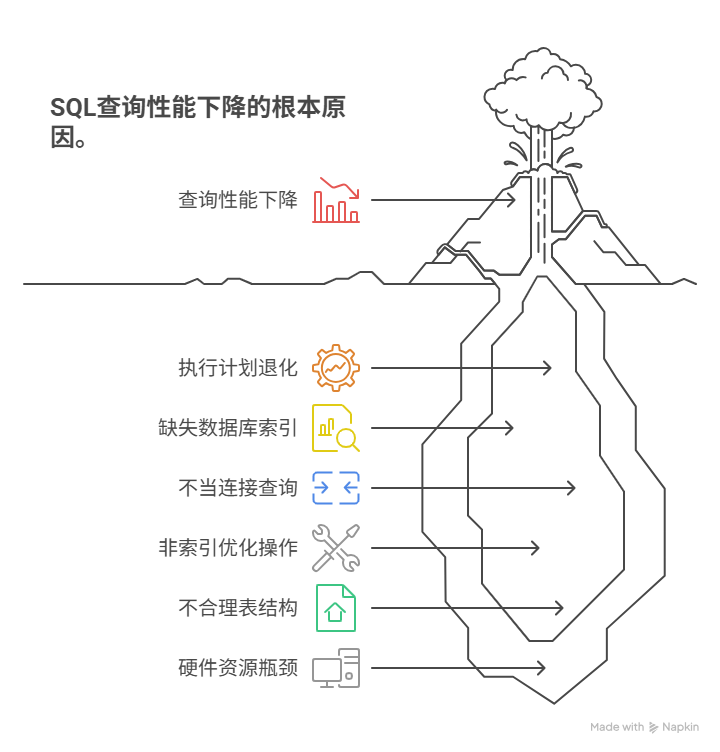

其中,缺失或失效的“数据库索引”是所有原因中最为普遍和致命的一个。没有索引的查询迫使数据库必须进行“全表扫描”,也就是逐行检查每一条记录。对于一张只有几千行的小表,这种操作尚可接受;但对于一张拥有数千万甚至上亿行记录的大表,一次全表扫描就可能耗费数分钟乃至数小时,这对于任何一个在线应用而言都是一场灾难。
一、问题的“本质”、算法复杂度的“降维打击”
要从根源上理解性能为何会“急剧”下降,我们必须引入一个计算机科学中最核心的概念——算法复杂度。一条数据库查询本质上是数据库内部执行的一个“查找数据”的算法,这个算法的“优劣”直接决定了查询性能的上限。
当一个查询条件所涉及的列上没有建立索引时,数据库为了找到所有符合条件的记录,它唯一能做的就是进行一次“全表扫描”。这意味着数据库需要从物理存储的第一行开始,逐一地将每一行数据都加载到内存中并检查其是否符合查询条件,直到最后一行。这种查找方式的时间复杂度是线性的,也就是说查询所需的时间与表中的总记录数N成正比关系。当数据量从一万行增长到一亿行(增加了一万倍)时,查询的时间也将粗略地相应增长一万倍。
与之相对,如果我们在查询条件的列上建立了一个设计良好的“索引”,数据库就可以利用这个索引来进行一次高效的“精确定位”。这如同在一本厚厚的、拥有数千页的字典中通过“目录”或“页眉”来查找一个单词,而非从第一页逐字地翻到最后一页。一次典型的索引查找,其时间复杂度是对数级别的。这意味着即便数据量从一万行增长到一亿行,其查询所需的时间可能仅仅是从几次磁盘读取增加到十几次而已,其性能的增长几乎可以忽略不计。正是线性复杂度与对数复杂度这两条增长曲线之间存在的、随着数据量N的增大而急剧拉开的“巨大鸿沟”,才导致了那条原本在小数据量下“飞快”的查询,在大数据量下变得“慢得无法忍受”。
二、元凶一、缺失的“数据库索引”
在所有导致慢查询的原因中,百分之九十以上都与索引的“缺失”或“失效”直接相关。
一个“索引”是一个独立于主数据表之外的、专门为了“加速查询”而创建的、排好序的“辅助数据结构”。这个结构中存储了被索引列的值,以及一个指向主表中包含该值的行的“物理地址”的指针。
然而,仅仅“创建”了索引并不意味着查询就一定会变快。在很多情况下,一个“不恰当”的查询写法会导致数据库的“查询优化器”主动“放弃”使用这个已存在的索引,转而退化为低效的“全表扫描”。索引失效的最常见原因包括在被索引的列上使用了“函数”。例如WHERE YEAR(order_date) = 2025这样的查询,即便order_date列上存在索引也无法被使用。因为数据库需要为表中的“每一行”都先执行一次函数才能得到可供比较的值。另一个常见的原因是在使用“模糊查询”时,将“通配符”放在了搜索词的开头,例如 WHERE name LIKE '%张三',这也将导致索引无法被有效利用。
要诊断一个查询是否有效利用了索引,最权威的工具就是数据库自带的“执行计划”分析功能。通过在你的查询语句前加上EXPLAIN这个关键字,数据库就会返回一份详细的“报告”,告诉你它为了执行你这条查询所选择的“具体步骤”。在这份报告中,如果你看到了“全表扫描”的字样,那么你就找到了性能问题的第一个、也是最重要的“罪魁祸首”。
三、元凶二、低效的“连接”与“子查询”
当查询需要从多个数据表中获取关联数据时,问题的复杂性会进一步增加。
一个极其重要的、但常常被忽略的优化原则是:所有在多表“连接”查询的连接条件中用到的“连接键”列,都必须在这两个表中分别地建立索引。例如,在 FROM orders JOIN users ON orders.user_id = users.id 这条查询中,orders表的user_id列和users表的id列都应是索引列。如果缺少这些索引,数据库在进行连接时其内部的算法效率会急剧下降。
如果一个多表连接查询忘记了或者错误地书写了连接条件,那么数据库就会执行一次“笛卡尔积”运算。这意味着它会将第一张表中的“每一行”都与第二张表中的“每一行”进行一次“配对”。如果两张表都分别包含一万行数据,那么最终的结果集将是一亿行。这不仅会产生业务上无意义的结果,更会瞬间耗尽数据库的所有资源。
在复杂的报表查询中我们常常会使用“子查询”。然而,一些特定类型的子查询,特别是那些“非相关子查询”,可能会被一些版本的数据库优化器以一种极其低效的方式来执行。它可能会将那个内部的“子查询”重复地、独立地执行上万次。在很多情况下,通过将一个复杂的“子查询”改写为一个等价的、但更高效的“连接查询”,能够带来数量级的性能提升。
四、元凶三、“不可索引优化”的查询条件
这是一个更深层次的、关于“查询语句可优化性”的问题。即便相关的列上存在索引,但如果我们的WHERE查询条件写得“不够好”,那么数据库的查询优化器也依然可能无法利用这个索引。 这类“不可被索引优化”的查询条件,在数据库领域有一个专门的术语。一个查询条件如果能够利用到索引来快速地筛选数据,我们就称其为“可作为搜索参数的”。
常见的“不可索引优化”模式,除了前文提到的在索引列上使用“函数”和“前导通配符”,还包括对索引列进行“数学运算”或“类型转换”。例如,WHERE order_amount * 1.1 > 1000,或者 WHERE phone_number = 13800001234(而phone_number列的类型是“字符串”)。
要解决这类问题,核心的思路是通过“代数等价”变换,将施加在“列”上的运算,转移到“值”的一侧。例如,WHERE order_amount * 1.1 > 1000应被改写为 WHERE order_amount > 1000 / 1.1。WHERE phone_number = 13800001234应被改写为 WHERE phone_number = '13800001234'。经过这种“改写”后,查询优化器就能够直接地利用order_amount或phone_number列上的索引来进行高效的“范围查找”或“等值查找”了。
五、系统性的“诊断”与“预防”
当线上出现了一个“慢查询”时,应遵循一个标准的“诊断”流程。首先是定位慢查询,通过开启数据库的“慢查询日志”或借助专业的“应用性能监控”工具,首先精准地定位到那条“罪魁祸首”的查询语句。其次是分析“执行计划”,这是最核心的诊断步骤,将这条慢查询放入到数据库的查询分析器中并执行EXPLAIN命令来获取其“执行计划”。然后需要解读执行计划,仔细地解读执行计划的每一个步骤,检查是否存在“全表扫描”、是否存在低效的“连接算法”、预估的“扫描行数”是否过大等。再根据执行计划暴露出的问题去检查索引与表结构,其索引是否被正确地创建和使用。最后一步是重写并验证,基于分析对查询语句进行重写优化,并再次通过EXPLAIN来验证新的查询是否已经走上了那个我们所期望的、高效的“索引查找”路径。
在预防层面,也需要建立系统性的策略。在设计阶段就考虑查询模式是至关重要的一环,数据库的“表结构”和“索引”设计不应是“想当然”的,而必须是基于对未来“主要查询模式”的预判。同时,代码审查中的“查询”专项也非常重要,所有新增的、特别是那些复杂的数据库查询,都应被视为“高风险”代码,并需要由经验丰富的开发者或数据库管理员进行专项的、深入的审查。最后,团队应建立“数据库”规范,将关于“索引设计原则”、“查询编写最佳实践”等沉淀为一份共享的、活的《数据库开发规范》文档。
常见问答 (FAQ)
Q1: 为什么有时候,加了索引,查询反而变慢了?
A1: 这是一种罕见但可能发生的情况。其原因通常是,因为你的查询所需要返回的数据行数占了全表总行数的“绝大部分”。在这种情况下,数据库的“查询优化器”会智能地判断出,直接进行一次“全表扫描”的总成本,反而会低于先“查找索引”再进行大量的“随机”磁盘回表查询的成本。
Q2: 什么是“查询优化器”?它为什么有时候会“选错”索引?
A2: “查询优化器”是数据库内部最“智能”的大脑。它负责为每一条查询语句计算出所有“可能”的执行路径,并基于对“数据分布统计信息”的估算,从中选择一个它认为“成本最低”的路径作为最终的“执行计划”。然而,如果数据库的“统计信息”过时或不准确,它就可能会被“误导”从而做出错误的判断。
Q3: “索引”是越多越好吗?
A3: 绝对不是。索引在提升“查询”性能的同时,也会带来“写入”(增、删、改)操作的额外开销。因为每一次的写入操作,数据库不仅需要修改主表的数据,还需要同步地去修改相关的、所有索引结构中的数据。过多的、不必要的索引会严重地拖慢系统的“写入”性能。
Q.4: 除了文中提到的,还有哪些原因会导致数据库查询变慢?
A4: 其他常见原因还包括:数据库“锁”竞争(大量的更新操作导致了行或表的锁定,使查询需要等待);数据库服务器自身的“硬件资源”达到瓶颈(如中央处理器、内存、或磁盘读写能力不足);以及不合理的数据库配置参数等。
文章包含AI辅助创作,作者:mayue,如若转载,请注明出处:https://docs.pingcode.com/baike/5215206
