这是我们关于某海外音频科技公司如何进行组件群管理,以及如何大规模管理软件的系列文章第二部分。另请参阅第一部分和第三部分。
在这家公司,我们采用了声明式基础设施范式,以改进基础设施平台的配置管理方式和控制平面设计。借助这一方式,我们能够在大规模环境下,管理分布于数万个不同服务中的数十万个云资源。
简单来说,声明式基础设施的核心价值在于:把基础设施配置变成可审查、可追踪、可自动化处理的数据,让平台团队能够持续治理云资源,而不是依赖人工排查和一次性迁移。
在企业实际落地这类治理能力时,基础设施数据也需要和研发过程中的目标、需求、开发、测试、发布和知识沉淀相互衔接。例如,PingCode 这类智能化研发管理工具,可以帮助团队把研发管理过程自动化、数据化、智能化,让研发链路中的信息更顺畅地流转,为平台治理和持续改进提供更完整的上下文。

从自有数据中心到声明式基础设施
几年前,这家公司从完全托管在自有数据中心的架构,迁移到了某云平台。作为迁移的一部分,我们采用了“平移式迁移”模式,基本保留了现有服务、架构,以及它们与底层基础设施之间的关系。
这意味着,开发者在云端选择的具体基础设施,会因用例和团队不同而存在很大差异。随着我们对云环境运行方式的理解不断加深,最佳实践建议也随之演进。
例如,在自有数据中心时代,最佳实践可能包括:自行托管 Cassandra 集群,通过 Kafka 传递消息,运行自定义的 Elasticsearch 或 PostgreSQL 实例,或者在专用虚拟机上安装 Memcached。
但到了云端,上述场景往往都有了托管式替代方案。例如,可以使用托管式宽列数据库、托管式发布订阅消息服务,或者在 Kubernetes 之上运行 Memcached。
因此,多年来构建出来的基础设施逐渐形成了一条“长尾”:它既记录了不同时期最佳实践的快照,也记录了我们在演进过程中犯下的错误。
随着公司持续发展,这个问题变得越来越严重。虽然工程团队的增长速度相对稳定,但软件开发量和基础设施建设量却呈指数级增长,远远超过开发者人数的增长速度。
一个开发团队需要维护数十个,甚至数百个代码库的情况变得越来越普遍。在这家公司内部,这些代码库通常被称为“组件”。
此外,由于收购和组织调整,代码库所有权转移也越来越频繁。这导致拥有代码库的团队,逐渐失去了对当前架构和基础设施选择的完整理解。
我们严重缺乏一种机制,可以将现有基础设施升级到最新、最好的标准,并让整个组件群保持在一种基础设施选择足够一致、碎片化程度足够低的状态。只有这样,内部平台组织才能支撑整个基础设施的规模。
云资源管理为什么需要新方法
在自有数据中心环境中,每台机器通常都被视为珍贵的“宠物”。我们依赖以主机为中心的配置管理工具,例如 Puppet;在某些情况下,也会使用 Ansible。
团队自行托管基础设施也十分常见,上文已经提到了一些例子。
然而,由于以下几个原因,这种方法在云环境中行不通。
首先,在云环境中,我们通常会鼓励团队使用云厂商提供的托管式替代方案,而不是自行托管基础设施。
其次,许多配置既不特定于某个服务,也不特定于某个基础设施资源。例如,IAM 配置、网络和防火墙配置,以及订阅、备份、跨区域复制规则等实体之间的关系,并不一定能很好地映射到某个具体服务、虚拟机实例或类似对象上。
再次,云环境中并不存在适合 Puppet 或 Ansible 那种缓慢、稳定、面向主机协调模型的长时间运行计算实例。虚拟机或 Kubernetes Pod 随时可能被重新调度或取消调度。而启动一个由 Puppet 管理的新虚拟机实例所需的漫长初始化过程,也无法支持数据中心中不断变化的流量模式。
因此,我们一直在寻找一种新的解决方案,让我们能够掌控公司的全部基础设施,并摆脱过去以主机为中心的配置管理模式。
我们仍然希望保留一些重要能力,例如应用公司级策略、引导用户遵循最佳实践等。因此,我们需要一种能让整个公司形成共识的解决方案。
很快,我们就发现,这个方案必须满足一些约束条件。
第一,我们需要支持 GitOps 工作流。基础设施配置应该和源代码一起提交,可以接受同行评审,并保留完整审计轨迹。
第二,为了理解整个基础设施组件群,也就是所有现有基础设施资源,我们需要一个支持运行时自省的方案。例如,我们应该能够枚举公司中存在的所有数据库,识别可能违反特定策略的数据库,并确定它们属于哪个团队。
在某些情况下,我们还需要支持紧急处理。例如,SRE 团队可以立即介入,修改某个基础设施资源的配置,从而绕过常规 GitOps 工作流。
第三,为了能够对基础设施进行自动化变更,配置必须是数据,例如 JSON 或 YAML,而不是代码,例如 Starlark、HCL、TypeScript 等常见基础设施配置工具所使用的形式。
修改代码,使其执行后产生期望的基础设施输出,是一件非常困难的事情,甚至会触及停机问题这类理论边界。但修改作为数据存在的配置,则要简单得多。
第四,我们找到的方案,还必须能够成为公司所有现有基础设施的最终归宿。我们并不是从零开始。事实上,在着手这项工作之前,公司已经拥有数十万个云资源。
因此,任何被选中的方案,都需要支持某种形式的“导入”工作流:也就是通过配置文件对现有基础设施进行编码,同时不影响这些基础设施资源的当前状态。
我们认为,一个不错的起点是直接对原始云资源进行建模。但从长期来看,这会带来巨大的配置开销。因此,我们将其视为引入定制资源的过渡步骤。通过定制资源,我们可以封装、打包和组合底层资源,并最终消除所有原始云资源声明。
常见方案无法满足上述全部要求。例如,某些基础设施即代码工具无法满足运行时自省和“配置必须是数据”这两项要求。
最终,我们决定使用 Kubernetes 来建模基础设施资源。事实证明,它完全满足上述要求。我们将最终形成的产品,简单地称为“声明式基础设施”。
声明式基础设施架构。
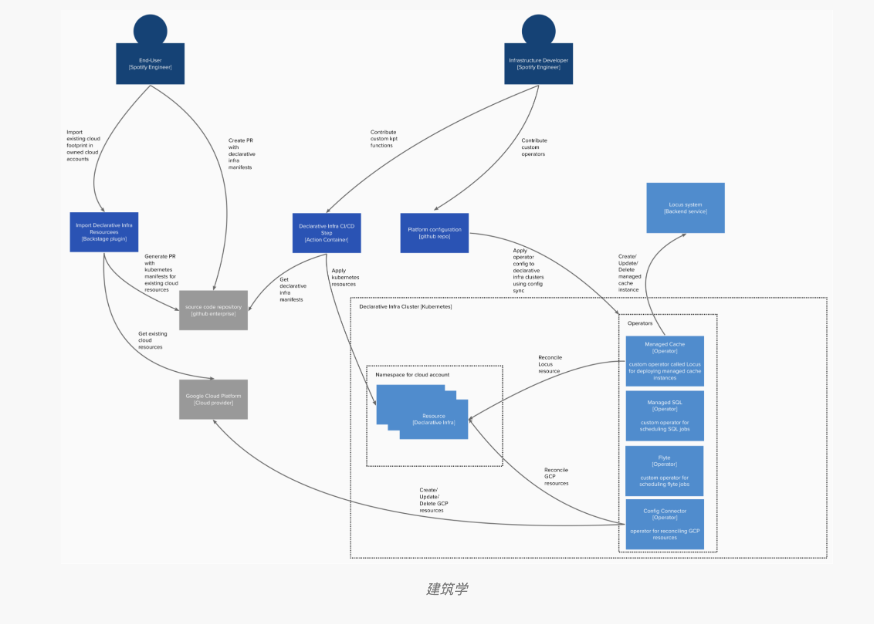
如何用 Kubernetes 实现声明式基础设施
我们通过自定义资源,在 Kubernetes 中实现对声明式基础设施资源的支持。
每一种基础设施资源,无论是原始云原语,还是定制的自定义资源,都会通过自定义资源定义(CRD)进行建模。
Operator 会持续协调这些资源,努力让实际环境与基础设施声明保持一致。这里的实际环境包括某云平台、托管缓存系统、数据工作流系统,以及其他基础设施系统。
我们选择在专用 Kubernetes 集群上运行声明式基础设施平台。这样做主要是为了降低影响主工作负载集群中其他服务的风险。
与无状态服务工作负载不同,声明式基础设施 Operator 可能会对 API Server 提出相当高的要求,而无状态服务通常对工作节点要求更高。
目前,这个平台已经管理 3000 多个云项目和约 5 万个云资源。
Kubernetes 清单通常会通过 CI/CD 流程,从源代码仓库导入 Kubernetes 集群。构建过程中的一个步骤是“声明式基础设施步骤”:它以 Docker 镜像形式运行,使用 kpt 对清单执行一些轻量级转换和验证,然后将其应用到对应的 Kubernetes 集群中。
为了简化操作并实现隔离,CI/CD 系统中的每个源代码仓库都会使用一个专用服务账号。此外,每个云项目都会创建一个对应的 Kubernetes 命名空间,二者一一对应。
这样,我们就可以限制仓库访问权限,使其只能管理那些已经明确授权的云项目中的资源。
用户可以通过多种机制,在自己的源代码仓库中创建 Kubernetes 资源清单。
第一种方式是导入现有云资源。内部开发者门户的导入插件会从相关云账号查询资源,并使用云资源配置连接器生成包含相应清单的拉取请求。鉴于公司已经在云平台上部署了大量资源,这种方式有助于快速采用声明式基础设施平台。
第二种方式是生成推荐配置。内部开发者门户插件会根据用户对若干问题的回答,生成符合当前最佳实践的基础设施清单。
第三种方式是使用带自动补全能力的 IDE 插件,从而更轻松地编写 YAML 清单文件。
内部开发者门户中的资源导入插件。
在构建过程中,清单会被应用到集群。随后,声明式基础设施构建步骤会等待 Kubernetes 资源协调完成,例如等待托管缓存实例创建完成,并在构建日志和拉取请求中向用户反馈操作成功或失败的结果。
代码审查构建还会对集群执行轻量级验证和试运行,并向用户反馈即将新增、更新或删除的资源。
资源审查构建成功时的反馈示例。
Kubernetes Operator 会响应资源的所有变化,处理其所管理基础设施的创建、更新和删除,并在 Kubernetes 资源被删除时执行相应清理。
为了避免意外变更,并确保工具能够扩展到整个组织,无论使用者经验水平如何,我们决定通过基于角色的访问控制(RBAC)限制用户的默认权限,使其只能访问资源。同时,我们添加了紧急更新和删除机制。
这套机制允许团队在无需等待完整代码审查和构建流程的情况下,进行紧急变更。每个命名空间都会创建一个紧急账号,拥有该账号的团队可以进行模拟访问。
在 Kubernetes 上管理声明式基础设施的一个主要优势,是它具备很强的可扩展性。基础设施开发者可以通过构建自定义 Operator 为平台做贡献。
这使得我们能够针对各种基础设施需求构建高级抽象,例如托管数据库、托管缓存、数据作业,以及其他用例。目前,我们已经拥有大约 20 个内部构建的 Operator。
以下是一个托管缓存实例的示例资源。通过检查声明式基础设施资源的状态,可以收集运行时信息。
另一个例子是数据端点资源,它用于定义数据集,并可以进一步创建和管理底层云存储资源的生命周期。
还有一个团队通过 CRD 创建数据工作流项目。Operator 会同时创建云服务账号,为其附加角色绑定,并为多个命名空间修复工作负载身份配置。
这种与多个资源交互的方式,大大降低了脚本编写的复杂性,也让平台侧可以实现一系列新的自动化能力。
声明式基础设施平台还可以通过基础设施开发者实现 kpt 函数,或添加策略校验与变更 Webhook 配置来扩展。
与 kpt 相比,策略校验 Webhook 的优势在于:无论资源以何种方式应用到集群,这些逻辑都会生效。而 kpt 函数只在声明式基础设施操作容器的客户端运行,因此更容易被绕过。
声明式基础设施的未来
我们很高兴能够继续为这个平台添加新功能。
对于最终用户,我们希望进一步改善开发者体验,具体包括以下方面。
首先,创建云资源应该变得非常简单,不需要手写 YAML 声明,也不需要依赖导入现有云资源。
其次,与内部开发者门户更紧密地集成,使用户无需手动查询集群,就能查看资源的运行时状态。
对于基础设施开发者,我们将致力于改善其他基础设施团队在这个平台之上开发 Operator 的体验。对于这类跨团队推进的平台能力建设,Worktile 这类通用项目协作系统也可以用任务、项目、文档、目标、日历、甘特图、工时和审批等能力,帮助团队把路线图、责任分工和推进节奏管理起来,减少基础设施平台演进过程中的协作摩擦。
文章包含AI辅助创作,作者:guo,如若转载,请注明出处:https://docs.pingcode.com/baike/5243025
