











要是直接在ChatGPT上问RISC-V未来有没有可能入驻高性能计算领域,或者如何占领高性能计算市场,以ChatGPT“端水大师”的秉性,大概率也不会正面回答。
这个问题转换一下思路,遥想2007年前后,x86在高性能计算市场全面取代其他架构。当年x86是怎么成功的,或者说怎么达成此等目标的,理论上不就是现在RISC-V可以参考的吗?于是我们问了ChatGPT,x86是如何在HPC领域逐渐取代其他指令集的。答案如下:
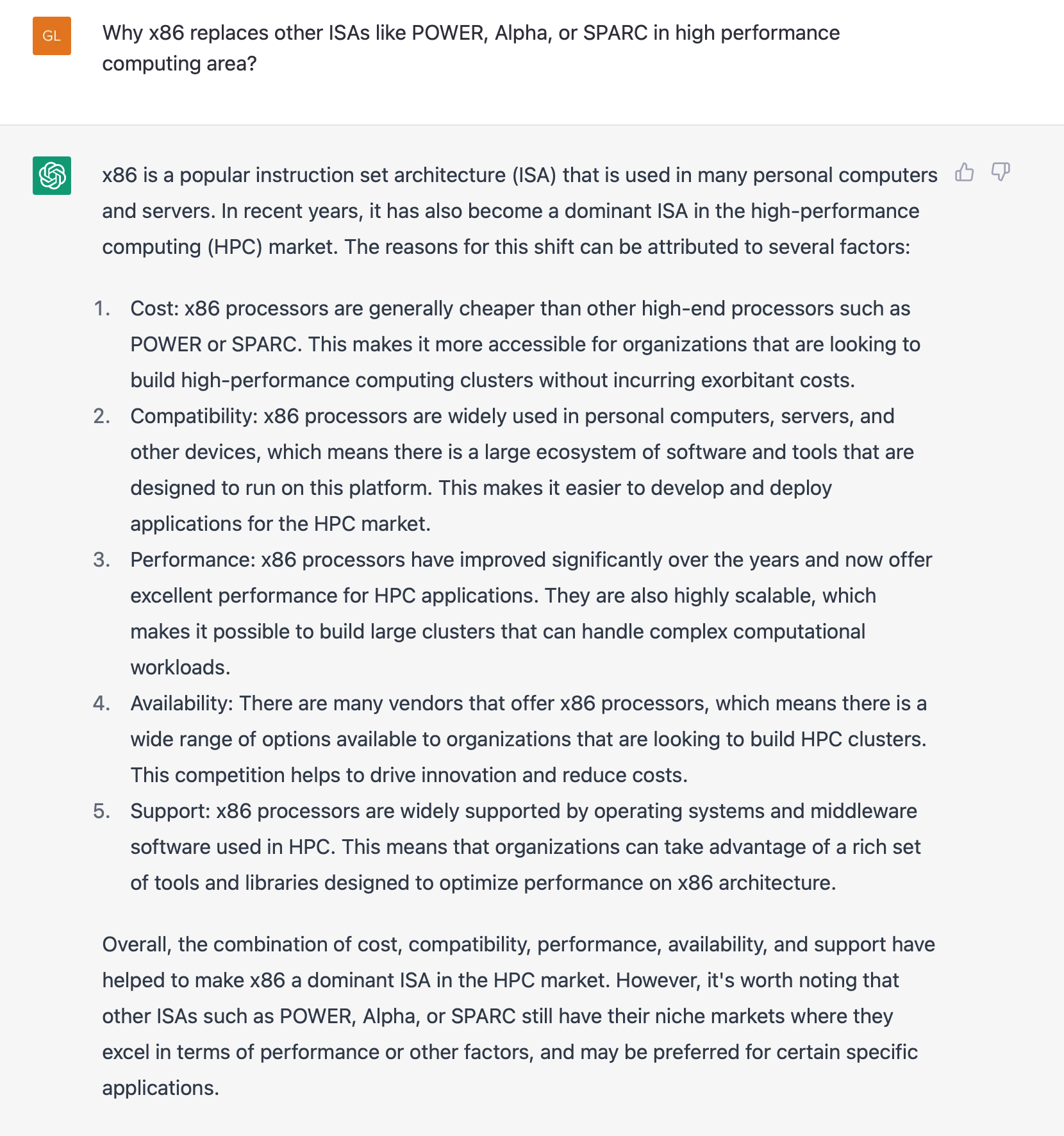
感觉说的方向大差不差,除了第四点“availability”的“x86处理器有很多供应商”(或许它的意思是很多OEM供应商)是在瞎说以外,其他几点也是某指令集在某市场有所斩获的通用答案。
去年我们曾经写过一篇题为《RISC-V在高性能领域有发展机会吗》的报道——只不过这篇文章以报道滴水湖论坛为主,并未着眼于RISC-V全局。这篇文章,我们打算多花点儿笔墨来探讨这个话题。
在此之前,我们还是要把“高性能”这个“领域”做简单界定。我们所说的RISC-V“搞定高性能市场“,理论上不应局限于HPC、超算,也在PC、汽车、数据中心这些部分。“高性能”是与“低功耗”相对的——而低功耗是指移动、嵌入一类的市场。
但不同细分领域的市场发展都有差异。比如说一般企业数据中心服务器的处理器,并不是家用PC处理器多加点儿核心和存储资源那么简单。而且PC与数据中心的生态需求差异也很大。所以本文暂且将“高性能”局限在数据中心(明确排除汽车、PC)。
其实就连数据中心也有不同的类别。去年英伟达把“数据中心”切分成了6个大的门类,分别是超级计算中心(超算)、企业计算数据中心(企业内数据中心)、超级集群(hyperscaler,占地超过1万平方英尺,服务器超过5000台的数据中心)、云计算、AI工厂、边缘数据中心(更接近端侧的数据中心)。这些数据中心的性能需求、技术方向都有不同。我们无法每一项都做剖析,所以只能从大方向将“高性能”市场作为一个抽象系统来谈。

虽说RISC-V这两年发展神速,但芯片出货量的大头、大部分应用还是集中在了嵌入式领域,有很大一部分核心出货量是不直接面向用户的。比如滴水湖论坛每年都在提的RISC-V生态成果,比如西数硬盘内RISC-V核心,甚至苹果都准备将一些不面向用户的功能切到RISC-V指令集上。
而在高性能部分,RISC-V其实也算有一些成果。最典型的像是谷歌TPU、平头哥在RISC-V高性能领域的规划,还有现在很火的Ventana面向数据中心的RISC-V处理器;以及此前Intel与BSC(巴塞罗那超算中心)合作准备为超算打造RISC-V芯片——虽然这个计划有一定概率已经黄了(受到Pathfinder计划停止的影响)…
以其发展年份,及其对于各部分市场的渗透,RISC-V的发展速度应该是x86、Arm历史上都很难企及的。看起来是前景一片大好。那么RISC-V在高性能市场会有多大的机会?
ChatGPT列出的当年x86于HPC市场成功的一大原因是“性能”。这当然是某一个指令集的处理器产品能够进驻高性能市场的先决条件,否则怎么叫“高性能”呢?
在高性能核心架构方面,一直在积极推进的应该是作为IP供应商的SiFive。这家公司现在有两个高性能计算上相对重要的客户:谷歌和NASA。在具体的产品上,SiFive一直在更新高性能系列核心IP。最新的P670是个13级流水线、4发射的乱序架构,在面积效益上对标的是Arm Cortex-A78。
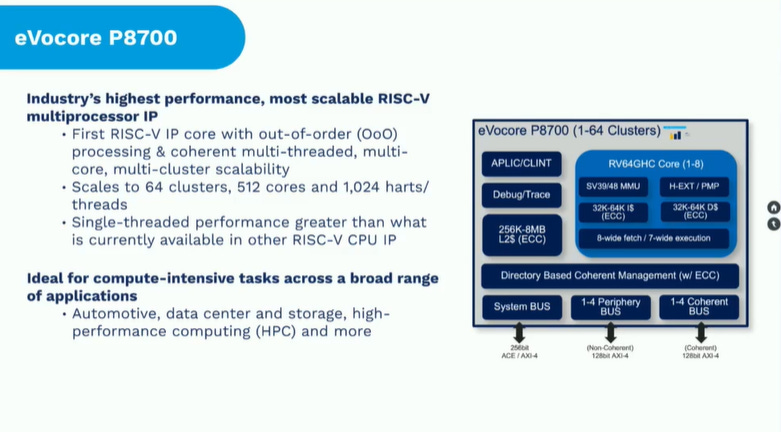
另外MIPS这家公司现在正在搞RISC-V(虽然听起来很奇特)。他们有个eVocore P8700核心,从8-wide取指、7-wide执行来看,这是个超宽大核心;每个cluster非常多8核方案,可扩展至64 cluster、512核心;应用方向是汽车、数据中心、HPC等。无论如何也都是高性能了。
还有像是平头哥玄铁C910之类的很多同学应该都比较熟悉了;以及我们一直在提,后文也会提到的Ventana。
不过当高性能涉及到到大规模集群、超算之类的程度,那么仅有高性能核心是远远不够的。PC这类设备的高算力需求场景可能在3D游戏、视频渲染之类的场景上,这些工作要求性能突发、高频率。但对数据中心和超算而言,大量程序同时运行的并行吞吐才是最重要的——所以我们看到面向服务器的处理器虽然核心数量超多,但核心频率却并不怎么高。
一般超级集群数据中心或者云要响应大量的用户请求,所以需要并行和吞吐。而具体到超算上,超算解决气候预测、蛋白质折叠、量子计算模拟之类的问题,这些问题的任何一个都要拆解成需要大规模并行的细分问题。这样的规模一旦大到一定程度,则不是一颗或者几颗处理器、加速器芯片可以解决的。
所谓的“集群”部署,是指大量处理器不仅需要跨芯片做通信,还需要跨板、跨服务器节点做通信。这类系统的一大瓶颈在节点之间的通信延迟和带宽方面——换句话说就是大量处理器同时工作时,协同的能力和效率。当然完成不同的任务,对核心与系统的需求也可能存在很大差异,但大方向就是如此。
某种程度上,x86在数据中心的某些细分领域,比如HPC AI领域显现出颓势,与其系统内部互联方式(如CPU与加速器的互联)、节点互联与通信的效率有关系——尤其是AI追求的数据处理过程中的数据传输大吞吐。所以在英伟达宣布Arm架构的Grace CPU之际,NVLink 4作为CPU与GPU的的通信带宽相较于PCIe是惊艳了很多人的。

这涉及到的是周边生态与系统成熟性问题。可能绝大部分同学对于“生态”的理解是局限在下游的应用生态的。但当把眼光放到上游、周边和下游,生态的问题可能就没那么简单了。不仅是互联,还有存储支持等处理器之外一整套系统的性能和效率问题。当这些共同被提起时,RISC-V的高性能之路可能还有些漫长。
Arteris IP的解决方案与业务开发副总裁Frank Schirrmeister此前在接受外媒采访时曾说:“对于HPC而言,处理器核心的时钟频率、核心数量、核心可扩展性以及对应的互联方式都是关注点所在。但内存带宽、能效、增加自有适量指令集之类的问题也同样重要。”“
Rob Aitken(Synopsys fellow)也说过,数据是要从内存载入到处理器中的,而且还需要在加速器内做数据处理,并写回到内存里,“整条路径上,各环节都可能成为瓶颈。uncore部分很关键,存储系统也很关键。在完成特定的任务时,需要搞清楚系统架构的瓶颈在哪儿。这些都在CPU以外。”

BSC(巴塞罗那超算中心)此前就和其他高校在联合开发基于RISC-V架构的高性能计算系统Monte Cimone。介绍中提到Monte Cimone总共8个计算节点,每个节点内都采用SiFive的U740芯片(基于SiFive HiFive Unmatched板),每个芯片里4个U74核心,频率较高1.2GHz。一个节点系统内16GB DDR4内存,1TB NVMe存储。这部分研究也挺有趣,有兴趣的同学可前往阅读。
领衔这套系统研究的意大利超算中心CINECA表示,虽然RISC-V现在的发展速度很快,软件栈也快速走向成熟,但是“显然SoC的核心性能与数量,最终所能够达到的性能,仍然无法与成熟的Arm和x86核心相较”。这说的就是系统层面真正展现出来的性能水平。
Intel还没有叫停RISC-V Pathfinder项目之时,Intel的超级计算业务总经理兼副总裁Jeff McVeigh曾说HPC要应用RISC-V还有好多年的距离(many years away)。“除了设计芯片以外,还有很多的工作要做。”McVeigh说,“代码移植、性能、各种各样的事情,还有很长的路要走。”
值得一提的是,虽然Intel已宣布停止Pathfinder项目,但上个月Intel发言人提到,这一决定不会影响IFS相关业务开展和Horse Creek平台。其实此前Intel和SiFive一起推的Horse Creek还是挺受关注的——这是个高性能demo,本身是个RISC-V软件开发板。上面的RISC-V芯片据说用上了尚未大规模量产的Intel 4工艺,主体是SiFive P550核心;另外也是为了表现Intel自己的PCIe 5.0与DDR5 PHY和Synopsys控制器、其他第三方IP的互操作性。
Intel去年在演示这块板子的时候,还在上面跑了游戏和各种应用。而Horse Creek平台的问世,前提是Intel的IFS Accelerator生态联盟——这个项目主要是为了加速芯片原型设计和流片的;与芯片设计上游的EDA、IP和设计服务企业进行深度合作来做推进。
IFS Accelerator就是个综合工具套装,其中包含有经过了验证、针对Intel制造工艺的优化IP组合,比如说标准单元库、存储、GP I/O、模拟、I/F IP等。SiFive也是IFS Accelerator的成员之一,此前SiFive说:“SiFive会赋予客户构建RISC-V计算平台的能力,为其优化市场应用。Intel广泛的IP组合,对SiFive的高性能处理器IP做了补充。”

从“生态”上游的角度来看,芯片设计的相关工具与软件,以及foundry厂的配合支持,更是RISC-V这类新生架构需要面对的问题。而Horse Creek是一个代表性产品。Frank Schirrmeister说:芯片的最终表现绝不只是ISA甚至RTL层级的问题,“如果你去看各种IP,其成功一定是和物理工具、物理实现相关的。单说互联,也只是系统的一部分,需要IP与实施流程协同优化来达到对应的性能和功耗。”
BSC也说对他们而言至关重要的一点,是在整个链条上,了解如何把芯片做好-来自整个欧洲的支持;甚至将问题扩展到培养欧洲的人才和该区域内的半导体生态系统。这么看来,RISC-V及其生态发展的加速,还真是有全球半导体产业区域化和自主化的推力在的,绝对不只是中国。
至于生态下游,也就是大部分人所理解的基于RISC-V平台的应用开发生态,这已经是个老生常谈的话题了,其沉淀还是需要时间的。所以从不同层面的生态角度:芯片设计上游的工具完备情况、围绕芯片周边的系统设计生态,以及下游的应用开发生态,都是某个指令集或微架构平台能否在对应领域获得市场的重要组成。
包括ChatGPT在内的很多人说,某某指令集成功的原因在于其处理器成本低、效率高、性能强。这些自然都是处理器获得市场成功的外在表现。但这些本质上都离不开生态的发展。
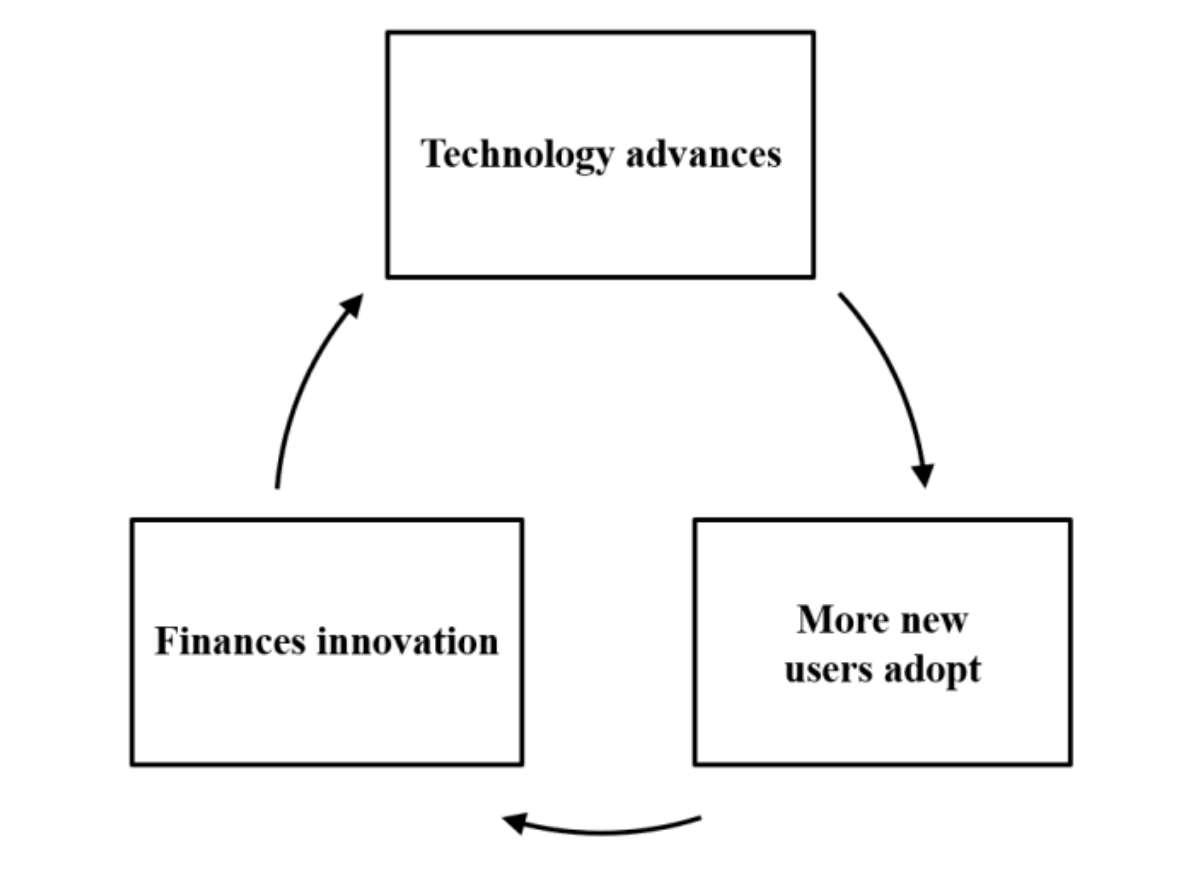
一般我们知道,通用计算芯片的发展有个良性循环三角:有用户会选择购买某种处理器,资金便开始进入到该处理器周边的生态,这些资金会让产品在技术方面做得更好;在产品得到提升以后,又会有更多的客户选择购买,并吸引下一轮资金…如此循环往复。
而生态、成本、性能/效率也是个循环:芯片出货起量产生成本效益,芯片赚钱才能促成了技术的进步——即芯片效率越好,效率越好则能促进整个生态的发展,生态发展越是促成芯片出货起量…如此循环往复。
生态、性能/效率、成本达成了相互促进的关系。如果走不进这样的良性循环,则很难把游戏真正玩起来。x86和Arm相继在高性能领域站稳脚跟,都是因为进入了这样的良性循环。
前文花了不少篇幅来谈生态——文首ChatGPT回答中提到的compatibility、support本质上都是在说生态。而“性能”前文也已经谈到了:基于名列前茅部分的探讨,性能和生态也是相辅相成的。
至于成本问题,体现在数据中心的TCO(总拥有成本)上,包含芯片与设备投入,对企业本身业务赚钱的直接影响,还有系统基础设施建设与维护、系统易用性、应用开发、场地租用、电费等能源开销等等的成本。在良性循环三角内,生态做得好,成本自然在降低。
现阶段探讨RISC-V的性能与效率,相较于Arm、x86的实际情况可能还为时过早,毕竟生态建设进度还早。业界普遍认为,RISC-V若要进驻高性能市场,仍有比较长的路要走。像SiPearl公司CEO Philippe Notton就认为RISC-V至少现在都不是高性能计算的可选项。
但我们前面列举的这些关键事件和既有产品,无论其中有多少变数(如Intel Pathfinder项目停止对于RISC-V生态而言的确很可惜)、企业是否诚实反映了产品实际情况(如P670的性能是否的确比肩Cortex-A78),都能表现RISC-V的生态建设之神速,的确是x86、Arm在生态建设初期难以比拟的。
而且我们认为,此事已有Arm珠玉在前,RISC-V自然就有机会。
说到性能和效率,有关Ventana的RISC-V核心就格外值得一提了。Ventana公司的Veyron VT1从宣传来看,每核性能据说是比肩于Arm Neoverse V系列的——也就是Neoverse中更高性能定位的系列——亚马逊Graviton 3和英伟达Grace分别基于Neoverse V1和V2。

Ventana在宣传中提到,CPU可选配较高128个核心,功耗<300W。如果宣传数据属实,则其性能水平可以比肩AMD Genoa。SemiAnalysis在最近的评论文章里说,就算按照宣传数据打八折来计,则其性能仍然超过了Intel至强Ice Lake和才刚刚见到影儿的Sapphaire Rapids。
据说Ventana接下来要推的VT2核心效率还能做到更高,尤其面积效益表现很出色——单位面积内的性能传言很好,则成本方面的收益也就更高了。与此同时,现有方案中与VT1搭配的IO die,已经用BoW实现chip-to-chip互联,1Tbps双向带宽,PHY-to-PHY连接延迟<2ns,传输能好效率达成<0.5pj/bit。(有兴趣的同学可以去了解一下Sapphaire Rapids采用EMIB封装方案后的这几个数据;此外,Ventana也是Intel IFS Accelerator项目的合作方之一)
这些宣传数据是的确比也当代采用先进封装的Intel、AMD服务器处理器要好的。关键其封装的触点密度似乎还并不高,不知道是用了什么奇技淫巧。也不清楚这些数据是否有较大水分。而且如前文探讨的,当算力要求再往上提的时候,考量数据中心的性能水平更在于整个系统,而不只是核心、芯片与封装层级这么简单——这还是要考察生态能力的。
Ventana还说自己在应用方面也准备充分,提前几年就已经在用SiFive的开发板做软件开发了…抛开这些不谈,Ventana的业务优势核心可能并不在于性能和效率,或者预想中可能前期也好不到哪儿去的应用生态,而在于定制性、灵活性或个性化。
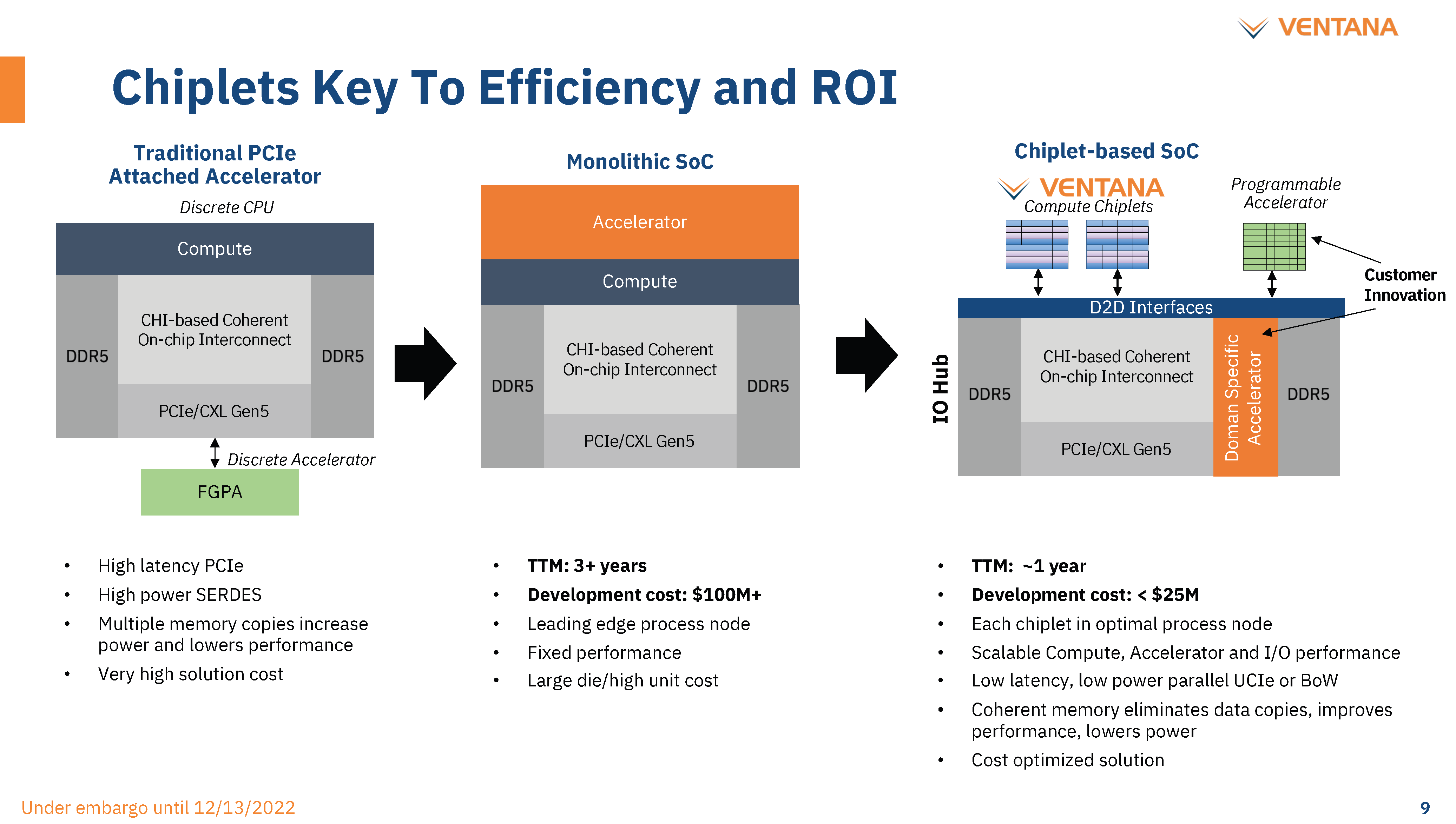
Ventana面向客户主要提供的是chiplet,而且本身似乎是不提供IO die的,IO die来自第三方或合作伙伴。这种不是出售整个芯片的方案,提供了大量可能性。比如光是IO die就可以采用现成方案,或者采用授权IP来自行开发。
下游客户完全可以集中精力去开发专用的加速器chiplet—加速单元可以直接集成进IO die。这种方案非常适合系统级企业,诸如亚马逊、阿里巴巴、腾讯、百度等,这些企业如今都倾向于自己造芯——上游的EDA、IP供应商前两年已经宣扬了一整年的这种趋势了。对于实现符合自身业务的芯片设计而言,包括汽车在内有高性能计算需求的系统级企业不再需要在CPU方向上重复造轮子,也对应地降低了很大一部分成本。
Ventana现阶段主要是用Open Compute Project的ODSA BOW标准来做封装,与此同时也计划在未来版本中实现对UCIe这个更具潜力标准的支持;chiplet/IO die都使用AMBA CHI协议。所以整体上还是体现出相对开放的灵活性。
这是AMD、Intel这类现在的市场霸主所不具备的,不光是因为业务营运方式差异,像Intel现在的处理器架构暂时也不支持这种卖货方式的实现。另外就是成本会低很多:尤其在芯片做出来以后,大量芯片部署到集群里,后续成本是递减的;这对系统级企业而言具备很大吸引力。
或许RISC-V所能达成的灵活性还不止于此,各层级的灵活性和定制性未来还有更大的潜力做挖掘。比如Schirrmeister说,集群需要很多处理器互联,“你需要考虑核心的可扩展性,也就是核心与互联的协同优化。RISC-V在这一层级给出了自由度,可能会比一些现有标准做得更好。当然这需要去做很多工作,也绝对不简单。”但这也让RISC-V在这一层级的生态发展有了不同的可能性。
这种灵活性,和随摩尔定律停滞、某些类别的数据中心芯片的定制化需求,是x86和Arm现阶段还很难达成的。而且RISC-V的这种灵活性还提供了更高的经济效益,针对应用和业务也有机会提供更高的性能。
像Ventana这样做定制方案的例子,在RISC-V生态内未来可能也会更加多样化。BSC与Intel的合作,此前也是着眼于把RISC-V核心做成chiplet。如此看来,chiplet、先进封装技术和异构集成,本身就是推进RISC-V这类具备高定制化可能性的CPU指令集发展的先决条件。
同时,进入到专用计算的时代,CPU未来在高性能计算领域可能仅作为控制器、愈发被边缘化,或者至少市场价值更多地被加速器拿走——很多研究机构未来几年的预测都给出数据中心服务器价值中,CPU的绝对主导地位会被加速器所逐渐取代。
那么针对特定工作进行定制,RISC-V自然更能在性能和效率上打败那些固化的、纯通用的CPU架构,即便这个过程所需的时间大概会很久,尤其软件和应用的移植工作不会很容易。

我们的探讨大致就只能止步于此了。能够给出的参考主要是RISC-V的生态建设速度飞快,无论是芯片设计相关的生态、围绕芯片的系统方案、应用生态;以及RISC-V当前符合时代发展主旋律,具备的灵活性特性可能有机会抢占特定的数据中心市场。
从行业支持的角度来说,由于电子产业发展的不确定性和产业链的区域化大趋势,RISC-V在全球范围内都得到了前所未见的支持力度。仅是HPC领域,RISC-V联盟都有个专门的SIG-HPC(高性能计算特别兴趣小组),也算是为RISC-V在HPC社区的发展做的努力之一。
虽然即便在搞RISC-V方向HPC研究的专家都说,RISC-V要应用于HPC这样的方向还需要好些年。数据中心其他门类的情况可能会各有差别;但其实从前文罗列部分市场参与者在高性能方向的努力来看,RISC-V在该市场上有着巨大潜力:而且越看越有占据天时地利人和全方位优势的样子。
文章来自:https://www.eet-china.com/







