fptree是如何压缩数据库的
常见问答
什么是FP-tree在数据压缩中的作用?
FP-tree是如何通过结构设计帮助压缩大量数据库中的频繁项集数据的?
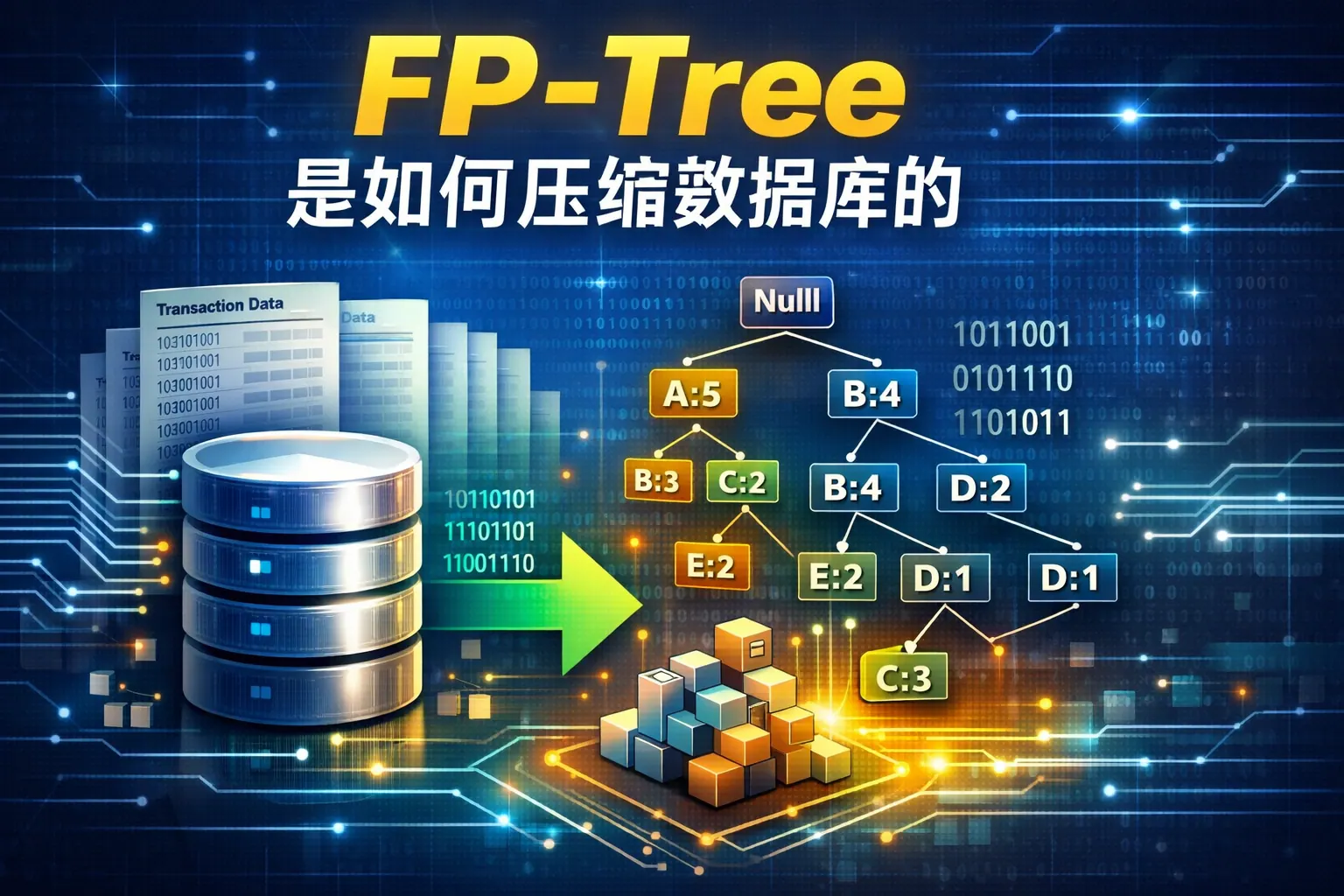
FP-tree通过紧凑的树结构压缩数据库
FP-tree通过构建一个前缀树结构,将数据库中具有相同前缀的项集合并存储,从而避免了数据的冗余存储。它按频繁项排序对数据进行扫描,并将共享部分的路径合并,极大地减少了数据库的存储空间需求。
FP-tree压缩数据库时有哪些关键步骤?
在创建FP-tree的过程中,数据库压缩涉及哪些具体的操作步骤来实现?
构造FP-tree的步骤实现数据库压缩
构建FP-tree时,首先是扫描数据库统计频繁项,接着对每个事务中频繁项进行排序,并将这些排序后的项插入到FP-tree中。每当事务的前缀与树中的路径重合时,共享路径上的计数器增加,而非重复存储,从而达到压缩数据库的效果。
使用FP-tree压缩数据库相较于原始数据库有何优势?
相比直接存储交易数据库,FP-tree压缩技术带来了哪些性能和存储上的改进?
FP-tree提高了存储效率并优化了频繁项集挖掘
FP-tree通过合并共享前缀减少了数据的重复存储,显著降低了存储空间需求。同时,它让频繁项集挖掘过程可以通过树结构高效遍历,避免了反复扫描数据库,从而提升了数据处理的速度和效率。
* 文章含AI生成内容