当一个对象在我们的代码中,看似已经没有任何变量再指向它(即“没有引用”)之后,其所占用的内存,有时,仍然无法被垃圾回收机制所回收,这一现象的根源在于我们所认为的‘没有引用’”与“垃圾回收器所判定的‘没有引用’”之间,存在着一个致命的“认知偏差”。一个对象能否被回收的唯一标准,是它是否“可达”。导致一个逻辑上早已“无用”的对象,在物理上,却依然“可达”的常见“元凶”主要涵盖:存在“逻辑上过期”但“物理上可达”的隐性引用、被全局或静态集合所持有、闭包的无意捕获、未被注销的事件监听器或回调函数、以及循环引用(在某些旧的回收机制中)。
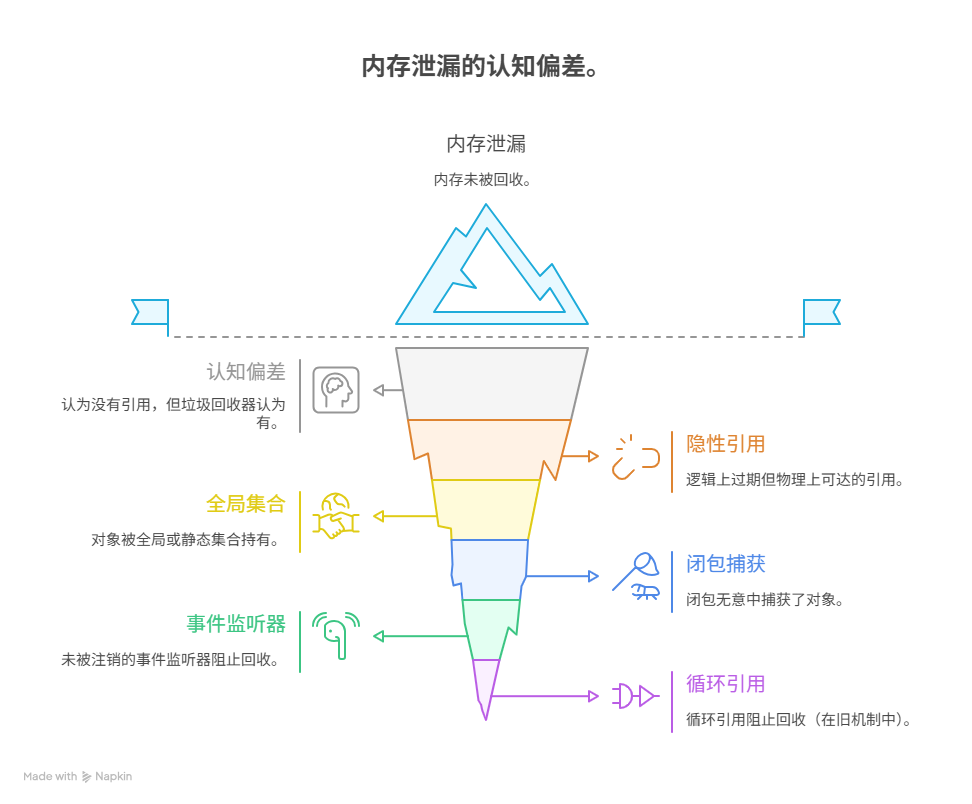

其中,存在“逻辑上过期”但“物理上可达”的隐性引用,是所有此类问题的本质。这意味着,尽管在我们的业务逻辑中,这个对象已经完成了它的历史使命,但因为在代码的某个被遗忘的角落,还存在着一个“活的”引用指向它,导致垃圾回收器在进行可达性分析时,依然认为它是一个“存活”的对象,从而永远无法将其判定为“垃圾”并进行回收。
一、基础原理、重新理解“垃圾”
要解开这个谜题,我们必须首先,深入地,理解现代编程语言中“自动内存管理”的核心——即垃圾回收机制,特别是它“如何定义‘垃圾’”这一根本性问题。
在一个程序运行的过程中,内存的管理,主要包含三个基本步骤:首先是分配内存,用于存储新创建的对象和数据;其次是使用内存,即在代码中,对这些对象和数据,进行读取和修改;最后,也是最容易出问题的,是释放内存,即当一个对象不再被需要时,将其所占用的内存空间,归还给系统,以供后续使用。
在具有自动垃圾回收机制的语言中,“释放”这个动作,是由一个被称为“垃圾回收器”的系统进程,来自动完成的。它的核心工作,是周期性地,对内存进行一次“大扫除”,找出并清理掉所有不再需要的“垃圾”。而它判断一个对象,是否是“垃圾”的唯一标准,并非是“这个对象有多久没被访问了”,而是“这个对象,是否,仍然是‘可达的’”。
这个“可达性分析”的过程,可以理解为一次从几个固定“起点”出发的“寻宝游戏”。这些“起点”,在垃圾回收的语境中,被称为“垃圾回收根”。它们是程序中,那些被先验地,认定为“必然存活”的变量,主要包括全局变量、以及当前所有正在执行的函数的调用栈中所引用的局部变量和参数。垃圾回收器,会从所有这些“根”出发,沿着对象之间的“引用”关系(例如,A对象的一个属性,指向了B对象),去遍历整个堆内存中的所有对象。所有能够,从“根”出发,最终被访问到的对象,都会被标记为“存活”对象。而当这次“大扫描”结束后,所有未被标记的对象,则被确认为“不可达”的,即“垃圾”,并将在稍后,被统一回收。
理解了“可达性分析”后,我们就触及了问题的本质。垃圾回收器,是一个极其忠实的“关系”追溯者,但它,绝非一个能理解你“业务意图”的“智能体”。一个对象,在你的业务逻辑中,可能已经“寿终正寝”,你期望它被回收。但是,只要在整个程序的内存网络中,还存在着任何一条,能够从某个“根”出发,最终链接到它的、未被切断的“引用路径”,那么,在垃圾回收器眼中,它就依然是“可达的”、“存活的”,从而,永远不会被回收。我们所遇到的,几乎所有的内存泄漏,都是由这条“被遗忘的”或“意外产生的”引用链所导致的。
二、元凶一、全局与静态变量
静态变量(或全局变量),是“垃圾回收根”集合的重要组成部分,其生命周期,与整个应用程序的生命周期一样长。因此,任何被静态变量,所直接或间接引用的对象,都将“永生不死”,直到程序退出。
这是一个在后端开发中,极其经典的内存泄漏模式。开发者,为了方便,或者为了实现一个简单的进程内缓存,而使用了一个“静态的集合”,例如,一个静态的哈希表或列表。当代码,向这个静态集合中,添加了一个对象引用后,这个对象,就通过“静态变量 -> 集合对象 -> 被添加的对象”这条引用链,与一个“根”,建立了牢固的连接。
如果这个集合,只进行“添加”操作,而缺乏一个有效的“过期”或“移除”机制(例如,在用户会话结束时,没有从一个静态的在线用户列表中,移除该用户对象),那么,这个静态集合,就会像一个“只进不出”的容器,持续地,在内存中,堆积那些早已“逻辑过期”的对象,最终,必然导致内存溢出。
三、元凶二、闭包与作用域链
闭包,是现代编程语言(特别是JavaScript)中,一个极其强大的特性,但同时,它也是一个最常见的、也最隐蔽的内存泄漏的“制造者”。
一个闭包,是指一个函数(通常是内部函数),能够“记住”并持续访问其被定义时所在的、那个“外部函数”的作用域中的变量,即便外部函数,已经执行完毕。这个特性,使得闭包,能够“捕获”并“延长”其外部作用域中变量的“生命”。
让我们来看一个经典的闭包泄漏示例。假设我们有一个函数,它在内部,创建了一个占用大量内存的局部变量(例如,一个巨大的数组),同时,也创建了一个内部函数(即闭包),这个内部函数,在其作用域链上,引用了那个大数组。然后,这个外部函数,将这个“内部函数”,作为“返回值”,返回了出去。如果在程序的其他地方,一个全局变量,或另一个长生命周期的对象,持有了这个被返回的“内部函数”的引用。那么,灾难就发生了。
因为,那个全局变量(一个“根”)引用了内部函数,导致内部函数,被判定为“存活”。而内部函数,因为闭包的机制,又强引用着那个本应,随着外部函数执行结束而被销毁的“巨大数组”。最终的结果是,这个巨大的数组,因为这条从“根”出发的、未被切断的引用链,而永远无法被垃圾回收器所回收,造成了严重的内存泄漏。
四、元凶三、事件监听器与回调
这与闭包的原理类似,主要发生在事件监听和发布-订阅模式中,是前端开发中,最常见的内存泄漏场景。
其基本模式是,一个“短生命周期”的对象(例如,一个临时的、用于展示某个详情页的“子组件”),向一个“长生命周期”的对象(例如,一个“全局”的、用于消息派发的“事件中心”服务),“订阅”了一个事件。这个“订阅”的动作,在底层,实际上,就是在那个“长生命周期”的对象内部,创建了一个指向“短生命周期”对象的强引用。
当用户,离开这个详情页,导航到其他页面时,这个“子组件”的实例,在逻辑上,已经被“销毁”了。然而,如果,我们在“子组件”被销毁时,忘记了,去执行一次“取消订阅”的操作,那么,那个“全局”的“事件中心”的内部,在其“订阅者列表”中,就依然,会永久地,持有着,对这个本应被销-毁的“子组件”的引用。这就造成了内存泄漏。随着用户在应用中不断地导航,这些“死而不僵”的“订阅者”组件,就会越积越多。
五、诊断与预防、系统性的“内存保健”
要与这些隐蔽的“内存幽灵”作斗争,我们需要一套“诊断”与“预防”相结合的“系统性保健”方案。
在诊断方面,内存分析器,是发现问题的最强大工具。通过使用像Chrome浏览器的开发者工具中的“内存”面板(对于前端),或像VisualVM(对于Java)这样的工具,我们可以对程序的“堆内存”,进行“快照”。通过在程序运行的不同时间点,生成两份或多份堆内存快照,然后,对它们进行对比分析,我们就可以清晰地,看到,是哪些类型的对象,在持续地、只增不减地,占据着内存。然后,再利用分析器提供的“支配树”或“持有者”视图,我们就可以,像侦探一样,沿着这些“可疑”对象的“引用链”,向上追溯,最终,定位到那个导致它们“无法被释放”的“罪魁祸首”。
在预防层面,则需要将“内存意识”,融入到团队的日常流程和规范中。首先,代码审查是一个重要的环节,审查者应特别关注那些可能导致资源不被释放的“高危”代码模式。其次,团队应建立一条铁的编码规范,即资源管理的“配对”原则:任何一种“申请”或“订阅”资源的操作,都必须有一个明确的、与之配对的“释放”或“取消订阅”的操作,并且,这个“释放”操作,必须被放置在一个能够被“保证执行”的代码块中。最后,压力测试也是必不可少的环节,通过在项目发布前,进行长时间的、高负载的压力测试,是提前暴露那些“缓慢的、不易察觉的”内存泄漏的、最有效的手段。
在实践中,当一个严重的内存泄漏,被定位和修复后,应将其,作为一个案例,沉淀到团队的知识库中。同时,应在 研发管理工具中,为这类缺陷,打上专门的“内存泄漏”标签,以便于后续,进行专题的统计和复盘,从中,发现团队在编码习惯上的“共性”问题,并进行针对性的培训和流程改进。
常见问答 (FAQ)
Q1: 什么是“垃圾回收的根”?
A1: “垃圾回收的根”,是可达性分析算法的“起始点”集合。它们,是那些被程序,先验地,假定为“必然存活”的对象。最主要的“根”,包括全局变量、以及当前所有正在执行的函数的调用栈中所引用的局部变量和参数。
Q2: “循环引用”一定会导致内存泄漏吗?
A2: 不一定。在现代的、基于“可达性分析”的垃圾回收机制中(如Java, JavaScript),如果一个“循环引用”的“小团体”(例如,A引用B,B引用A),其自身,已经与所有的“根”对象,都“失联”了,那么,这个“小团体”,作为一个整体,会被判定为“不可达”,并被一同回收。只有在一些非常古老的、基于“引用计数”的垃圾回收机制中,循环引用,才是必然的、无法被解决的内存泄漏。
Q3: 我手动将一个对象的引用设置为null,它会立即被回收吗?
A3: 不一定。将一个变量,设置为null,只是切断了“这一条”引用路径。如果,内存中,还存在任何其他的引用链条,能够访问到这个对象,那么,它就依然不会被回收。内存的回收,是由垃圾回收器,在其自己决定的、合适的时机,自动进行的,我们无法,也无需,去精确地控制其“立即”执行。
Q4: “内存泄漏”和“栈溢出”有什么关系?
A4: 两者是两种完全不同的内存问题。“内存泄漏”,发生在“堆”内存上,它是一个缓慢的、持续累积的过程,最终,可能导致“内存溢出”。而“栈溢出”,则发生在“栈”内存上,它通常,是由“无限递归”或过深的函数调用,所导致的、一个瞬间的、快速的崩溃。
文章包含AI辅助创作,作者:mayue,如若转载,请注明出处:https://docs.pingcode.com/baike/5215046
