











由全球电子技术领域知名媒体集团AspenCore主办的“中国国际汽车电子高峰论坛”于2023年2月23日正式拉开帷幕。会上,NVIDIA(英伟达)中国区软件解决方案总监卓睿分享了题为“超级算力,赋能整车中央计算”的主题演讲。

在无人驾驶或者说整车域控制器的演变过程中,整车域控制器的数量在逐渐减少,随着大算力芯片的出现,用单独的ECU(电子控制单元,又称“行车电脑”)就可以处理从前需要多个ECU才能实现的功能,例如行泊一体,以前ADAS(车辆高级驾驶的辅助系统)功能和泊车功能需要单独的控制器进行控制,而今只需要一个控制器就可实现。随着大算力芯片时代的到来,也许在将来我们只需要一个或两个中央处理器就可以覆盖整车所需的大部分功能。
如今Orin芯片正在被国内大部分的车厂、Tierl-1合作伙伴所使用,广泛应用在无人驾驶或者智能驾驶领域。跟前一代30TOPS算力的Xavier相比,Orin芯片拥有254TOPS的算力,算力提升了八倍多。对于车厂和Tierl-1来说算力更大的芯片可以让他们集成更多的功能降低各种成本,比如传感器成本、研发成本、OTA成本、BOM成本等。

例如,如果需要实现驾驶员监控、停车、标准的ADAS、环视等多个功能,往往需要将4-5个ECU集成在一起,同时每个ECU还有不同的传感器,每个ECU还需要单独做OTA的升级。现在由于Orin拥有足够的算力,可以把所需的传感器全部接在Orin上,可以大大降低BOM的成本、功耗研发成本、OTA成本。可以说大算力的Orin芯片为域控制器带来了翻天覆地的改变。
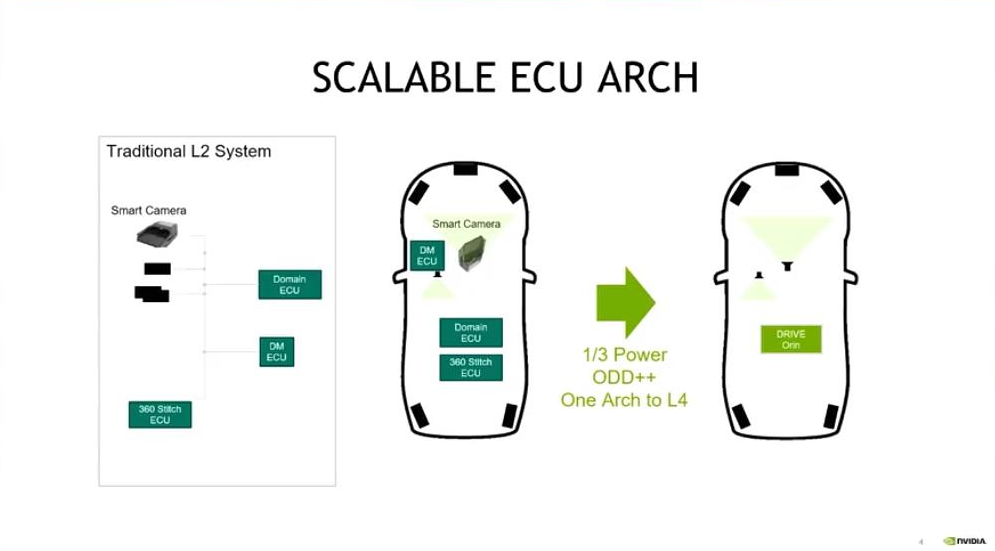
Orin在无人驾驶领域的成功不只是因为有254TOPS的算力,更是因为它是异构的处理器,有着非常平衡的算力均衡,比如有强大的CPU能力、GPU能力,还有其他针对CV算法处理的能力,因而可以为开发者或者OEM赋能,开发均衡且能满足现在L2、L2++需求的平台。
THOR是一款性能十分强劲的芯片,有770亿颗晶体管,算力达到2000TOPS,且具有8位浮点(FP8)功能。目前Transformer(一种神经网络,通过跟踪序列数据中的关系来学习上下文并因此学习含义)在NLP(自然语言处理)非常流行,业界也把Transformer引入到了CV (计算机视觉)之中,THOR中的FP8格式主要就是为了支持Transformer。

而除了标准的ADAS支持,THOR更多的是想支持中央处理大脑(CCC方案),英伟达通过MIT技术把GPU进行物理隔离,比如芯片有200TOPS算力,可以通过该技术将一部分给无人驾驶域做无人驾驶,另一部分给座舱域去做渲染。同时英伟达的软件也做了进一步的虚拟化,用NVlink接口连接两个芯片传输,该接口比P+1速度更快,性能更高。

当然仅仅只有芯片是没有办法实现量产的,不同的芯片厂商需要提供完善的软件解决方案,让开发者可以更容易的做开发工作。目前的Orin方案已经比较成熟,包括提供标准API访问硬件资源,支持不同的OS如LINUX、Android,功能安全、信息安全等方面也比较完善。
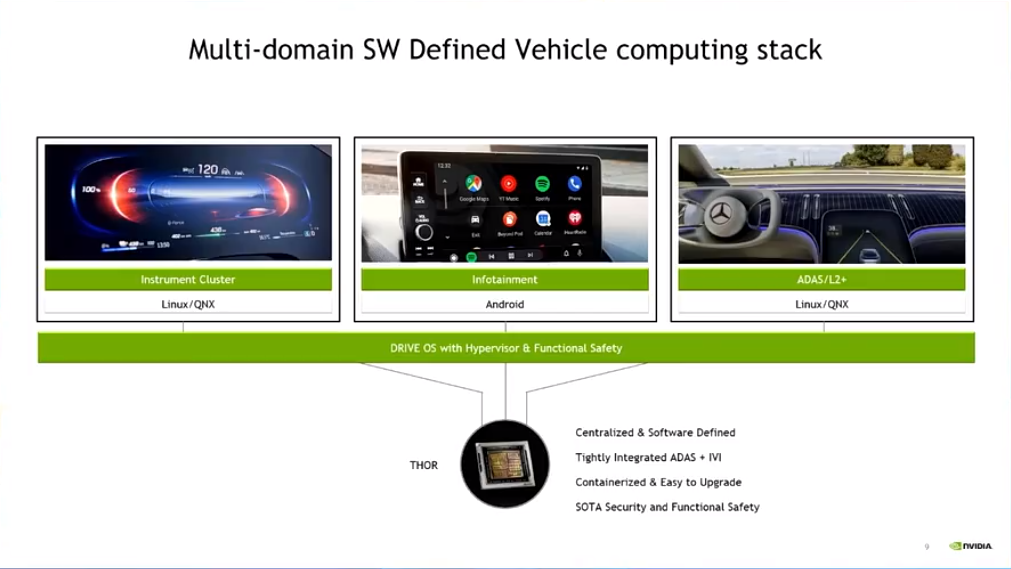
而对于THOR的软件架构,因为英伟达的虚拟化和SOI做的比较完善,可以在芯片上运行自己的Hypervisor,因此可以对CPU,GPU或者其他IO进行虚拟化。在这基础上,如果针对CCC方案,THOR可以支持座舱部分使用Android,仪表部分支持LINUX或者QNX,无人驾驶部分也可以支持LINUX或者QNK,可选择不同的configure进行针对配置。
对于深度学习领域,英伟达认为即使两家公司的产品拥有一样的TOPS,但并不意味着这两家公司的产品就拥有相同的性能,因为不同的架构会带来不同的作用。现在AI芯片有几大架构,GPU、ASIC、DSP。GPU是最灵活的,可以编程,DSP相对灵活一些。ASIC则完全固化。加之无人驾驶行业的算法还在不停的演进,之前传统的CNN算法如果跟现在的Transformer比已经落后了,算法在不停的迭代,所以一个可以编程的AI芯片在现阶段是非常有用的。

AI芯片的可编程,一方面是要可以编程,另一方面是要确定用什么样的接口进行编程。英伟达从2006年开始开发了CUDA SDK,无论是DGPU、大卡,还是Orin芯片,CUDA的接口基本上是一致的,所以熟悉CUDA的开发人员可以很容易的在英伟达嵌入式平台上进行开发。
CUDA作为一个对GPU底层的SDK接口,不论是Transformer还是传统的CNN算法,这些大模型通过CUDA都可以很容易的传输到平台上面。从性能的角度出发,从内存使用的角度来看,对于嵌入式,Framework更多的是做训练,在这上面可以支持不同的训练平台,而这些都可以非常容易的在英伟达平台落地。
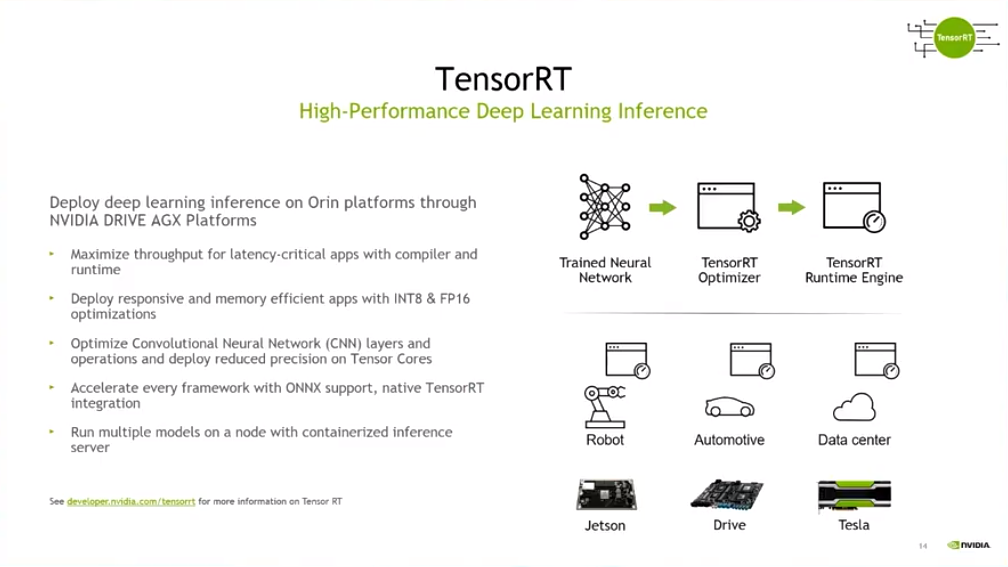
最后卓睿表示,相较于算力,实际性能更具有说服力。英伟达具有多种SDK包括编译器,除了深度学习相关的SDK以外,英伟达还有NVmedia,此外不管是要搭建pipeline,还是要获取数据,或者需要跨线程、跨进程、跨VM之间的数据传输,英伟达提供了一系列生态的SDK,可以做到非常快速的迁移。
本文授权转载自《电子工程专辑》姊妹媒体《电子技术设计》
文章来自:https://www.eet-china.com/







