











随着人工智能(AI)在嵌入式计算中的到来,导致了潜在解决方案的激增,这些解决方案旨在提供高速流视频上执行神经网络推理所需的高性能。尽管许多参考需求(如ImageNet)的分辨率都相对较低,从而通过多种嵌入式AI解决方案均可实现,但零售、医疗、安全和工业控制领域的许多真实应用,则需要能够处理的视频帧和图像分辨率会高达4kp60,甚至更高。
可扩展性是至关重要的,但对于仅提供主机处理器和神经加速器固定组合的片上系统(SoC)平台来说,这并非总是任意可选。尽管通常在原型建模期间,也提供了一种评估不同形式神经网络性能的方法,但这种一体化的实现方案缺乏真实系统通常所需的粒度和可扩展性。在这种情况下,工业级AI应用受益于一种更平衡的架构,其中将多个异构处理器(如CPU、GPU)和加速器结合起来,在一个集成的管道中共同协作,不仅能对原始视频帧执行推理,而且还能利用预处理和后处理对整体结果或处理格式转换进行优化,从而能够处理多种类型的摄像头和传感器。
经典的部署场景在于智能相机和边缘AI设备。对于前者,需要将视觉处理和神经网络推理支持功能集成到主相机电路板中。相机可能还需要执行一些其他任务,例如计算房间中的人数,并且能够避免在被拍摄对象进出视野时对其进行两次重复计数。智能相机不仅必须能够识别人,而且还必须能够根据相机已经处理的数据重新识别人,从而不会重复计数。这就需要一个灵活的图像处理和推理管道,其中应用程序可以处理基本的对象识别以及复杂的基于推理的任务,如重新识别。
通常,在智能相机设计中,主机处理器将传感器输入转换成适合推理的形式,包括:对数据帧进行调整、裁剪、以及标准化,使其适合于进行高吞吐率推理。一个类似但更高集成度的用例是边缘AI设备。该设备需要处理来自多个联网传感器和相机的输入,故需要具备同时处理多个压缩(或编码)视频流的能力。在这种多相机场景中,处理能力必须能够扩展,以处理执行推理所需的格式、颜色空间和其他转换,并且能够处理多个并行推理。
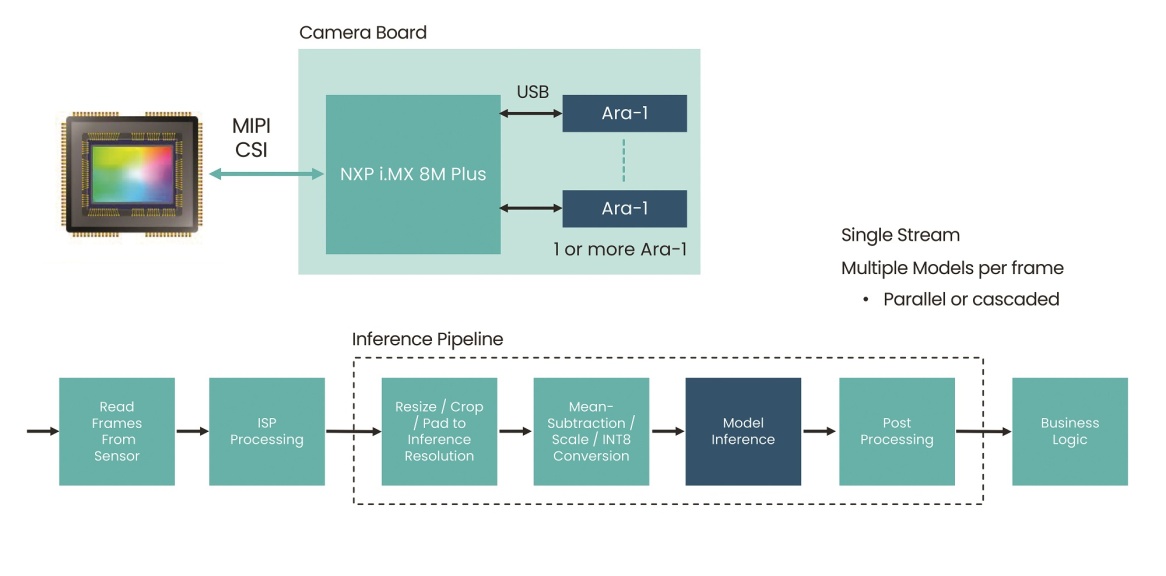
图1:智能相机应用业务流示意图。(本文图片来源:Kinara)
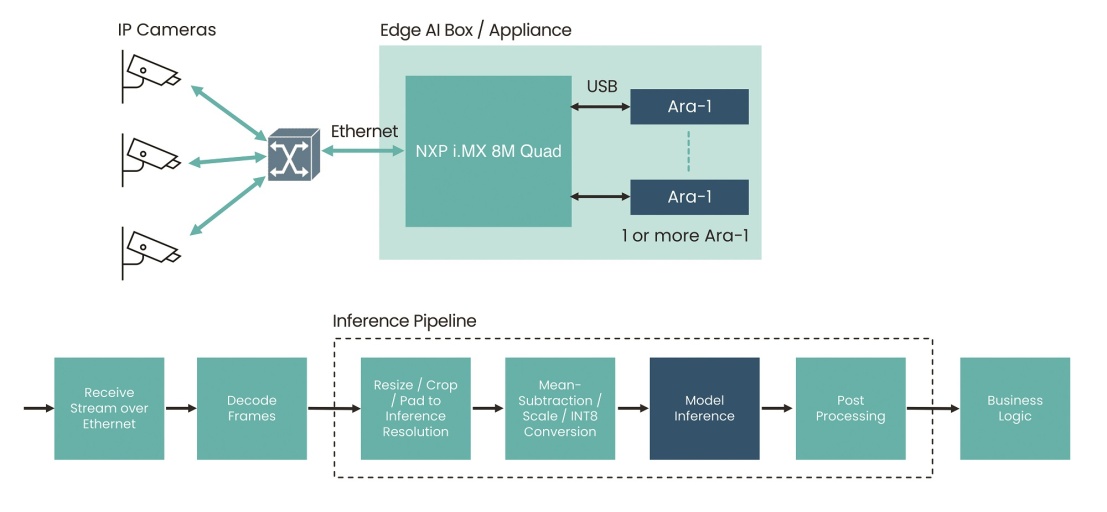
图2:边缘AI应用业务流示意图。
尽管固定的SoC实现方案能够处理特定用例,但基于可扩展性方面的需求,目光还是转向了具备扩展能力的平台,由于这些平台能够满足不同需求、并随着因客户需求变化所导致的可扩展性和升级提供内在支持。因此,重要的是要关注那些能够轻松扩展硬件功能的平台,这样,当利用不同架构的特定设备需求产生变化时,就无需对代码进行太大更改。因为很少有人能负担得起这其中所暗含着的移植开销。
由于NXP和高通公司等供应商在性能、功能和价格方面所提供的众多选择,许多开发人员都采用了他们的嵌入式处理平台。例如,NXP i.MX应用处理器就满足了广泛的性能需求。与固定SoC平台不同,NXP的处理器系列得益于许多嵌入式计算市场所必需的供应商长期支持和供货保证。i.MX 8M等器件为边缘AI设备需求提供了良好的基础。其内置的视频解码加速功能,使其能够在一个处理器上支持4个压缩的1080p视频流。通过i.MX应用处理器与Kinara的Ara-1加速器的配合,可以实现对多个视频流进行推理或具备处理复杂模型的能力。
主处理器中,每个加速器可以在每个无切换时间和零负载的帧上运行多个AI模型,从而提供实时执行复杂任务的能力。与一些为最大吞吐量而依赖于多帧批处理的推理管道不同,Ara-1针对1个批处理以及最大响应性,进行了专门优化。
这意味着,如果加速器正在对另一帧或一帧的一部分执行推理,则智能相机设计不需要依赖主处理器来执行重新识别算法。两者都可以卸载到Ara-1上,以利用其更高的速度。在需要更多性能的地方,例如在边缘AI设备中,不同的多种应用可能都需要执行推理任务,此时可以并行使用多个加速器。
不仅通过支持智能相机或设备PCB上的芯片向下集成,而且还支持插件升级,从而可以实现更高的可扩展性。对于芯片向下集成,Ara-1支持行业标准和高带宽PCIe接口,以便轻松连接到包含PCIe Gen 3接口的主处理器。第二个集成路径是利用可以直接插入可升级主板的模块,利用PCIe接口并提供处理多达16台相机输入的能力。对于一些使用现成硬件的系统和原型,还有另外一种选择,就是内在支持USB 3.2。利用简单的电缆连接,可以在笔记本电脑上测试AI算法,利用硬件评估包启动生产,或对现有系统进行简单升级。
开发人员可以选择多种方法来简化加速器与处理器及其相关软件堆栈的集成。对于模型的部署和管理,在运行时利用C++或越来越流行的Python应用程序编程接口(API),运行环境为Arm的Linux环境或x86的Windows环境。Kinara的运行时API支持多种命令,包括加载和卸载模型、传递模型输入、接收推理数据以及推理和硬件设备的所有控制。
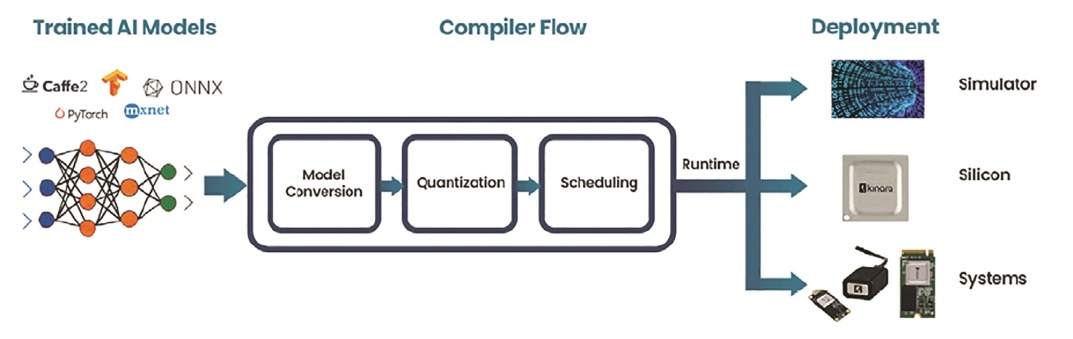
GStreamer环境提供了访问加速器性能的另一种方式。作为一个为构建媒体处理组件的计算图形而设计的库,GStreamer可以很容易地实现过滤管线,这些过滤器可以植入能够对导入视频和传感器馈送状态的变化做出反应的一些更复杂应用中。
对于AI推理,Kinara等SDK可以采用多种不同形式的训练模型,包括TensorFlow、PyTorch、ONNX、Caffe2和MXNet,并直接支持YOLO、TFPose、EfficientNet等数百种模型以及变压器网络。从而提供了一个完整的环境来优化性能,手段包括利用量化、利用自动调整确保模型精度的保持、并在运行时调度执行。有了这样的平台,就有可能深入理解模型的执行,以促进性能优化和参数调整。工程师可以利用精确的仿真器,在硅片实施之前对性能进行评估。
总之,随着人工智能成为越来越多的嵌入式系统的组成部分,能够将推理功能集成到广泛的平台中来满足不断变化的需求是非常重要的。这意味着能够部署具有相关SDK的灵活加速器,从而允许客户将高级AI加速与已有或新的嵌入式系统结合起来。
(参考原文:Using edge AI processors to boost embedded AI performance)
本文为《电子工程专辑》2023年3月刊杂志文章,版权所有,禁止转载。点击申请免费杂志订阅
文章来自:https://www.eet-china.com/







