











ChatGPT的持续火爆,也引起了人们对另一个问题的担心,那就是碳中和、碳排放问题。据分析,自2022年11月30日上线以来,运行仅60天,ChatGPT的碳排放就超过了800吨二氧化碳。在这个过程中主要的碳排放在于AI模型的训练,这种训练依赖的是大量的处理器运算。那么怎样在处理器运算端减少碳排放,构建碳中和的可持续未来呢?
3月29日,在第二届“碳中和”暨绿色能源电子产业可持续发展高峰论坛上,Graphcore大中华区总裁卢涛先生以“如何使用IPU构建更加绿色的AI助力碳中和的可持续未来”为主题,介绍了怎样通过新型的处理器架构——IPU来加快运算速度,提升每瓦效能,减少碳排放。

卢涛先生毕业于华中科技大学人工智能与自动化学院,在芯片领域拥有20多年的经验,现任Graphcore大中华区总裁,同时是执行委员会成员,全面负责Graphcore在大中华区的业务,以及Graphcore在全球范围营收策略的制定和执行。
在加入Graphcore之前,卢涛先生曾任Cavium总经理,作为当时的零号员工领导Cavium在中国的业务,直至Cavium IPO,在被Marvell收购之后,卢涛加入Graphcore,成为Graphcore在中国的零号员工,领导中国业务迅猛发展。现在,他正在通过全球营收策略的制定,帮助Graphcore全球业务快速增长。
演讲开始,卢涛先生分享了几组数据。
名列前茅个数据是从《未来简史》这本书里面节选的,石器时代的时候,人类每人每天消耗只有4千卡的热量,当时写这本书的时候是1617年;今天美国人平均每天需要消耗22.8万卡路里的热量。第二个数据是,现在ChatGPT从能源的角度,把一个ChatGPT算法模型的全生命周期从训练最后到部署,总共期间消耗的碳规模大概会超过814吨的碳排放。我们平时开的家用汽车,如果按1.6升的发动机,一年1万公里,一年的碳排放是2.7吨,ChatGPT排放的814吨碳相当于三百辆汽车一年的总量。而一辆汽车一年排放的2.7吨二氧化碳,大概需要1.5亩的人工森林来中和。所以这对碳排放是非常非常可观的。
然而,ChatGPT还只是刚刚开始,现在的训练模型具有1750亿个参数,未来将会有万亿、十万亿、百万亿,甚至更多的参数,按照OpenAI CEO所说,每18个月会提高一倍的智能。同时,从2016年AI开始爆发起,AI的算法模型的参数规模,每3个月提高一倍,模型大小的提升意味着更多AI的算力。
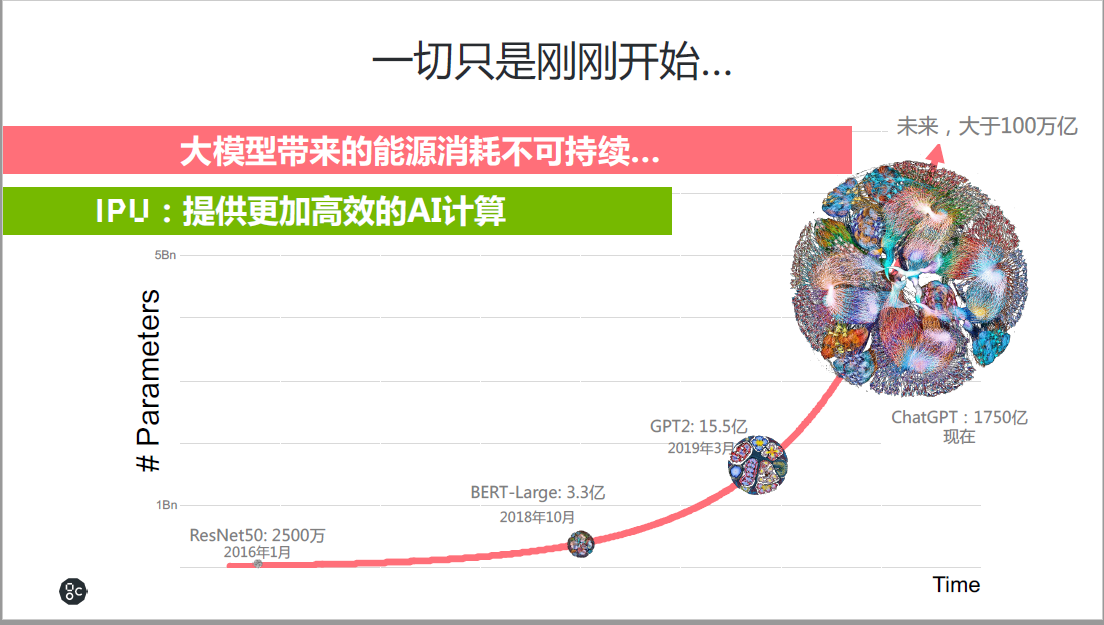
因此,有一个问题,大模型带来的能源消耗是不是可持续的?
“同时,我们在构建IPU的时候,如何从高效能的角度来考虑产品。这是我们当时在架构IPU的时候主要考虑的点。” 卢涛先生进行了介绍。
最近业界一直怀疑摩尔定律是不是停滞了,但如果从65NM到14NM看,用因特尔的至强芯片看,每个芯片每年有30%的晶体管数量的提升,但是每瓦的性能提升的能效却只有15%。
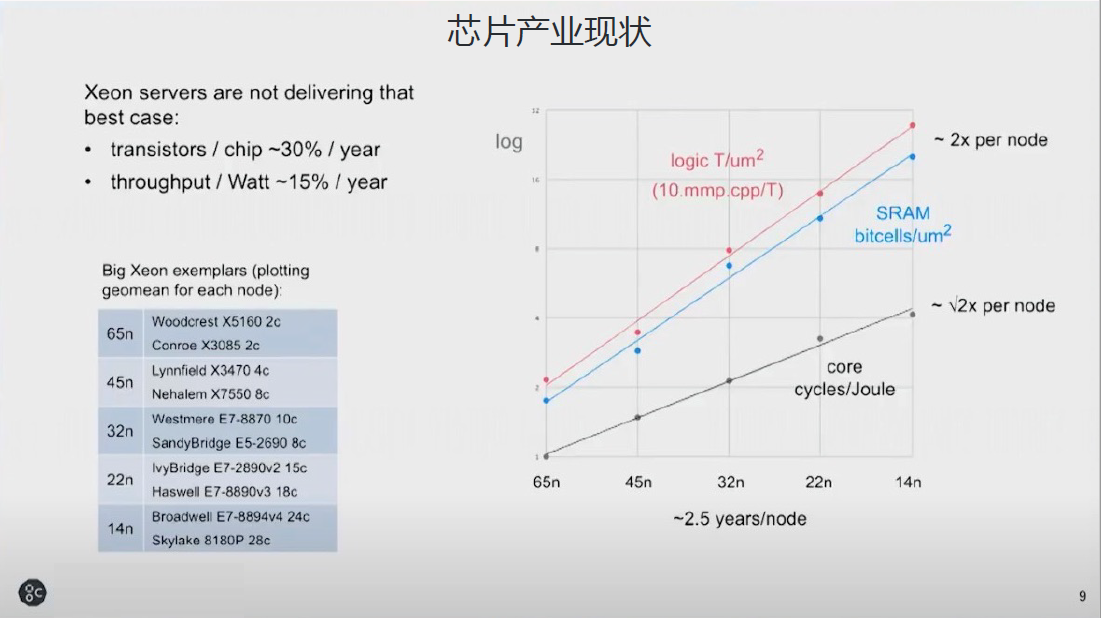
围绕着我们所做的AI计算,也有一些自己的特点。下面几页是我们当初设计IPU时候拿的数据,今天我们最新的7NM或者3NM的时候,数据稍微有一些差异,但是原理还是这样的。如果我们做fp16.32,每平方毫米是250如果fp32是60,fp64就只有15,在当时一个800平方毫米上,其实最后大概有将近70%以上的硅,运行的时候发挥的效能是非常非常有限的。所以这个是名列前茅组数据,在不同的数据精度的时候,我们同样的面积可以提供什么样的能力。
在做计算时,不管是AI计算还是通用计算,在桌面笔记本、服务器、CPU里面,甚至是手机的CPU里面,中间还有一个特别大的能量消耗大户,是把数据从内存搬到计算核心里面,不同的内存介质也非常不一样,如果是DDR4的内存,从内存搬到计算核心是320pj/B,如果HBM2或者HBM3,有一定的提升,是64或者10pj/B。SRAM会有更大的提升,他们会达到1pj/B,获得的内存访问带宽也非常不一样。
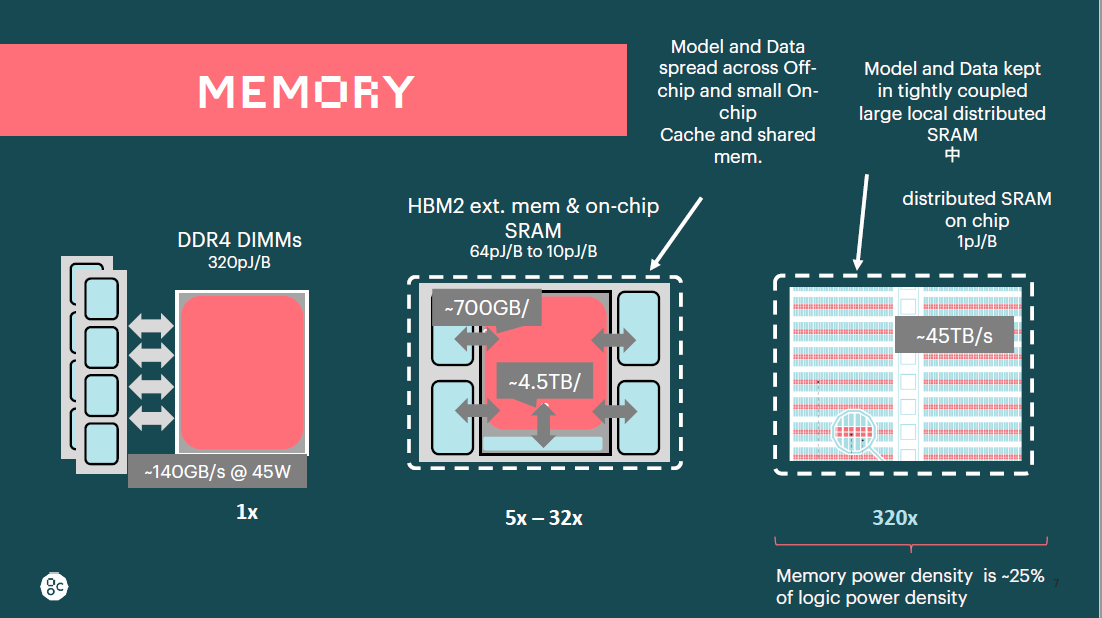
不同的数据类型在晶体管方面的能耗占用情况是不同的。
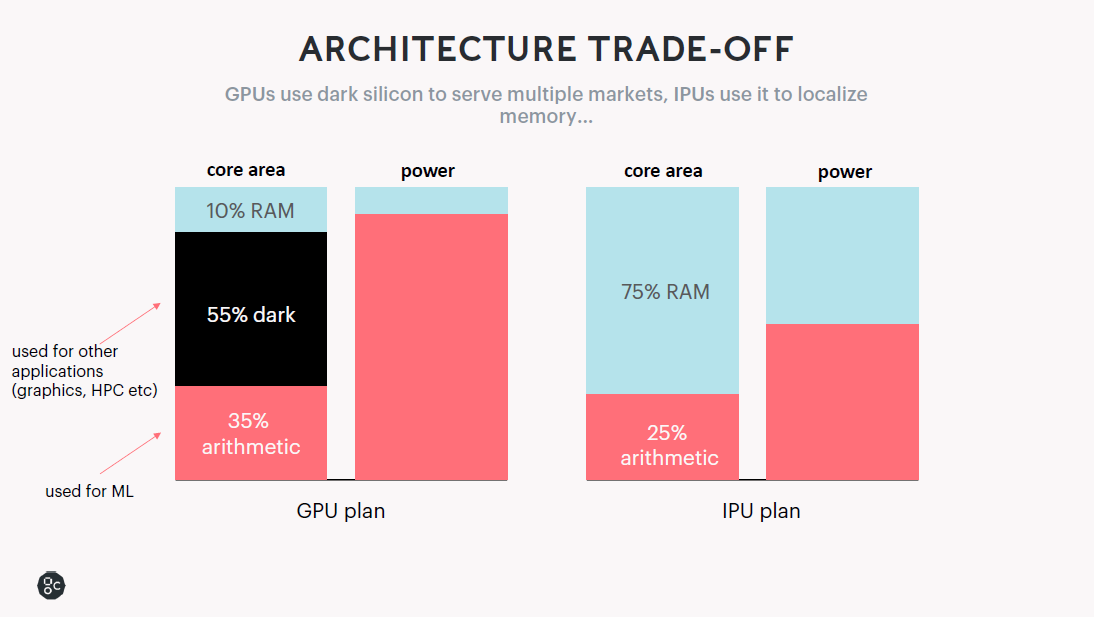
从一个典型的GPU架构来说,从处理器的面积分布可以看到10%的功耗用在芯片中的RAM,35%用在机器学习的运算单元,55%用在暗硅。从GPU的计划看也没有浪费,把这些晶体管拿出来做一些图形和运算,最后从能耗上的分布可以看到,10%的RAM晶体管数量消耗的功耗小于整体功耗的10%,同样的晶体管如果用于运算和存储,其功耗表现是非常不一样的,大概就是4:1到3:1的比例。
而对于IPU架构来说,选择在芯片中25%的面积用于运算,75%的面积用于存储。最后从功耗的分布表现,50%用在存储上,50%用在运算上。
因此,同样的晶体管数量,IPU架构相比GPU架构的功耗产生的性能更高,也就是每瓦性能要高。
在AI与计算大爆发的新时代,到底什么才是高效能的半导体产品。
半导体的效率取决于是不是完全把可用的性能百分之百利用了,能够利用就是效率很高。其中有两种策略,一种是并行,另一种是串行。
并行是计算和访存的时候进行并行处理,现实情况是,实际场景中功耗无法满载运行,表现为设计的算力指标与实际运行指标不符,比如设计100T的算力,实际上大部分运行的时候,只有75T。
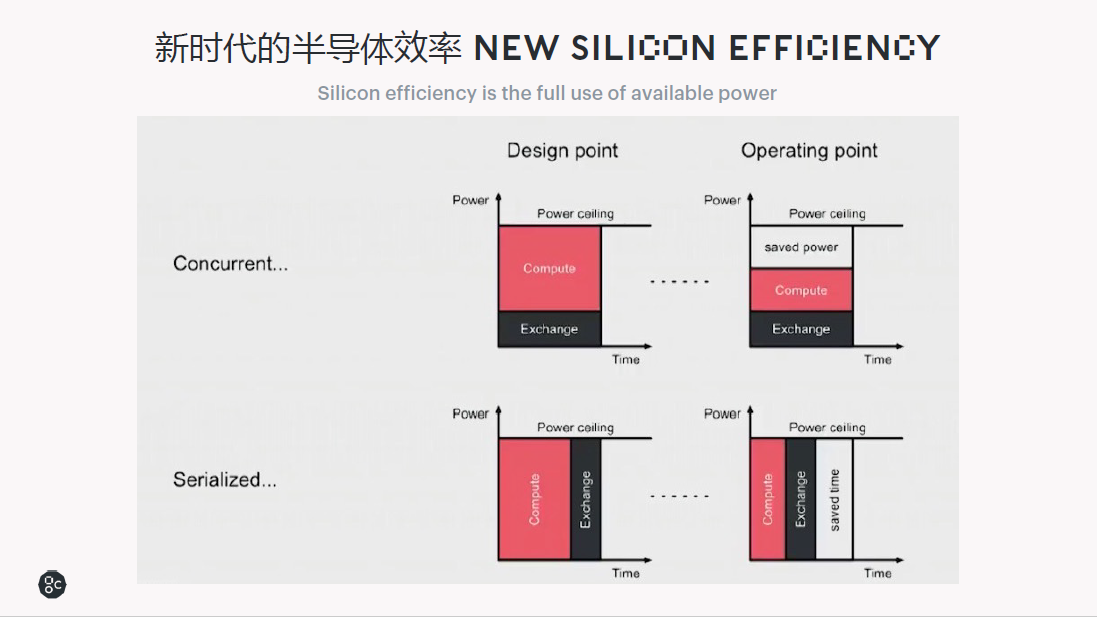
如果用串行机制进行计算和访存,则可能把芯片的性能百分之百利用起来,这时芯片消耗的能源或者功耗,可以实现运行效率达到设计的预期,甚至完全一致。
同时AI计算有几个方面特点:
名列前茅个是大规模的并行方面,GPU和CPU比并行度更高。
第二个是稀疏化,譬如人脑的计算,只有触发了神经元才会运算,这是稀疏化的表现。
第三个是低精度计算,相对超级计算来说,AI计算是一个低精度的计算,比如现在用的很多的混合精度,包括Graphcore,以及英伟达的最新产品,一直在探索用更低的数据类型来做同样的工作,这也是降低能耗、提高性能的一个方法。
第四个是模型参数重复使用。
第五个是计算图结构。
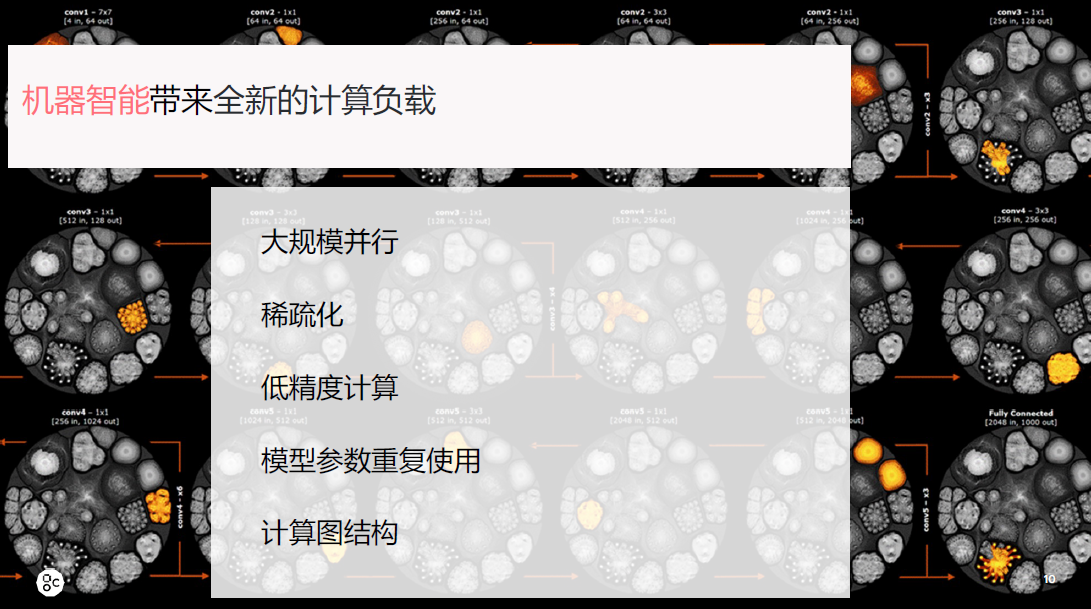
这些基本上代表了AI计算的特点。对这些AI计算方面的优化处理也能够提升计算性能,降低能耗。
Graphcore是一家做处理器的公司,核心硬件是IPU,这是一个专门为AI设计的处理器,它也是智能处理单元。围绕IPU处理器,Graphcore也构建了软件栈,针对开发者打造的软件栈是以平台的形式呈现给客户。Graphcore有两种形态的产品。
与CPU、GPU不同,Graphcore的IPU是针对人工智能计算而设计,计算的特点主要是面向计算图,是以图来作为抽象构建的处理器架构。
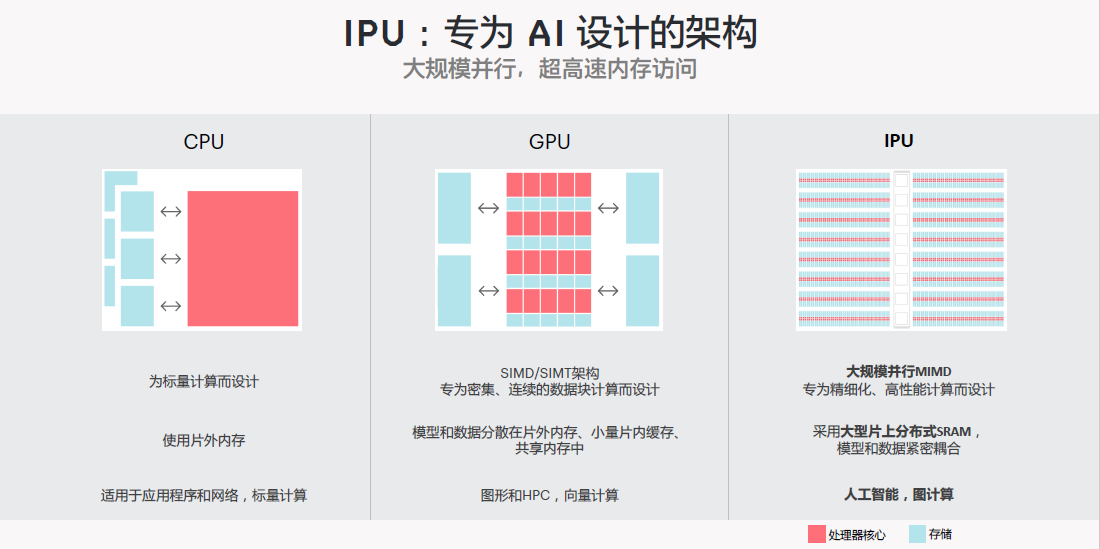
CPU使用片外内存,是标量设计,适合应用程序和网络处理程序、数据库、存储等等。
GPU是SIMD计算架构,非常适合做密切的连续的数据计算。擅长模型计算,AI模型和数据分布在现存和HBM或者少量的缓存中,应用场景是图形、HPC和相量计算,还有AI。IPU是一个大规模并行的多指令多数据架构,采用能耗更低的片上SRAM。这样的架构非常适合做一些精细化的高性能计算、人工智能以及图计算。
因此,Graphcore的IPU产品能够提供更好的性能,消耗更低的能源。
最近,Graphcore发布的最新产品采用了台积电的3D晶圆堆叠技术,有1472个独立的运算核心,每个核心有6个线程,处理器有8832个并行的线程,可以处理近9千个不同的任务,支持FP8浮点运点运算数据类型,片内SRAM存储达到900M、速率高达65TB/s,彻底打破了内存墙的瓶颈。

最新的显卡算力是3.9TB,有将近20倍的带宽提升。单片可以做到560T的FP8,280T的FP16,目前针对这个主流应用框架和模型,可以通过工具化的方式,一键把AI模型转化部署到IPU上,对80%的模型可以实现一键转移,性能非常好。
这个最新的产品,从架构和技术优化方面将能效提升了近20%。

BOW2000设计了四颗IPU处理器,通过一个芯片把四个IPU联结在一起。

部署时,可以像搭乐高积木一样,一台一台的堆叠起来,弹性和X86类似。

C600是全高全长,双槽位,以推理见长。

这是Graphcore为数据中心打造的一个推训一体加速卡,这个产品是280T的FP16的算力,180瓦功耗。相比目前市场上主流的旗舰GPU产品,310T FP16算力,其功耗达到了300瓦。因此,这个推训一体加速卡的功耗方面表现非常好。
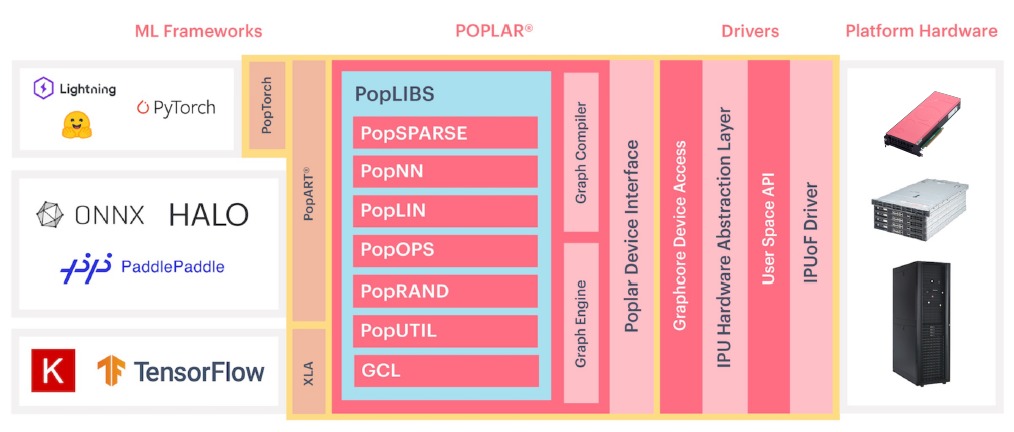
软件方面,Graphcore IPU是除头部GPU厂商之外的完备的优异厂商。
框架层面,阿里的PyTorch,百度的PaddlePaddle框架,以及国际上流行的TensorFlow等框架都适配。在这个框架之上,从应用的角度,能够覆盖计算机视觉、语音、自然语言、多模态、广告推荐,图神经网络,生成式模型等等。
Graphcore的系列产品已经在全球多个行业和领域有很多成功的应用案例。

比如使用人工智能做健康方面研究的LabGenius,使用IPU做股票预测的Man,利用IPU做大语言模型刚刚发布新品的自然语言服务公司pineso,美国国家实验室Argonne,国内也有用于城市治理应用,保险,高能物理研究,天气预测,甚至动态图等应用领域。
根据研究机构统计,2022年,在全球的AI领域发表的论文数量,IPU排名第二,是除英伟达GPU以外非常多的。
在当前的模型运算中,Graphcore IPU除了可以提供更好的性能外,每瓦的性能表现也更加优异。在超大规模模型时代,IPU的稀疏化和独特的内存架构设计可以使超大模型运行的时候延时更低、能耗更低。
被称为神经网络之父的谷歌科学家Geoff Hinton在一位记者提问“我们应该怎样构建面向未来,表现更像人的大脑一样的机器学习系统?”时,回答道:“我这里刚好有一个IPU,我觉得它特别符合我对未来智能计算系统的发展方向。”
文章来自:https://www.eet-china.com/







