











根据Gartner预测,到2025 年,云原生平台将成为95%以上新数字应用的基础,而在2021 年这一比例只有不到40%。热潮之下,越来越多的企业和开发者开始推动业务与技术的创新向云原生演进。
之所以会出现对“云原生”相关概念的追捧,Ampere首席执行官Renée James认为,是云开辟了一个新的领域,定义了现代软件的开发和部署方式。它们渴望一种新的高效计算引擎,既能够驱动云的未来发展,又能够将软件从硬件的定义中抽取出来。也就是说,操作系统和其他软件与硬件绑定的时代已经结束,人们不必担心传统软件对独特指令和功能的依赖。
与此同时,算力需求的指数级增长加剧了对架构转变的需求,同时也引发了数据中心与关键的商业和住宅开发项目对电力资源的争夺。Renée James 表示:“可持续性不再只是实现 ESG 目标的一部分——它对于未来所有计算的增长都至关重要。”对于行业的前进方向,Renée James认为:“在能耗与性能的坐标轴之中,朝坐标轴的右下方移动是行业发展的新常态,目的是实现更低的能耗和更高的性能。”
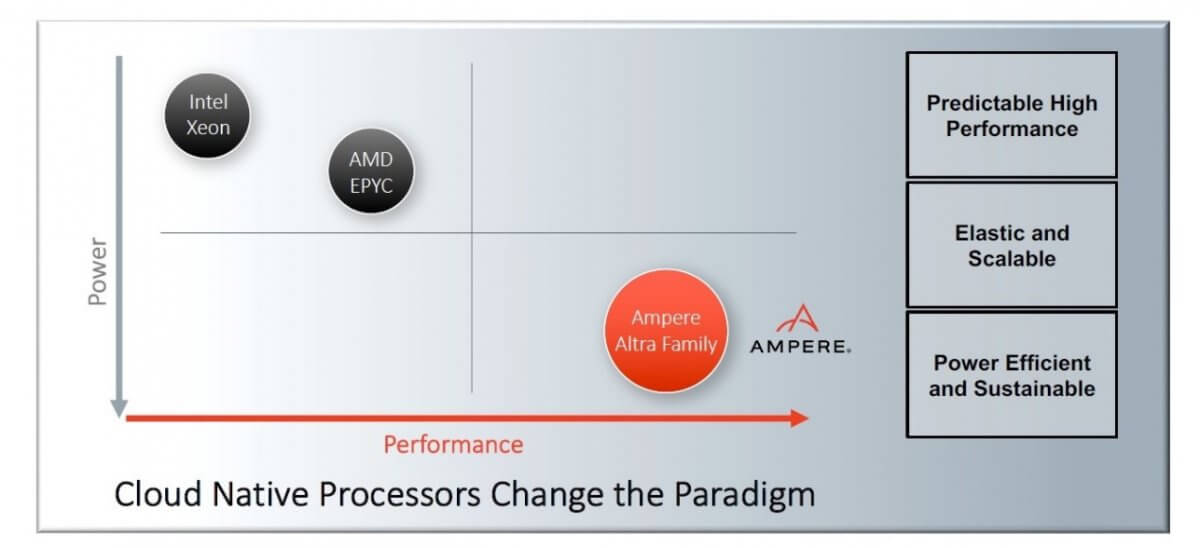
“我们使命的核心是创造计算的未来,打造一款既高性能又可持续的产品。因为在如今云带来的所有令人惊奇的事物之中,可持续性竟然不是其中之一,这也是为什么在过去几年间,我们一直在Ampere打造革命性产品的原因。”Ampere Computing首席产品官Jeff Wittich说,当今业界存在一种谬论——“认为提升计算性能,必然会带来相应甚至更多的能耗,且没有其他替代方法。“
我们可以在今天的生成式 AI中看到这种想法,所有可用资源都被无尽地投入到这些模型当中。根据最近的一项行业预测,ChatGPT单次查询的成本为36美分,是传统查询方式的30多倍,能耗同样急剧升高。但事实上,鉴于云的规模和其庞大性,以及其未来增长所面临的诸多限制,通过更低的能耗提供更高的计算能力,在所有环境中都至关重要,因为在云中,没有效率,就没有性能可言。
为此,在2020年推出的业界首款云原生处理器Ampere® Altra®和2021年推出的128核云原生处理器Ampere® Altra® Max基础之上,Ampere日前正式推出全新 AmpereOne™系列处理器。

该处理器基于5nm工艺节点制造,拥有多达192个单线程Ampere自研云原生核,内核数量为业界较高,且每核拥有64K L1数据和2MB L2缓存。在设计方面,Ampere为云进行了专门的微架构创新,如准确性更高的L1数据预取器,缩短了分支误预测的恢复时间,并增强了高级内存消歧,可为云等高性能、高利用率的多用户环境提供高水平的一致性能、可预测性和可持续性。
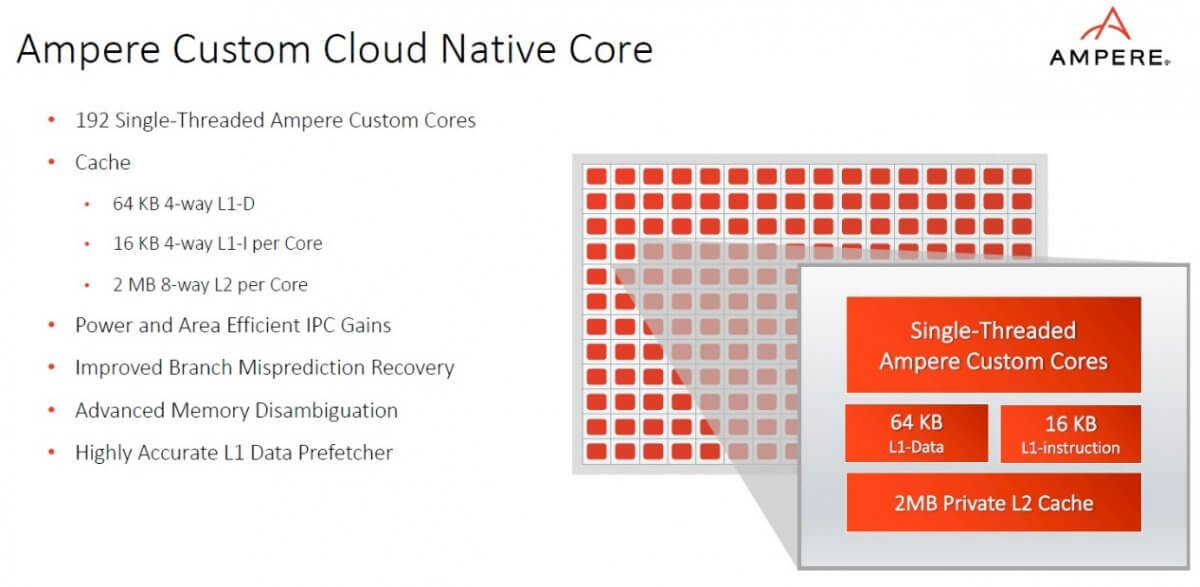
此外,Ampere还在三个基础领域引入了新的云功能,包括:
为了提供性能的一致性,设计人员引入了网格拥塞管理(Mesh Congestion Management),可通过管理密集的192个核之间的流量来提升性能,内存和SLC QoS实施功能负责管理缓存和内存使用情况,在IaaS环境中创建了新功能的嵌套虚拟化技术;
细粒度电源管理(Fine Grained Power Management)能够帮助用户更清楚地了解和管理处理器的能耗;高级Droop检测可以更好地监测电压,节省电力;进程老化监测器可随时间评估处理器的压力,这些在持续有大量工作的大规模云环境中非常重要。
通过添加安全虚拟化技术,提供了在多租户环境中隔离工作负载的额外方法;单密钥内存加密和内存标签(Memory Tagging)功能可保护内存,防止未经授权的参与者恶意读取或是某一类的潜在攻击,例如使用缓存溢出作为漏洞进行的攻击,同时也提高了针对数据库等用途的应用程序数据完整性,这是一个在传统解决方案中罕见的关键功能示例。
Jeff Wittich提供的对比数据显示,在云环境中运行虚拟机(VM)时,与96核的AMD Genoa或者60核的英特尔Sapphire Rapids相比,AmpereOne每机架运行的虚拟机数量是AMD Genoa的2.9倍,是英特尔Sapphire Rapids的4.3倍。

“AmpereOne系列处理器意味着“更多”——更多内核、更多 IO、更多内存、更高性能和更多云功能。” Jeff Wittich表示,凭借8通道DDR5内存和一个12通道的平台,加上128通道的PCIe Gen5 IO,AmpereOne正在扩展整个平台,“是一款真正意义上的杀手级产品”。
虽然Ampere是CPU市场的新玩家,但早在两年多前,Ampere就组建了专门的AI团队,开展针对AI的一系列创新。AmpereOne系列处理器除了现有的INT8、INT16、FP16支持,每核有配有两个128位矢量单元以及BF16,可以高效地提供卓越的AI性能,赋能流媒体推荐、商品智能推荐、生成式AI等诸多应用。
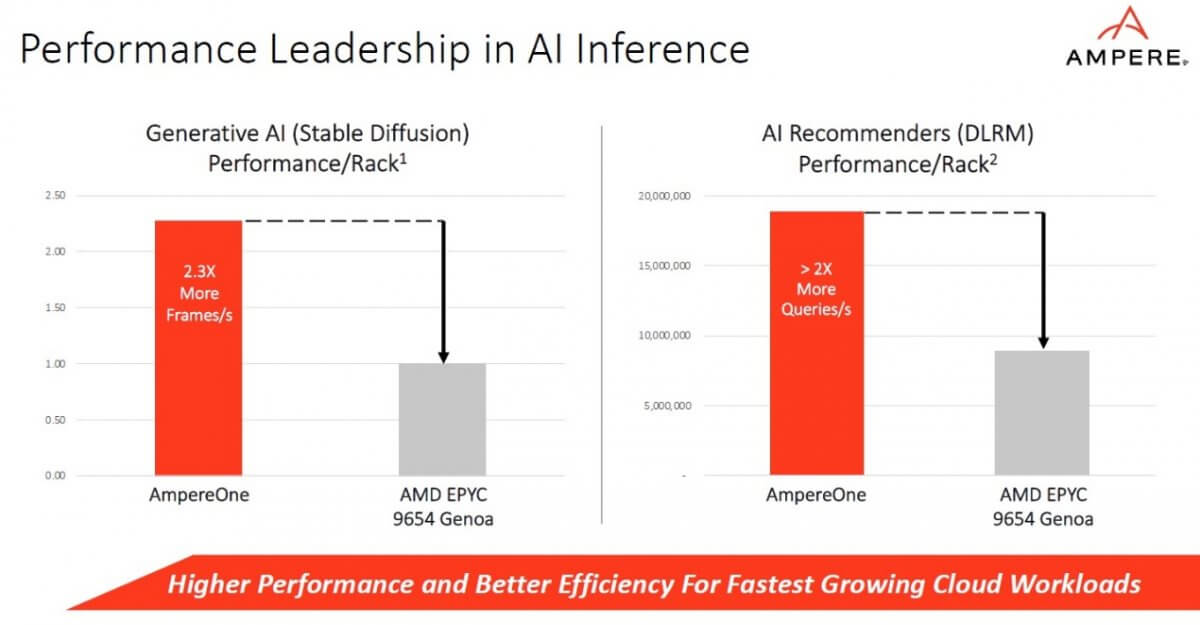
在生成式AI方面,相比AMD Genoa,AmpereOne可每秒多提供2.3倍的帧数,在运行稳定的扩散模型中胜出。此外,在运行DLRM模型的推荐系统中,通过AmpereOne响应的查询数量为每秒1,890万条推荐计算,是AMD Genoa的每秒查询数量的两倍多。
Jeff Wittich表示,Ampere的产品不只适用于当前常见的大型语言模型,也适用于过去几年相对旧的模型。通过Ampere云原生处理器进行AI推理,可获得卓越的可扩展性和性能,也打破了效率的瓶颈,而这正是令云服务提供商(CSPs)困扰的问题,因为使用GPU会带来极高的能耗,而且容量扩展和可部署的服务器数量也会受到限制。
三年前,Ampere收购了AI技术初创公司OnSpecta,相较于常用的基于CPU的机器学习框架,基于OnSpecta深度学习方案(DLS)的AI优化引擎可带来超过四倍的加速。。除了在软件方面有所布局外,Ampere AI团队还和硬件团队、架构团队在AmpereOne的特性上进行优化合作,包括支持BF16、FP16和其它数据格式,以确保其能够成为AI开发人员使用的常见库(Library)和工具。
比如一家名为Matoha的英国初创公司基于科学和工程专业知识开发了低成本的手持扫描仪,可以随时随地轻松识别塑料或织物,他们选择了OCI和Ampere Altra AI计算实例在云上训练其机器学习算法。数据显示,相较于其他处理器,Ampere云原生处理器的延迟降低了两倍,在性价比方面可节省高达75%的成本。
采用Chiplet设计是AmpereOne处理器另一个值得关注的亮点。
在Jeff Wittich看来,Ampere在新芯片中大量采用Chiplet设计,带来了至少两方面的优势,一是具备更高的灵活度,二是加速了整个芯片的设计周期。同时,通过将System Level Cache放在了计算芯片(Compute Die)上,Ampere能够帮助降低核与系统级缓存(System Level Cache,SLC)之间的延迟。这也是Ampere把极大的Mesh放在单个的计算芯片上的原因——可以帮忙避免造成访问时间(Access Time)和系统级缓存之间的不平衡,或者造成某些核无法访问系统级缓存。
与Ampere Altra和Ampere Altra Max相比,AmpereOne系列处理器推出的目的并不是要取代前者,而是要在原有基础之上实现持续扩张。简单而言,在边缘计算场景,只需要部署32核、功耗40瓦的Ampere Altra处理器就可以了;但对大规模数据中心而言,拥有更多算力IO、内存和带宽的192核AmpereOne可能就是更好的选择。
此外,用户也不用担心任何的兼容问题,因为AmpereOne系列和Ampere Altra系列处理器均基于ARM ISA架构,所有代码和工作都能在两类处理器上正常运行,不需要任何改动。Jeff Wittich说Ampere始终希望继续扩展生态合作,让Ampere的产品面向更多用户,能够在公有云、私有云、企业、混合云、以及边缘计算等多个场景中触手可及。
文章来自:https://www.eet-china.com/







