











EE历史课系列很久没开课了。最近Chips and Cheese更新了骁龙820的测试:我们前两年也规划过追溯骁龙820手机芯片的选题文章,不过因为始终没有搜集到满意的素材,就搁置了。而Chips and Cheese这回的测试数据给得已经比较详尽,那么干脆直接结合这些测试,我们来谈谈昔日的这颗手机SoC。

骁龙820之所以特别,在我们看来主要有两个原因。其一是,这颗SoC的CPU部分用上了高通自研的Kryo核心,而非Arm公版——在32位时代,高通一直有自研CPU的传统,较早的Scorpion和后来的Krait都曾是高通在手机芯片市场上造成差异化的优异架构。
在苹果A7把iOS生态带入64位时代之后,高通也很快把64位带向了Android生态,匆忙发布了可能是这家公司历史上最不愿意被提起的产品,骁龙810。甭管骁龙810的实际表现如何吧,其各方面都显得十分仓促,尤其CPU竟然没有采用自研架构,而用上了Arm的CPU IP——这很不高通啊。
这就让骁龙810的迭代产品,骁龙820被市场寄予了极大的期望。高通也的确在骁龙820这代芯片的CPU部分,重返了自研架构。但与此同时,骁龙820也事实上成为,到目前为止高通历史上最后一代自研CPU架构的手机SoC芯片。后续的骁龙835,以及一直到延续至今的手机AP SoC,虽然高通还沿用了Kryo这个品牌,但架构主体基本就是Arm Cortex-A/X系列,也就是我们所说的Arm公版。
其二,骁龙820的口碑似乎处在某种薛定谔的神奇状态。骁龙820的职责之一,应该是拂去昔日骁龙810的阴影,并且要把竞争对手在此期间拿下的地盘给抢回来。这颗芯片在问世之初,似乎还的确不负众望,在Geekbench 3之类的测试上表现出了非常大幅度的提升;前期也多半获得了媒体的交口称赞。
但在大量骁龙820手机铺货以后,骁龙820再度迎来了一波口诛笔伐。此事似以新版测试软件Geekbench 4的发布为转折点——下面这张图来自XDA-Developer。在Geekbench 3基准测试中,骁龙820的单核性能遥遥名列前茅于所有竞争对手,包括当时热度甚高的三星Exynos 8890和海思麒麟950。但Geekbench 4一发布,其测试成绩突然全面落后于竞品。
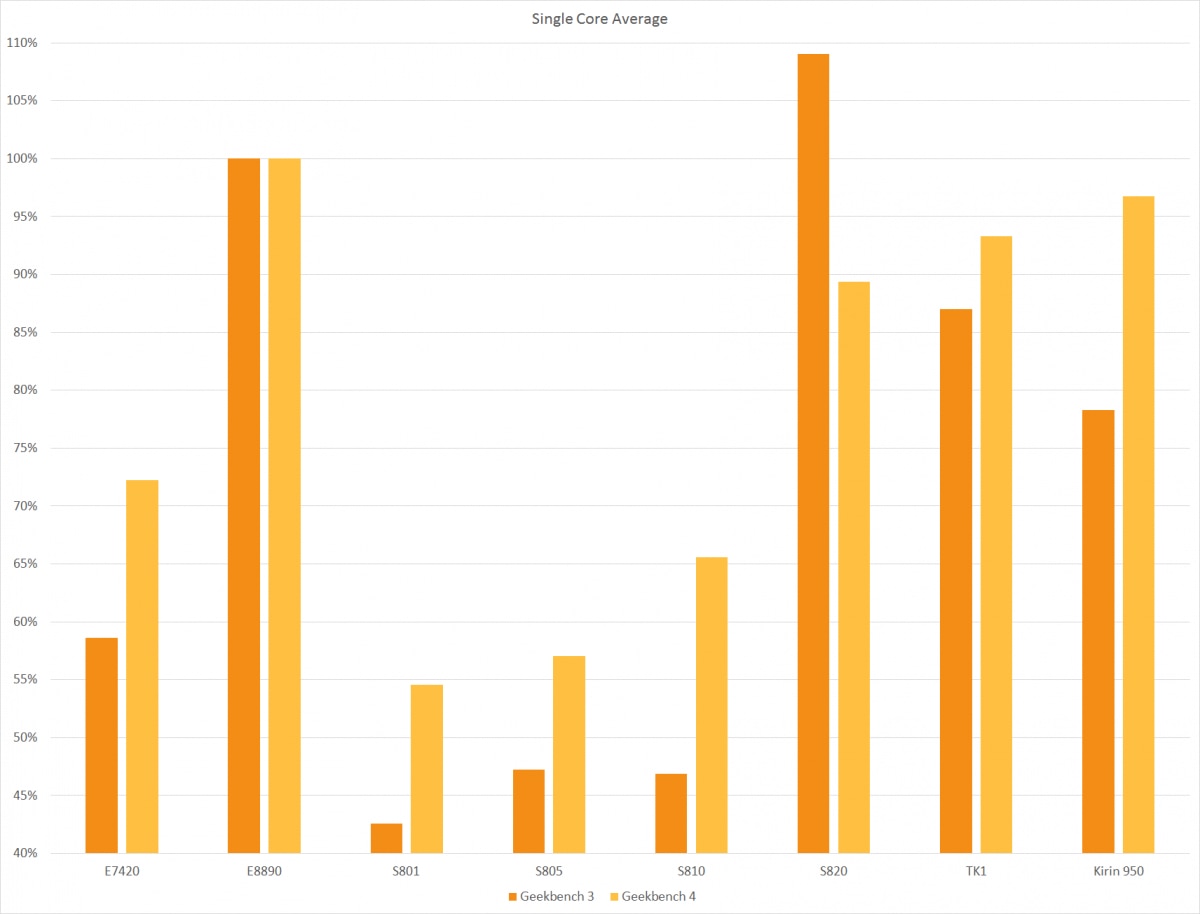
与此同时,骁龙820手机续航不行、发热严重的声音不绝于耳,甚至有人将骁龙820“抬到”与骁龙810并肩的“历史地位”。但另一方面,骁龙820在后期又出现了不少新的传说,包括一骑绝尘的浮点性能——AnandTech甚至在评测苹果A12时期(时隔3-4年),都还不忘提一嘴骁龙820在某些测试子项中名列前茅的成绩。

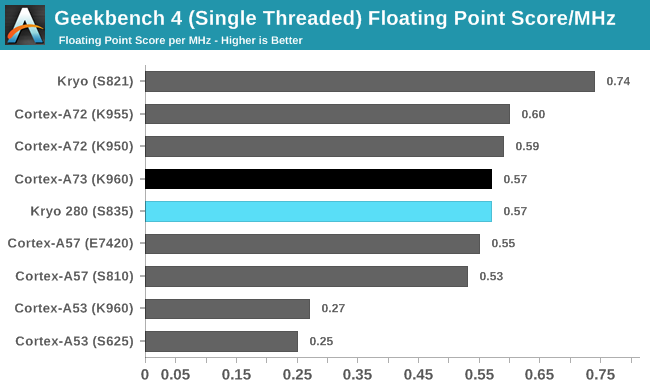
上面这张图列出SPEC2006测试获得的IPC成绩(跑分÷频率),fp浮点测试里,骁龙820超过了同时期乃至次年迭代的全部Android手机SoC——两年后的骁龙845都比不上。还有Geekbench 4的单核浮点性能IPC对比:
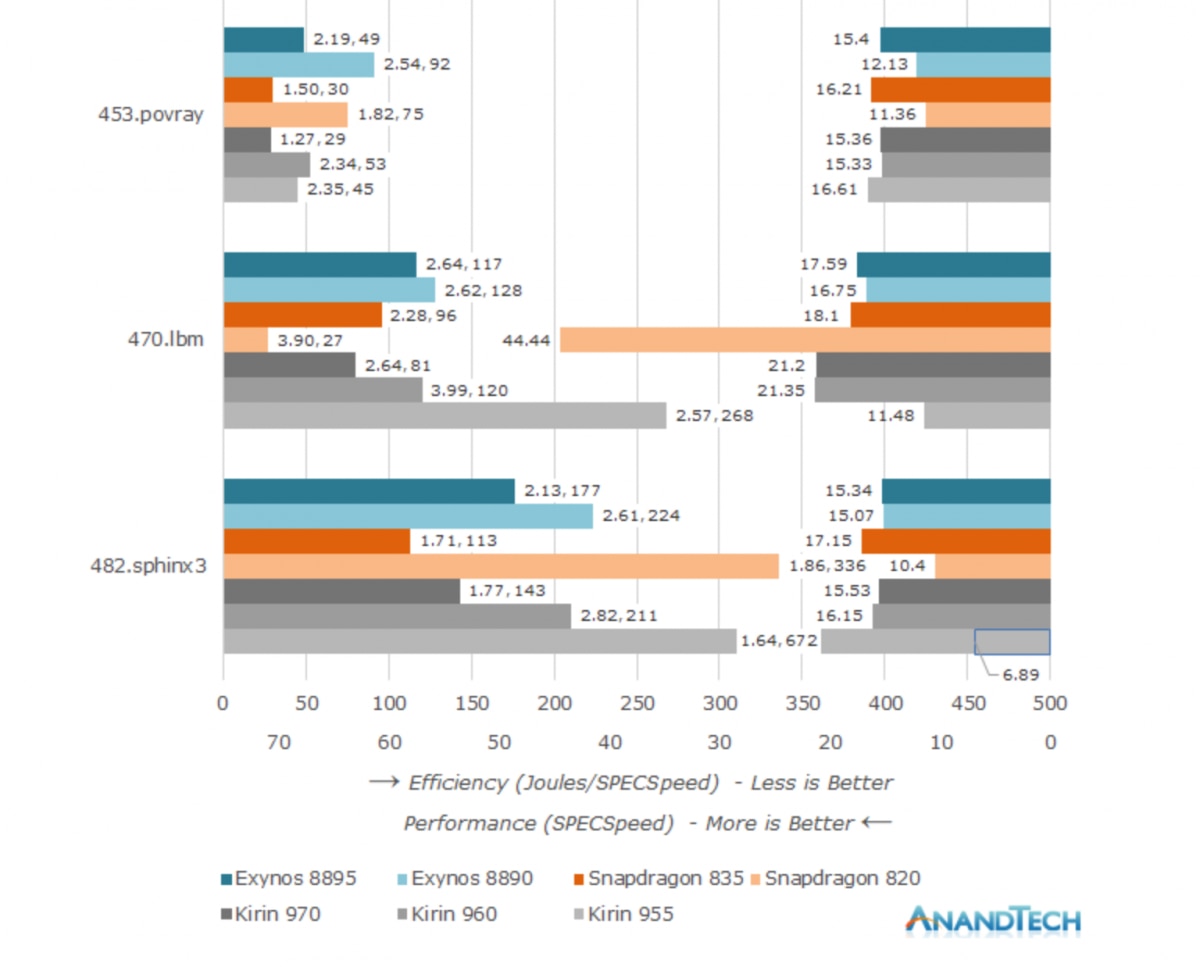
下面这张图则摘录SPEC2006测试的部分子项,可以看到骁龙820那“超凡脱俗”的偏科——比如在470.lbm这样的测试里,性能和效率逆天;而482.sphinx3测试项,结果又十分悲剧…(左边的柱状条反映的是能效,越短越好;右边的柱状条反映的是性能,越长越好)
究竟是道德的沦丧,还是人性的扭曲?本期EE历史课,我们借着Chips and Cheese的测试,来谈谈2015年发布的骁龙820。或许基于这些分析,多少也能窥见,为何骁龙820会成为高通最后一代CPU自研架构的芯片。
年代比较久远了,先回顾一下骁龙820及同期迭代款骁龙821的一些基础配置信息。骁龙820选择了三星14LPP制造工艺;CPU是2大核、2小核的设计,大核小核皆为Kryo架构,频率和配套cache上存在差异;GPU为Adreno 530;DSP Hexagon 680;支持LPDDR4 1333/1866;modem X12 LTE;
我们主要关注的还是骁龙820/821的CPU部分,其他包括GPU、DSP、内存与I/O支持等在内的周边信息就不多说了。
 和Arm的大小核设计不同的是,高通骁龙820的CPU部分大小两种核心,都是一样的Kryo微架构——只不过大核在频率和cache容量上会分配得更高、更大一些。维基百科的历史资料显示,骁龙820(MSM8996)的大核频率2.15GHz,小核频率1.59GHz;后来发布的骁龙821,频率又略提了一些,尤其小核频率有2.19GHz的版本可选。
和Arm的大小核设计不同的是,高通骁龙820的CPU部分大小两种核心,都是一样的Kryo微架构——只不过大核在频率和cache容量上会分配得更高、更大一些。维基百科的历史资料显示,骁龙820(MSM8996)的大核频率2.15GHz,小核频率1.59GHz;后来发布的骁龙821,频率又略提了一些,尤其小核频率有2.19GHz的版本可选。
值得一提的是,骁龙820没有选配L3 cache。其实同时代的Arm Cortex-A72也没有L3 cache,但当时的传言消息是骁龙820会配L3 cache。AnandTech甚至说基于高通来源信息给到的cache block来看,应该会有L3 cache,但在骁龙820正式问世时还是没有见到L3 cache.
从2015年AnandTech给出骁龙820的Geekbench 3和SPEC2000测试结果来看,骁龙820相比于骁龙810的提升非常大,或者说高通Kryo架构在Arm Cortex-A57面前是占尽了优势的。不过SPEC2000的某些子项出现性能显著下降有些令人困惑,AnandTech当时说在编译器配置上还没整好。
需要提一嘴,与骁龙820同期的手机芯片还包括苹果A9、海思麒麟950、三星Exynos 8890。如文首提到的,在Geekbench 4发布以后,骁龙820在同期竞品中的测试名列前茅被逆转。这一点,有一种说法是Geekbench 4测试大幅调低了浮点测试的权重——这一点我们无法求证,Geekbench 3的官方文档对于各子项描述语焉不详;后文有机会解答这个问题。
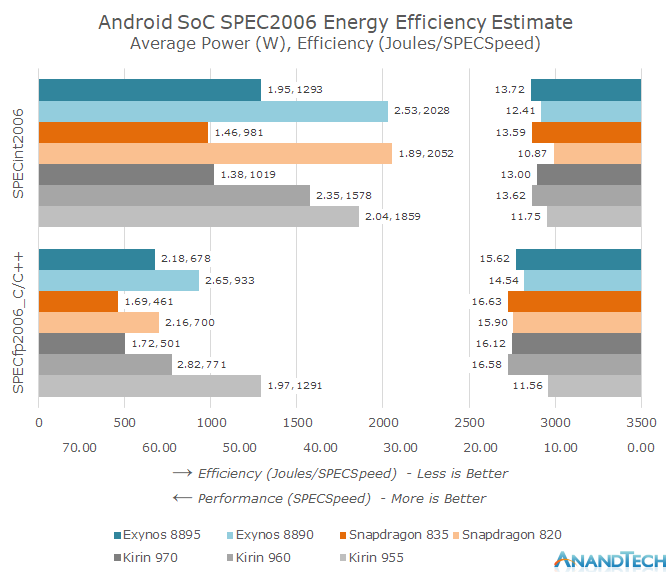
另外,别看前面给出的同期手机芯片IPC对比,骁龙820还挺不错的样子——包括SPECint2006整数性能部分,还优于Exynos 8890和麒麟950,实际从能效和总体性能维度来看(如下图所示),骁龙820可以说是一塌糊涂的——尤其在SPECint2006测试里,不仅性能全场最差(右边的柱状条,越长表示性能约好),而且能耗还较高、能效最差(左边柱状条,总能耗÷跑分成绩,代表每跑1分所需耗费的能量)。
上面这些毕竟还是黑盒式、粗线条的信息,Chips and Cheese最近做了一系列microbenchmarking,逆向了这代芯片CPU部分的更多微架构信息。他们测的,实际上是个骁龙821手机LG G6,所幸821和820的差别也不大,微架构层面无变化,也是能够说明问题的。
不过我们还是从最直观、最简单的部分来看。后文针对微架构的进一步解析中会看到,骁龙820的Kryo架构,在规模上对于2016年的手机芯片来说算是非常大的,包括前端4-wide宽度,执行引擎部分出色的scheduler layout,低延迟的L1-D,充沛的整数执行单元资源,达成较高的IPC成绩。
另外还有很强的分支处理能力、用于分支较大的重排序容量;load/store单元采用精致复杂的逻辑来处理存储转发——某些情况甚至是Arm的当代架构都处理不来的。Chips and Cheese对于Kryo的评价是降低了频率的桌面核心——虽然我们认为,称其为“桌面核心”还是夸张了点儿。
不过Android生态在当时并不存在可在核心带宽、执行资源、重排序队列容量方面可与其媲美的设计,这样的规模也是Android手机AP SoC在此多年以后才达成的。但这可能也成为葬送Kryo,甚至高通那一时期自研CPU架构的关键。
加上高通当时并没有Arm那样的小核心方案,骁龙820的“大小核”实际上堆的是同一种核心,骁龙820的“小核心”占地面积也因此一点都不小——所以骁龙820的CPU只配了4个核心;且相比于当时Arm公版普遍的8核心方案,自然还要影响到多线程性能。
这种超大的核心设计,是否真的适用于当年Android生态(虽然似乎“桌面级”是苹果在A7芯片时期就已经向外接传递的信息了)?
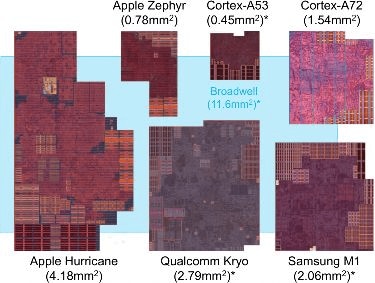
Kryo在当时的手机芯片里,应该是除了苹果之外最大的核心了(当然了,跟Broadwell自然还是不能比)。那为什么苹果行,高通骁龙820就不太行,甚至后续放弃这样的思路了呢?从市场角度来看,还是应当首先考虑更大的面积,造成更高的成本——这绝对不会是高通希望看到的。毕竟苹果不仅设计芯片,还卖手机;这和高通的业务模型就完全不同。
但抛开这些,在执行层面,其实技术上似乎还存在更具体的问题。
下面这张图是逆向得到的骁龙820/821的Kryo架构框图,当然其中某些信息仍然是不确定的。

前端的分支预测部分,Chips and Cheese给的评价不错的分支预测能力,可识别和Cortex-A72相似的模式,但有很多分支的时候,表现就不怎么好,和桌面级的Skylake还是有差距。
在分支目标cache(branch target caching)方面相对“保守”(可能选择了快速branch address calculator加上L0+L1指令缓存方案,8KB L0 cache,2周期延迟)。Kryo在这方面会比A72出色。Cortex-A72用BTB(branch target buffer)时候,会比Kryo从L0读取分支并计算目标地址要慢。
超过8KB会有延迟惩罚,但在预期范围内。间接分支预测情况基本类似,Cortex-A72选择了更深的return stack,Kryo在return型预测上选择了16-entry的return stack。
来到取指部分,Kryo用上了32KB L1-I(L1指令缓存);Kryo能够读取并解码每周期非常多4条指令,此处也就可被称作4-wide。单纯就这个宽度来看,也可以说Kryo是较宽的CPU架构。Cortex-A72前端为3-wide,而A73收缩到了2-wide——起码在当时的移动领域,Kryo称得上超宽了,这似乎也是以往高通自研CPU架构的传统。
不过这里需要留意一个事实,Cortex-A72的前端虽然是3-wide,但L1-I却选配了48KB(上一代Cortex-A57也是48KB);Kryo这部分资源就只有32KB。需要从L2取代码时,前端吞吐会骤降至1 IPC,从下面这张图可以看出两者在不同的数据覆盖位置下滑。值得一提的是,这其实也是低功耗核心与桌面处理器核心一个较大的差异点,即在L1-I发生cache miss时前端吞吐的显著下降;所以Kryo还是很难称得上是“桌面”核心。
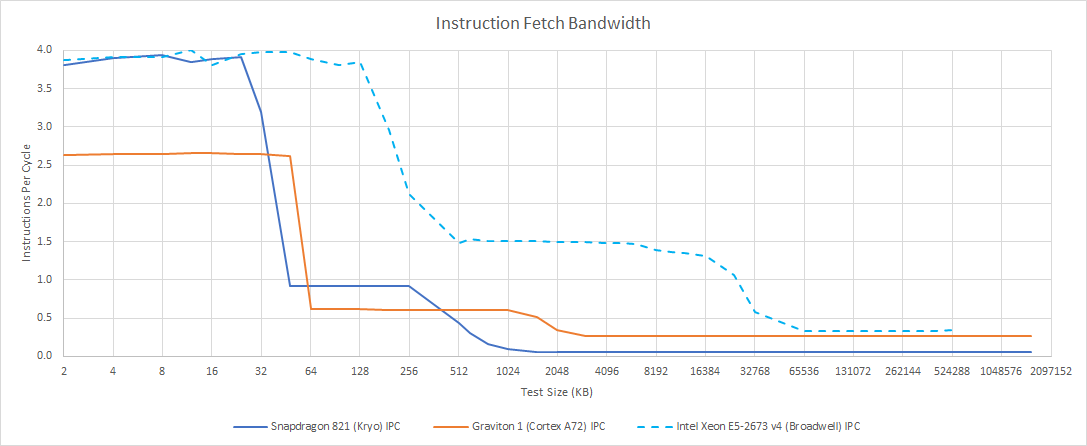
来源:Chips and Cheese
乱序执行部分,Kryo的ROB(重排序buffer)深度和Cortex-A72差不多,但在处理不同的乱序buffer时,差别比较大。尤其Kryo在大量分支的整型代码上,有着较高的利用率,flag register file结构的更大容量支持也是特色;Cortex-A72则在这部分表现出重在标量浮点代码方向,但因为Kryo有全宽的矢量寄存器,所以A72这部分也没优势。
另外Kryo在scheduler容量方面也有优势。Chips and Cheese评价Kryo的scheduler并非完全的“distributed(分散式)”,整数scheduler做成了两个2-port队列,在调度容量上和Cortex-A72的4个队列相似,不过这种设计会更加灵活;浮点/矢量与存储访问部分的scheduler,在“distributed”的队列分布上和A72一样,但这些队列容量会比A72更大。Chips and Cheese认为,Kryo的scheduler设计显著优于A72,只不过可能在功耗和面积上需要付出代价。
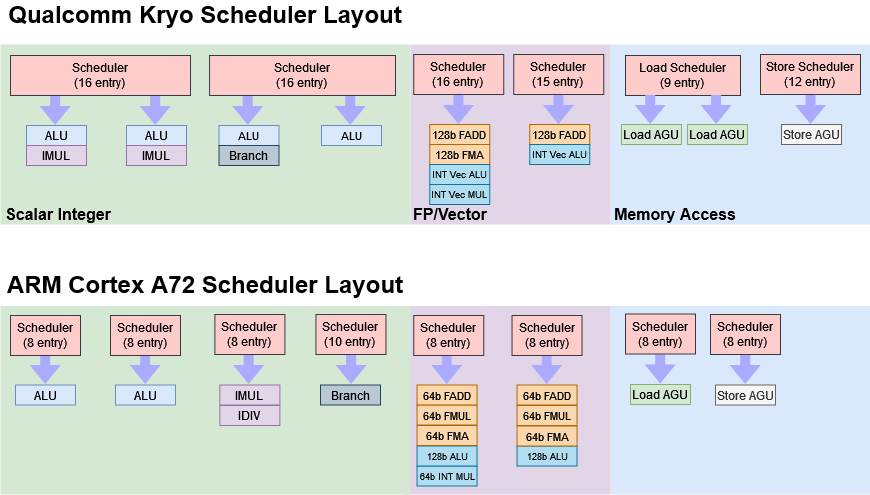
Kryo整数执行单元部分的配置还是很强的,4个ALU基础整数运算的每周期吞吐达到了桌面CPU的水平,尤其有着很出众的整数乘法吞吐能力,虽然其分支吞吐会比Skylake这种桌面核心弱一点。Cortex-A72的乘法延迟也是5个周期,就一个port用于整数乘;总共2个ALU,port争抢的情况也就会存在。
浮点与矢量执行方面:标量浮点性能,Kryo配了2个相当快的3周期FP加法器,Cortex-A72这边要稍慢一点,是4周期。矢量浮点性能方面,Kryo理论上会有更高的吞吐,因为128bit的FMA(融合乘加)只需要占一条FP管线——则达成了双发射一个128bit浮点加,以及一个128bit FMA指令,给到了每周期12个浮点操作;而且Kryo的FMA延迟也控制在了5个周期,Cortex-A72需要7个周期来完成相同的操作。
另外和Cortex-A72相比,Kryo有明显更好的矢量整数执行能力。矢量INT32加法在1个周期内就完成,A72是需要3个周期的。矢量INT32乘法,双方都需要4个周期,但不要忘记Kryo这边有着2倍的吞吐能力。
与此同时,Kryo每周期可完成2个128-bit矢量load操作,虽然是不连续的;Cortex-A72这边则是每周期一次load;而在写入数据上,Kryo每周期可完成一次128bit store操作,A72就需要2个周期了。
到这里可能能够部分理解骁龙820在测试中表现出的部分偏科。
这部分比较值得一提的是Kryo的存储转发(store forwarding,写入存储;出现于写入内存操作,紧跟着从相同地址读取时)能力,达成Skylake的存储转发特性。Chips and Cheese形容这部分相当的sophisticated。
但转发延迟达到了13个周期,和 AMD以前的推土机一样悲剧,还要考虑到Kryo的频率不高,具体的数据可以去看Chips and Cheese的文章。Cortex-A72在存储依赖性方面的表现就不错,转发通常为7个周期的延迟,即便是开销最大的跨cache line,A72也比Kryo要快。
TLB(内存地址转换查询buffer)方面,Kryo有192-entry的L1 TLB,没有采用多层级设计——数据覆盖一大就会悲剧。
接下来是cache访问相关的性能了。前文已经提到,Kryo是两级cache设计。Chip and Cheese提供的数据是L1-D(一级数据缓存)容量仅24KB,访问延迟为3周期(AnandTech的数据是32KB L1-D);

来源:Chips and Cheese
L2 cache是大小核每个集群一份,具体到测试的骁龙821大核集群是768KB的L2 cache,延迟25周期;小核集群512KB,23周期。这个数据和AnandTech给出的也不同,AnandTech较早给出的数据是大核集群L2 cache可能是1MB(骁龙820)。但双方都无法确定数据准确性。
不过无论如何,Kryo配的L2 cache延迟都显得非常高,毕竟容量也不大。换算成具体的时间,Kryo的L2 cache延迟达到了10.9ns,基本上和Intel Skylake上更大的L3 cache差不多的水平——当然后者的频率肯定高很多了。Chips and Cheese测试的亚马逊Graviton 1处理器,Cortex-A72访问共享1MB L2 cache需要21个周期,达成了更快的速度和更大的容量。

从带宽角度来看,Kryo和A72差不多都在每周期8 bytes的水平以上。不过Kryo更为分散的L2设计,在线程增多的情况下,带宽会有优势。只不过那么小的容量,好像也不会有多大的实际作用。
骁龙820 CPU的整个存储子系统,看起来和核心其他组成部分的堆料,完全不搭调。前些年有人大胆猜测过,骁龙820原设计可能真的存在L3 cache(和AnandTech之前的说法一致);另外猜测高通在发现骁龙820功耗不及预期以后,还对核心的L1砍了一刀(因为就连骁龙810的A57都配了48KB L1-I + 32KB L1-D。
仔细想想这套方案可能配上L3 cache,以及增大L1 cache容量,都会让Kryo整体显得协调不少。
有关骁龙820在Geekbench 3和Geekbench 4两个测试里出现成绩反转的情况,一方面大概的确和Geekbench 4调整浮点性能得分权重有关;另一方面大概真的和L1 cache被刀,以及L2 cache也不行有极大关联——早前Linus Torvalds就吐槽过Geekbench 3,他说”Geekbench is SH*T”,”they are mainly small kernels”, 怀疑其中大部分测试”code footprint basically fits in a L1-I cache”。
换句话说,Geekbench 3的很多测试代码直接就放进L1了,则恰好隐藏了骁龙820 CPU存储子系统性能羸弱的缺陷。
还有一点值得一提,骁龙820和821实际上总共至少有4个不同的型号版本,在频率方面各有差异。这可能表明芯片制造时的良率控制出了问题——则有很大概率是骁龙820最终的PPA表现,经由三星foundry之手过后,的确在高通意料之外,不得不做了相对仓促的调整。
Chip and Cheese在总结中提到骁龙820的cache系统很尴尬,L2 cache又小又慢,喂不饱执行引擎。Kryo自身也有问题,即便load/store的存储数据依赖处理机制很先进,但存储数据转发极慢;TLB只有一级的设计,令输出超过768KB占用就面临page walk惩罚,超过28个周期…
其实cache配置改进一下,骁龙820整体就会有个不小的提升;增加二级TLB,修正存储转发高延迟,都会让情况变好。另外Chips and Cheese还认为,如果Kryo架构能够用更先进的制造工艺,则情况可能会理想很多——不仅降低功耗和发热,而且还能增加核心数。
最后值得一提的是,我们知道2021年高通收购了Nuvia;与此同时Arm还在收紧授权策略;双方还在干架。那么高通自研CPU的路子应该会较大概率走下去,则骁龙820就不会是采用高通自研CPU的末代手机芯片,即便这其中还会有不少变数。
其实当年高通抛弃自研CPU方案,很大程度与Arm的公版设计走向越来越成熟可能有关系。而且当时Arm正式推出了Built on Arm Cortex Technology授权方式,骁龙835就是基于这种BoC授权,对Cortex-A73进行的半定制。所以或许高通的动向,与Arm的策略也有很大的关系。
文章来自:https://www.eet-china.com/







