











我们对SIGGRAPH这种顶会的三个印象是:图形,图形和图形。NVIDIA作为SIGGRAPH的常客,那当然一点都不意外。这家公司至少Gaming(游戏)和Professional Visualization(专业视觉)业务跟图形技术强相关。图形加速卡和“真正的”GPU,不都是围绕着“图形”技术的吗?
即便现在NVIDIA最春风得意的业务方向是AI加速,SIGGRAPH这种图形技术顶会,NVIDIA总该以图形和元宇宙为主,多聊聊AI之外的东西了吧?
实际情况是,在这场以图形技术为主场的主题演讲里,黄仁勋提到“generative AI”和“generative model”的次数多达55次——也就是说这场1小时20分钟的演讲,平均1分半钟,黄仁勋就得提一次生成式AI。这是在借着SIGGRAPH的场子,宣传AI啊?实际情况可能比这还是要复杂很多的,先来看一个例子。

大部分关注NVIDIA和元宇宙话题的读者,对于Omniverse应该很熟了——电子工程专辑以往也写了不少Omniverse相关话题的文章。简单来说,在Omniverse世界里,可以构建各种现实世界的数字孪生(digital twin)——比如一个机器人、一辆汽车、一座工厂、一个城市,甚至是整个地球。
把现实世界的东西,以符合物理规则的方式,放进Omniverse虚拟世界中,构成元宇宙。不过Omniverse的另一个职能是设计协作:Omniverse把各种设计工具,包括作图的、3D建模的、做动画的等不同工具串联起来——来自全球各地不同位置的设计师、创作者、开发者,都可以在这个虚拟世界里,协作完成设计。
所以我们说,Omniverse是图形强相关的产品,需要图形技术加持。今年春季GTC黄仁勋当时主题演讲对Omniverse的介绍只用了20分钟,前1小时都是在谈AI——毕竟ChatGPT、Midjourney之类的生成式AI现在那么火。
那在SIGGRAPH上大谈AI,是不是又要把图形和Omniverse给冷落了?黄仁勋这场演讲的主题,在我们看来应该是AI如何赋能图形技术,或者说NVIDIA Omniverse + NVIDIA AI如何一起发挥作用。当然,我们都知道Omniverse模拟世界里训练汽车和机器人的DRIVE Sim、Isaac Sim多少都 和AI有关,但生成式AI呢?为此,NVIDIA展示了这样一个demo:
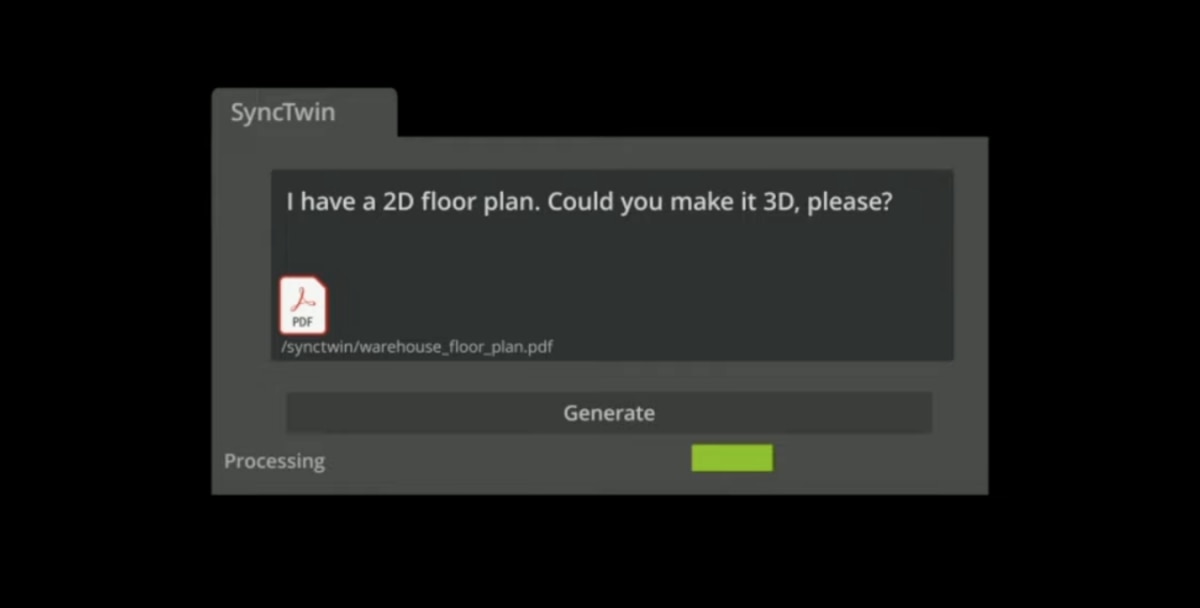
高效规划工厂、仓库之类的工业场所,是相当冗长、复杂的工程。从规划概念,到工厂最终落地,还要考虑后期扩容之类的问题,其中有着无数的坑。NVIDIA展示从一个PDF文件开始,将2D CAD平面图,转为3D模型,加入光照、纹理各类效果,到形成工厂的数字孪生,并与资方做分享。
关注Omniverse的同学对这个流程应该不陌生,Omniverse本来就擅长干这活儿——它把各种设计工具串联起来。即便如此,这套流程都仍然相当复杂——它要求专业、经验丰富的设计师、工程师,及多方沟通协作。而这次,NVIDIA在全流程用上了生成式AI,所以情况就变成了这样:
首先借助Omniverse里的一个扩展,名为“SyncTwin”将二维CAD平面图,转成3D的OpenUSD格式模型。NVIDIA在演示里,是通过对话的方式,给了AI一份PDF文件,并输入(prompt)“我有张2D平面图,能转成3D的吗”——就像我们用ChatGPT和Midjourney时那样对话。
再用这次NVIDIA新发布的DeepSearch(3D搜索服务)对OpenUSD资产内容做进一步的填充;随后用BlenderGPT,再次以对话请求的方式,生成光照内容——也是在文本框里写句话的事情;接下来用Adobe Firefly——又一个生成式AI,生成仓库地面材料——演示中输入的关键词有“warehouse floor”(仓库地面),“realistic”(写实风格),“hd”(高清),“worn”(有磨损),“industrial”(工业);
工厂顶盖部分则用Blockade Labs打造——Blockade Labs也是个text-to-3D的生成式AI渲染工具。搞定以后的空间内容,就可以添加到现有工厂数字孪生里面了——然后通过Omniverse Cloud GDN一键发布,分享给投资人、股东,或者其他设计者、建筑工程师看,在不同的设备上就能做可交互的浏览。

从一份PDF文档,最终构建起了3D虚拟工厂。当然具体实施的时候,相信还存在不少需求细节化调整的部分,不过大方向就依托于Omniverse这个平台,和各种生成式AI,借助人与AI对话的方式,把2D平面图,转成了完整的数字孪生。是不是还挺神奇的?
其实在今年GTC上,就生成式AI在内容和多媒体创作方向上的应用,NVIDIA就提到过,元宇宙虚拟世界是基于物理规律的,生成式AI加速了虚拟世界的创建过程。此过程里,“生成式”这个词就体现得相当到位了,元宇宙里的内容填充不就需要“生成”吗,显然AI是填充这些内容的优异助力。
怪不得SIGGRAPH这种图形顶会上,NVIDIA也能大谈生成式AI——以前我们对图形与AI的结合还停留在DLSS这类AI超分技术上。而上面这个例子,不就是图形与生成式AI的结合典型吗?这次SIGGRAPH上发布的几个比较关键的生成式AI,包括ChatUSD、RunUSD、DeepSearch等服务(或API),都和“USD”有关。
USD(Universal Scene Description)也在我们此前介绍Omniverse的文章里详细谈过。USD相对于3D图形,可类比为HTML相对于web。我们理解的USD是3D数据表达的某种标准。USD较早由Pixar提出,并广泛应用于3D动画、CG之类的领域。今年8月初OpenUSD联盟(AOUSD)组建,初始成员包括了Pixar、Adobe、苹果、Autodesk、NVIDIA,还有Linux基金会JDF等——黄仁勋称这个联盟的存在让USD生态获得了“turbo charge”。

OpenUSD的存在,应该说是Omniverse能够串联起来自不同厂商的设计工具的基础——毕竟大家有了相同的数据标准和框架,才谈得上互通与协作。而现在,OpenUSD显然又成为生成式AI应用于图形设计的基础。前面列举的从PDF文件到虚拟工厂的例子,全流程都依托于OpenUSD。
现阶段USD生态的发展情况还不错,实现原生USD支持的工具已经有50款,包含“来自100家企业170个contributor”。NVIDIA现在对于5年前自己选择USD还是非常认可,并且相当坚定的。
随着生成式AI发展的进一步白热化,NVIDIA应该会更积极地促成OpenUSD生态的发展。因为唯有更多的图形相关技术企业、创作者、开发者加入进来,这套生成式AI的方案才有机会推而广之,也就能加速Omniverse的构建过程。相对的,基于OpenUSD的这些生成式AI,本身也旨在加速OpenUSD生态的扩张。
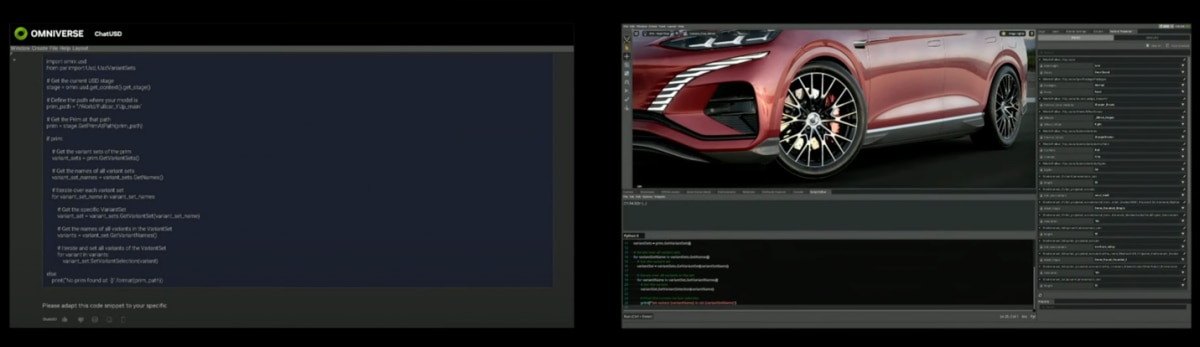
比如说这次发布的ChatUSD,是个text-to-Python-USD的API。也就是说和ChatUSD说话,就能按照要求生成USD Python代码,也就是生成3D场景中的对象、在场景中的摆放等。ChatUSD本身是基于NVIDIA的NeMo框架,训练内容包括一众USD文档,和NVIDIA自己的USD代码。
再比如RunUSD,可用于检查开发者所写USD内容的兼容性、可用性;DeepSearch则如前所述,可以理解为基于语义的3D内容搜索服务,输入文字或者图片,搜索数据库里不带标签的资产数据。这三者皆以Omniverse Cloud API的方式提供服务。
那么USD现在肯定不只是用在3D动画这么简单:从NVIDIA列举的合作示例来看,汽车、建筑、仓储、机器人、工业制造都囊括在OpenUSD的推广蓝图中。
当然说到底,这还是NVIDIA元宇宙和AI技术的推广,毕竟工业数字化,是个潜在50万亿美金产值的大蛋糕。“Omniverse和生成式AI一起,能够帮助全球的重工业,做到工作流的数字化。”“现在完全机械化的东西,全流程都可以实现数字化,用OpenUSD融合进来。”“在物理实现落地之前,就以数字的方式降低能耗、减少浪费、减少错误的发生。”黄仁勋说。
所以无论如何,以OpenUSD为格式与框架标准,图形与生成式AI都变得强相关了。这次NVIDIA在SIGGRAPH上发布的GPU,仍然应该分两部分来看:Hopper架构的GPU,和Ada Lovelace架构的GPU。
前者用于HPC和AI,没有多少图形单元堆料——基于我们前文探讨的,它现在也能放到SIGGRAPH这种图形顶会上来讲了;后者是NVIDIA标准的图形RTX GPU,只不过它也能追逐生成式AI。
GH200的新闻这几天霸屏,想必大部分同学都已经看到了。其实Hopper架构GPU的发布,是早于生成式AI这股旋风正式席卷全球的:即便Transformer引擎很显然已经为生成式AI的发展铺了路,GH200的发布仍然不令人意外。因为生成式AI和LLM大模型的特点,决定了对大内存、高带宽更进一步的需求。

GH200 Grace Hopper Superchip
所以Grace Hopper 超级芯片组合了Grace CPU与Hopper GPU,配上141GB内存容量、5TB/s带宽的HBM3e,相比于H100达成1.7倍的片上存储容量和1.5倍带宽的提升——显然就是主要冲着生成式AI去的。
更有趣的其实是GH200构成的系统。两个Grace Hopper 超级芯片(基于NVLink连接)构成一个计算节点……借助各种networking芯片和设备(包括DPU、NIC、交换机等),基于节点、计算模块组成SuperPOD总共256颗Grace Hopper芯片,理论总算力1 ExaFLOPS,144TB HBM存储容量。

黄仁勋称这套系统为“全球最大的GPU”, 256颗GPU就如一颗GPU那样工作。“这是一颗当代的GPU(this is a modern GPU)。”上面这张图基本展示了系统的实际尺寸(注意中间黄仁勋的剪影,对比其尺寸)。如果将GH200 SuperPOD称为一颗完整的GPU,那么和5年前Turing架构GPU拿在手上的样子差别就真的很大了。
黄仁勋还真的在介绍GH200系统之前,掏出了一张2018年发布的Turing显卡做展示,大概就是为了对比这些年AI加速卡形态的演化之剧烈。对比Turing,而非更早架构的原因,黄仁勋在开场时也提了,就是Turing是首次将计算机图形学和AI做了统一的架构。
Turing架构时期的Tensor core最初的AI,应当还未曾特别着眼于生成式AI,当时的典型应用如DLSS。而现在Hopper架构的AI,谈论的更多的已经在LLM和生成式AI上了。这5年显然是NVIDIA做AI技术储备最重要的5年:GPU架构、互联技术、networking方案、AI生态与软件等等……
“有人曾说过,我相信在场的各位可能也听过。”大概是本场主题演讲被黄仁勋玩了3、4次的梗,“我也不知道是谁说的,‘买得越多,省得越多’(the more you buy, the more you save)。”这是在对比GH200构成的计算集群与x86 CPU计算集群的成本、功耗、算力时说的。
这句黄仁勋讲了多年的经典名言,也令主题演讲现场的观众普遍的会心一笑——只不过是从当年更纯粹的图形渲染,发展到CUDA通用计算,以及现在的生成式AI加速。

除了Hopper架构GPU更新外,Ada Lovelace架构图形卡这次也做了更新,包括RTX 5000、4500、4000,以及L40S。有所不同的是,NVIDIA刻意强调了这些图形卡LLM推理性能。
比如宣传新款RTX 5000,就不光是说图形渲染性能提升,还特别强调相比于Ampere架构1.5倍的生成式AI推理性能增强。还有搭载4张RTX 6000的新款工作站,针对GPT3-40B模型的fine-tune,在8.6亿token的情况下耗时大约15小时,SDXL(Stable Diffusion XL)推理每分钟出40张图,比GeForce RTX 4090快5倍。
以及配非常多8张L40S的新款OVX服务器相比上一代用A100的老款,fine tune性能提升1.7倍,SDXL每分钟出图80张……你看现在针对RTX显卡的宣传画风,都已经在往生成式AI靠了,果然此时的GPU,已经不是彼时的GPU了…
自去年到今年生成式AI爆发以来,数千份相关的研究paper、120亿美元输入给了做生成式AI技术初创企业,大量现有企业争先恐后地渴望引入生成式AI。行业要发展的肯定不会只是ChatGPT、Midjourney这种面向个人的服务。
生成式AI市场“爆发”的根本,还是要将其引入到更多的行业,并最终落地——就像前文列举工业市场的应用。去年“生成式AI”这个词还没火的时候,NVIDIA发布的NeMo,就是将大模型适用到特定领域的工具。比如ChatGPT虽然特能聊,但无法直接套用到零售机器人身上的——还需要为GPT模型提供特定的上下文、数据、“例子”;将大模型真正融入到不同行业、不同企业的业务中去,对大模型进行所谓的“guardrail”和“fine tune”。
这次针对生成式AI的普及,NVIDIA所做的发布主要包括三个项目。(1)和全球最大的开源AI模型社区Hugging Face合作,基于NVIDIA做AI模型定制和部署的全流程工具,包括NeMo,社区模型以后可以直接在DGX Cloud上训练和调整。换句话说,NVIDIA的AI云训练平台直接对接了全球最大的AI模型社区。

(2)发布名为AI Workbench的新工具——这项服务的目标是“让每个使用GPU的人都成为生成式AI创作者”。在任何位置,都能进行生成式AI相关的操作,包括云、数据中心、PC与工作站。
这套工具的本质是把一些对AI模型做fine tune和guardrail,或者优化所需的、有依赖的runtime和库都自动打包好,“一键将全部工程迁移到不同的平台”。
NVIDIA在demo中列举的一个典型用例是首先把AI Workbench装到一台GeForce RTX 4090的笔记本上,在这台设备上尝试做一个SDXL项目。随项目变得复杂,要求更高的算力和存储资源,那么用AI Workbench就能把它迁移到RTX 6000工作站上——迁移过程里,AI Workbench会自动创建项目环境,构建所有依赖;最终为容纳更大的模型,或寻求更大范围的模型定制,将项目扩展到数据中心…
除此之外(3)NVIDIA AI Enterprise全栈也更新到了4.0,这应该也是AI Workbench实现的基础之一。掌握从底层芯片到AI应用的全栈复杂性,是NVIDIA能够将AI真正部署到任意位置,并快速扩展其覆盖范围的关键能力。而上述AI生态相关新的发布、合作或更新,显然是为了AI能够更快地普及和落地。
不管是不是为了建设元宇宙,或者用于图形创作、数字孪生吧…既然是在SIGGRAPH发的,那就当做是为元宇宙和图形技术而作…虽然我们都认为生成式AI未来是要普及到千行百业的,远不限于现在看到的这些。
用黄仁勋的话来说是:“AI并不是某个具有特定能力的小插件,而是软件未来的方向,是计算未来的方向。它将存在于每个应用,跑在每个数据中心、每台计算机,无论是边缘还是云。”元宇宙在此大概成为了AI技术普及的一个载体。

最后聊点儿可能有些多余的话题。从2018年NVIDIA首次展示Turing架构GPU,演示星球大战的光追demo,“这个演示可能大约包含了50万多边形,每像素2条光线(2 rays/pixel),每条光线少量几次的反射。”
“我们为之加入了环境光遮蔽、区域光源、镜面反射,整体是光栅化与光线追踪混合的一个demo。”黄仁勋说,“以720p 30fps渲染,再用DLSS超分到4K。这个演示在当时看来是非常惊艳的。”
而今年,NVIDIA GTC上展示的Racer RTX——就是那个玩具赛车demo,“2.5亿多边形、10光线/像素,每条光线大约10次反射。”“整个场景是完完全全的光线路径追踪(path traced),没有用光栅化。并且以1080p 30fps渲染,再借助DLSS技术——每8个像素,就只有1个是渲染出来的,达成4K 30fps。”
之所以说这部分多余,是因为这篇文章还是借着图形的外衣,内里聊生成式AI。而逻辑上,至少我们看到,就现阶段来看生成式AI还没有对图形技术发展产生多大的帮助作用——即便DLSS之类的AI技术是起到了作用的。
但5年期的这种变化,从光追技术开始商用,到普及和实时流畅运行,不都是电子科技产业的写照吗?生成式AI也是从GPU的发展里衍生出来的。5年前应该都还没人预料到生成式AI在今天的火热,以及在数字化进程中,它对行业和社会造就的价值。
文章来自:https://www.eet-china.com/







