











此前我在探讨英伟达BlueField DPU产品的文章里曾经提到过,或许英伟达较早收购Mellanox的原因,并不是对DPU这类形态的处理器有前瞻性的市场信心,而在于英伟达要搞HPC大规模集群计算——光有CPU、GPU这种单点高算力芯片是不行的。
因为当算力需求扩展到跨芯片、跨系统、跨节点,也就是很多设备要联合起来一起跑的时候,无论是超算、HPC还是AI等应用,计算网络、networking,以及包括安全、虚拟化等在内的各种衍生问题都会产生。如果没有一个能够hold住全场的方案来解决这些问题,那么单节点内的CPU、GPU性能再彪悍,在做算力扩展时也会很悲惨。
这应该是英伟达DPU诞生的一个重要基础。还有一些佐证是,实则与networking相关的基础设施,英伟达也不只在DPU芯片上做布局,还包括Spectrum-4交换机、NVLink之类的东西。而且像Spectrum-4交换机和一般的网络交换机差别甚大,几乎就可以认为是为英伟达HPC生态特别准备的。所以Bluefield DPU最初职能可能是服务于自身;单独拿出来卖大概只是顺便…
扯远了……这个例子实则可用以说明,DPU这种芯片形态的存在价值也不单是我们日常认知中的offload(卸载)原属于CPU的数据传输、存储、安全、虚拟化等工作。前不久中国信息通信研究院主办的2023 ICT+深度观察报告会算网融合发展分论坛上,中国信通院联合开放数据中心委员会发布了《DPU发展分析报告(2022年)》。

这份报告就在第三大章节提及DPU的“核心技术价值”时,将前述这个例子概括为“算力扩展”。“在计算单元的工艺演进已逼近极限,每18个月翻一番的摩尔定律即将失效的情况下,为了满足大算力需求,通过分布式系统,扩大计算集群规摸,提升网络带宽,降低网络延迟成为提升数据中心集群算力的主要手段。”DPU及包含RDMA在内的各种技术的涌现都着力于解决这样的问题。
除了“算力扩展”,还有我们对于DPU认知相对普遍的“算力卸载(offload)”和“算力释放”,是相对全面的概括。有兴趣的读者可以下载查看这份报告——这是一篇对DPU相对概览性质的导读,对于DPU的定义、作用,发展现状和周边技术,及配套政策、未来市场潜力都做了解读。
前年底的2022全球半导体行业10大技术趋势展望中,我们就提到了DPU市场持续做大和爆发的未来预期。这是基于此前数据中心很流行的一个词“数据中心税”而起的——服务器会配置大量核心的CPU,但对最终业务而言,其中一部分核心是默认被“吞噬”的。因为这些处理器资源需要用来做数据networking、安全、存储、虚拟化等工作。
当这些工作变得复杂,DPU自然就出现了。就像针对图形计算有GPU,针对AI计算有NPU,DPU也成为这个时代下崛起的一大类处理器。一般我们说DPU的工作包括了名列前茅,offload原属于CPU的OVS、存储、安全服务之类的活儿;第二,以hypervisor管理做隔离、虚拟化实现;第三是以各种方式,进一步加速跨节点的数据处理。
在我们看来,DPU出现并大热的基础是摩尔定律的放缓。早在2018年,我们就撰文详述过,随着摩尔定律停滞和半导体制造成本的显著攀升,专用计算、DSA必然成为诸多应用的发展趋势,因为通用计算已经无力承担市场需求的算力提升幅度和速度。NPU、DPU存在的根本皆如是。再偏激一点的言论是,在数据中心某些特定应用领域,通用计算处理器——也就是CPU会逐渐被边缘化。
不过我们始终没有非常细致地对DPU做技术剖析,主要原因是,DPU这个类型的芯片尚在发展早期,以及DPU更类似于一个系统,其构成方式也相对多样——甚至不同企业的DPU产品,解决的问题也可能存在环节、特性或侧重点上的显著差异——如前述DPU的职能多样化,它不像GPU一样就是单纯做图形渲染,或者像NPU那样专做矩阵乘加运算…比如networking和虚拟化就是两种不同的工作类型。
换句话说,DPU尚不存在“标准化”一说。几十年前GPU尚处在发展初期时,情况实则也差不多。这表明DPU这类硬件可能还有很长的路要走。
《DPU发展分析报告(2022年)》第三章节“DPU成为迈向‘联接+计算’的关键一步”,对于DPU的定义、发展、作用和应用方向都做了相对通俗和到位的解读,虽然并未细致到不同的DPU产品,却搭建起了对DPU认知的大框架。
比如在定义部分,明确英伟达BlueField与其CX系列网卡的区别在于,前者有Arm多核CPU核心,满足控制平面的负载offload,“以此实现DPU的基础设施服务的全卸载和宿主机业务物理上的安全隔离”;最终明确“广义上的DPU是基于异构DSA架构,采用软件定义技术路线,支撑基础设施资源层虚拟化,具备提升计算系统效率、降低整体系统的总拥有成本的能力,为高带宽、低延迟、数据密集的计算场景提供计算引擎的专用处理器”。
再比如在“DPU究竟有什么用”(DPU的核心技术价值)的问题上,做了高抽象层级的解读,包括在“算力offload”部分,不仅是消除“数据中心税”,还在于很多人所忽略的DPU达成的安全特性:包括数据的加密解密,以及DPU满足用户数据安全和物理隔离需求的结构特点……除此之外,报告也对DPU的具体构成做了解读,包括CPU/NP、FPGA+CPU、AISC+CPU等……
这份报告的整个第四章节,都在探讨推动DPU发展的几个关键技术和因素,包括RDMA高速网络技术、数据面转发技术、网络可编程技术,以及开放网络及DPU软件生态。
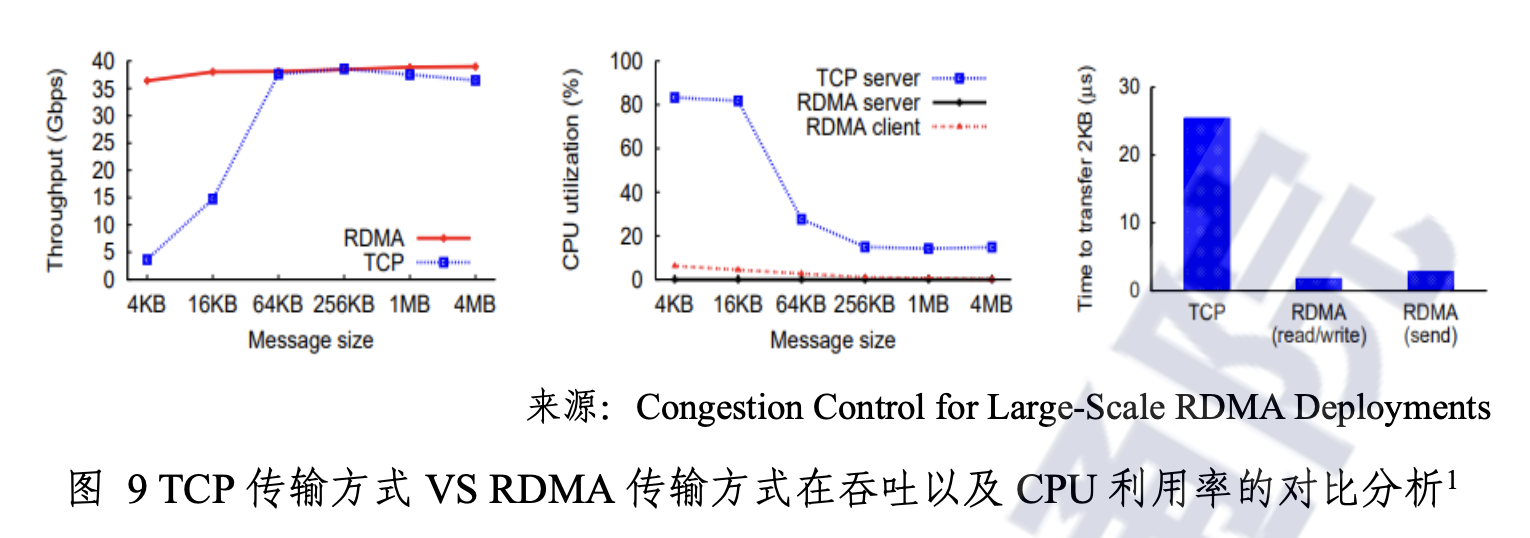
RDMA也就是远程直接数据存取——这种技术将数据直接从一台计算机的内存传输到另一台计算机的内存。数据从一端主机的内存通过DMA方式从网卡转发出去,到另一端通过网卡DMA直接写入另一端主机的内存,整个数据传输过程无须操作系统和CPU参与。这份报告认为,在TCP协议栈内核转发无法满足性能要求的情况下,RDMA承担基础网络传输功能,提升数据中心整体算力。
“RDMA凭借其高吞吐、低延时、CPU旁路、适应性广、技术成熟等特点,已成为数据中心技术服务的一个重要组成部分。”RDMA显然是DPU发展的推力之一。

其次是“数据面转发技术”,说的应该就是networking,或者网关/交换。报告中提到,在数据面硬件转发技术中,基本的硬件处理架构有两种:基于NP的RTC(run-to-completion)架构和pipeline架构。报告提到,pipeline转发架构表现出了相对优势——这种流水线架构下,流程拆分成不同处理阶段,然后达成流水线级并行。流水线不同stage可以做固定功能单元,也可以分别做成可编程。这类方案在性能、时延方面都有优势。
所以“从功耗、性能、面积的角度考虑,DPU跟随网络流量需求变化,基于可编程pipeline的硬件架构更符合DPU加速硬件报文转发的发展方向”。
第三是“网络可编程技术”。DPU上的网络可编程技术,包括控制平面和数据平面网络可编程技术。控制平面自然是相关于DPU上的通用处理器,而数据平面相关于配套的加速器——后者当然是关键。因为网络协议是变化发展的,加上自定义网络扩展协议需求,数据平面必须支持网络可编程技术。
“目前DPU数据平面网络可编程技术主要包括基于快速流表和基于P4流水线两种常见技术。”报告对两者都有对应的介绍。包括开发数据中心委员会此前已发布的《P4敏捷可编程转发设计白皮书》《P4超融合网关技术白皮书》。
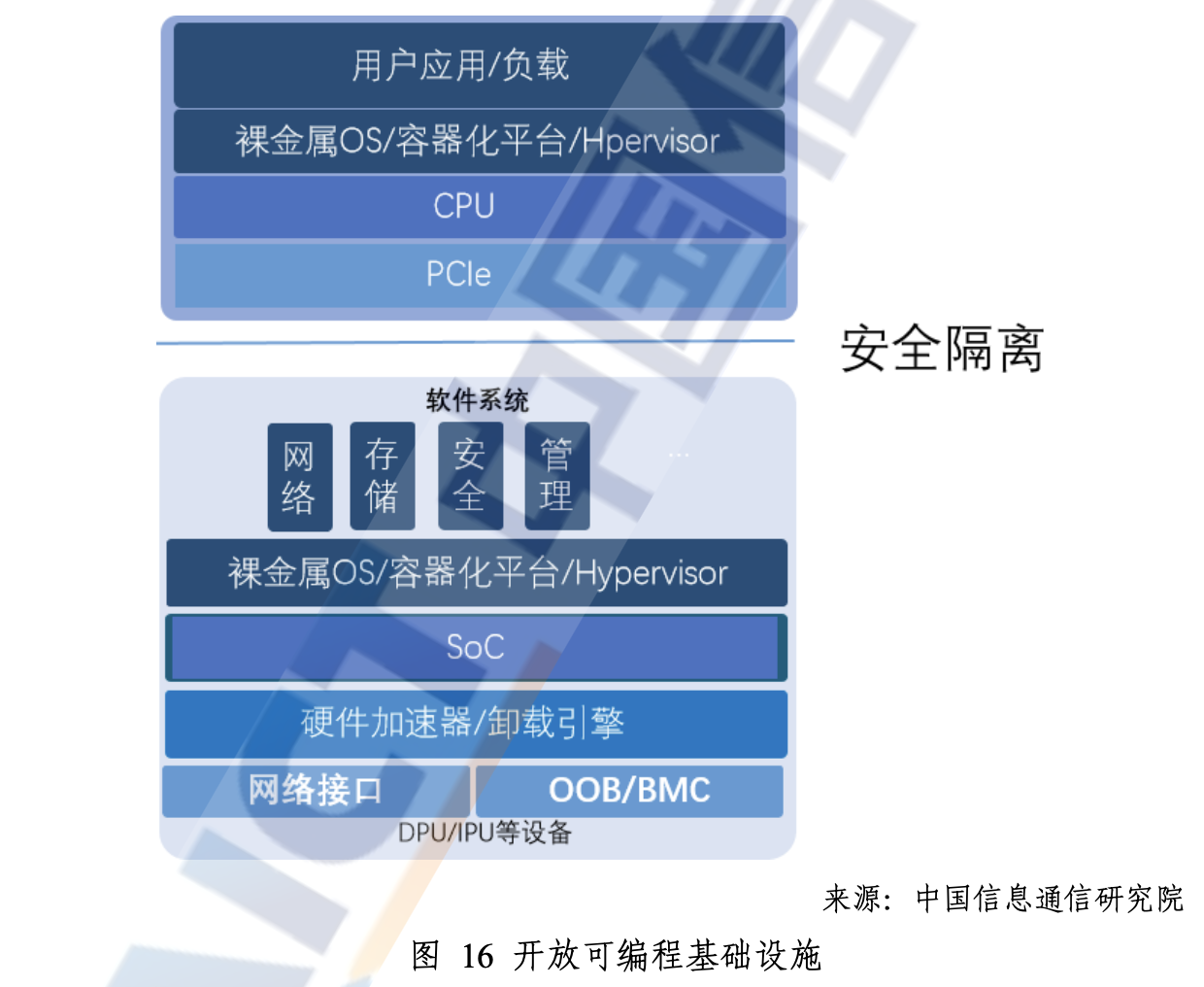
最后,还有“开放网络及DPU软件生态”。作为一种新的处理器类型,而且大方向上是个加速器(主CPU的数据处理硬件加速器),其应用开发是涉及到生态的。关注我们对英伟达报道的读者应该对DOCA已经比较熟悉。这份报告中提到,目前市场上主流的开放网络及DPU软件生态主要有Linux基金会宣布的开放可编程基础设施OPI,Intel驱动主导的IPDK,英伟达的DOCA,开放数据中心委员会开展的无损网络项目等。
“在DPU软件生态层面,DPU实际上还是以网络为基础,通过网络业务模型创新和硬件加速技术,来构建和拓展存储和安全业务,进而提升计算业务的效能,实现数字基础设施变革。”报告认为,开放网络软件生态不应该是“各家DPU厂商另起炉灶、各立门户”的,毕竟这关乎到DPU这个类别硬件的创新发展。
基于DPU目前仍处在发展早期,硬件结构形态尚无明确定论,市场竞争者的混战恐怕还会持续很久。我们倒是认为,唯有在市场进入成熟期,DPU生态才会相对平稳和统一。实际上,可编程平台、通用软件生态的潜在应用与场景开拓,是为DPU未来发展提供了各种可能性的基础。

上面这些总括了《DPU发展分析报告(2022年)》的部分关键内容。其他相关内容,还是建议感兴趣的读者前往下载查看,此处不再多做赘述。包括DPU这类硬件在中国的发展机会,如DPU契合“东数西算”这类工程的开发需求,以及相关的政策支持等。
实际在2023 ICT+深度观察报告会算网融合发展分论坛上,中国电信、云脉芯联、华为、浪潮、英伟达等企业代表都做了对于算网融合发展的主题演讲。不仅是国际厂商正在DPU市场发展过程中做前期部署,有一系列的产品研发、收购和生态扩展动作;国内市场参与者也不想在这方面落后。
比如其中云脉芯联就在演讲中谈到已经推出的“国内首款自主研发支持2口100G RDMA智能网卡产品”。云脉芯联产品负责人孙伟分享了云脉芯联基于DPU芯片的TOP创新架构,TOP分别表示Converged Transport(融合互联)、Open Platform(开放平台)、Hyper Performance(极致能效)。
从介绍来看,这家公司的DPU产品似乎在各方面都契合《DPU发展分析报告(2022年)》提到的相关技术趋势,比如说通过“开放的可编程的Pipeline、可编程的拥塞控制算法平台”提供灵活性,适配不同应用场景;还有在TOP架构理念的基础上,“通过自主创新的端网、算网、云网等端到端的高性能融合互联引擎,能够提供百G网络吞吐、微秒级网络延迟和百万级网络连接”;以及在DPU产品定义上,“通过异构算力实现加速、存储/网络卸载,实现极致能效”等…
云脉芯城在介绍中提到,公司“在创立近2年的时间里完成了DPU核心技术RDMA技术和可编程的底层网络接口技术的研发,在RDMA高性能网络传输,基础设施服务卸载和IO虚拟化三大关键技术上实现了突破”。
结合报告,可以更好地理解云脉芯城为什么做了这样的开发与规划。据说在商业落地方面,其自研DPU也推进顺利,“目前云脉芯城已与国内头部数据中心解决方案供应商合作推进无损网络端网融合解决方案并完成测试”。
国内外企业对于DPU这个形态的硬件都如此重视的根本,当然就在于对这个市场的看好——数据中心的DPU发展共识已无需赘言。报告在未来展望章节中提到,尤其在中国这个数字化转型范围不断扩大的市场中,“DPU覆盖领域将从数据中心逐步向智能驾驶、网络安全、网络储存、云计算、高性能计算、人工智能、边缘计算、数据存储及流媒体等多领域渗透”。看来DPU市场的兴起才刚刚开始。
文章来自:https://www.eet-china.com/







