











易灵思基于创新量子计算结构的FPGA填补了这一空白,该结构由称为可交换逻辑和路由(XLR)单元的可重新配置块(可用作逻辑或路由)组成;它重新思考了传统设计中,逻辑元素(LE)和路由资源的固定比例。这允许在小巧的器件封装中使用高密度结构,其中FPGA的任何部分都得到充分利用。该平台的潜力足以解决当前边缘设备面临的典型障碍:功耗、延迟、成本、尺寸及易开发性。
易灵思 FPGA最引人注目的特点可能是围绕它构建的生态系统和非常先进的工具流,它们降低了开发难度,使设计师能够使用相同的芯片轻松的在边缘实现人工智能——从原型到量产。易灵思 采用了 RISC-V,从而允许用户在软件中创建应用程序和算法——利用此 ISA 的易编程性,而不受ARM等专用IP核的限制。由于这一切都是通过灵活的FPGA 架构完成的,因此用户可以在硬件上大幅加速。易灵思 提供对底层和更复杂的自定义指令加速的支持。其中一些技术包括 TinyML 加速器和预定义的硬件加速器模块(hardware accelerator socket)。通过这些方法实现硬件加速的同时,又保留了软件定义的模型;且无需掌握VHDL即可对模型进行迭代和优化。这使得边缘设备具有极高速度,且同时在小巧封装内实现了低功耗。本文详细讨论了易灵思平台如何简化整个设计和开发周期,使用户能够利用灵活的FPGA结构来实现可扩展的嵌入式处理解决方案。

从大规模无线传感器网络到流媒体传输高分辨率360o沉浸式 AR 或 VR 体验,世界上大部分数据都位于边缘。将计算负担从云端分离出来并使其更靠近终端设备的举措,为自动驾驶、沉浸式数字体验、自主工业设施、远程手术等领域为代表的下一代高带宽、超低延迟应用打开了大门。一旦化解了与云之间互传数据的巨大桎梏,应用场景将无远弗届。
然而,边缘处这些低延迟、高功耗计算的决定性要素,恰恰构成这些小巧但多能的功率受限设备的重大设计挑战。那么,如何才能设计出一款既能够处理耗电的相关ML算法、又无需投资复杂技术的设备呢?解决方案一直是:实现任何被认为足以运行合适应用程序和算法的硬件(例如 CPU、GPU、ASIC、FPGA、ASSP),同时加速执行计算密集型任务以平衡计算时间(延迟)和所用资源(功耗)。
与任何创新一样,深度学习的前景随着模型的更新和优化技术的不断变化,需要使用更敏捷的硬件平台,这些平台的变化要几乎能与在其运行的程序一样快,且恰当的规避风险。FPGA的并行处理和灵活性/可重新配置性似乎可以完美地满足这种需求。但要使这些器件可用于主流、大批量应用,需要降低配置和加速 FPGA 结构的设计障碍——这是个耗时的过程,通常需要较高的专业度。此外,传统的加速器通常不够精细,且包含通常无法很好扩展的模型的大部分。它们一般功耗还太高,且多半采用专有技术——导致工程师需要重新学习如何使用不同器件厂家特异的平台。
用C/C++ 在 RISC-V 核上创建应用
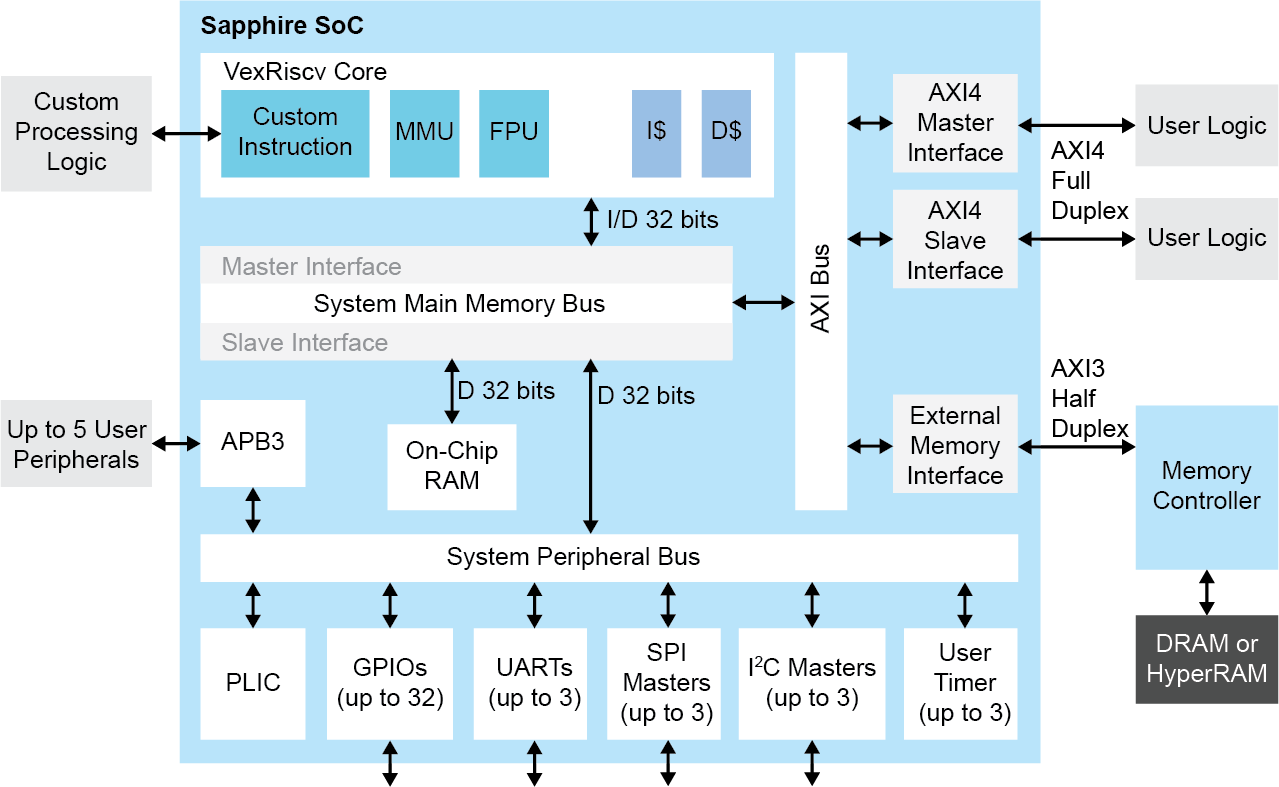
易灵思借助以直观方式向AI/ML社区提供FPGA的解决方案,从而直面所有这些潜在障碍。RISC-V Sapphire 内核可完全由用户通过 Efinity GUI 配置;这样,用户不必了解在FPGA 中实现 RISC-V 的背后所有 VHDL,并且可以利用通用软件语言(例如 C/C++)的直接可编程性。这使设计团队能迅捷地在软件中快速生成应用程序和算法。所有必需的外设和总线都可以与 Sapphire 内核一起指定、配置和实例化,以提供完全配置的SoC(图1)。这种 RISC-V 能力包括多核(非常多四核)支持和 Linux 功能,可为设计人员的FPGA应用提供高性能处理器集群,并能够直接在 Linux 操作系统上运行应用。下一步——硬件加速——通过硬件-软件分区大大简化;一旦设计师在软件中完善了算法,他们就可以逐步在灵活的 易灵思 FPGA 结构中加速这一过程。但在我们继续下一步硬件加速之前,了解 RISC-V 架构的固有优势以及如何在 FPGA 结构中利用它是很重要的。
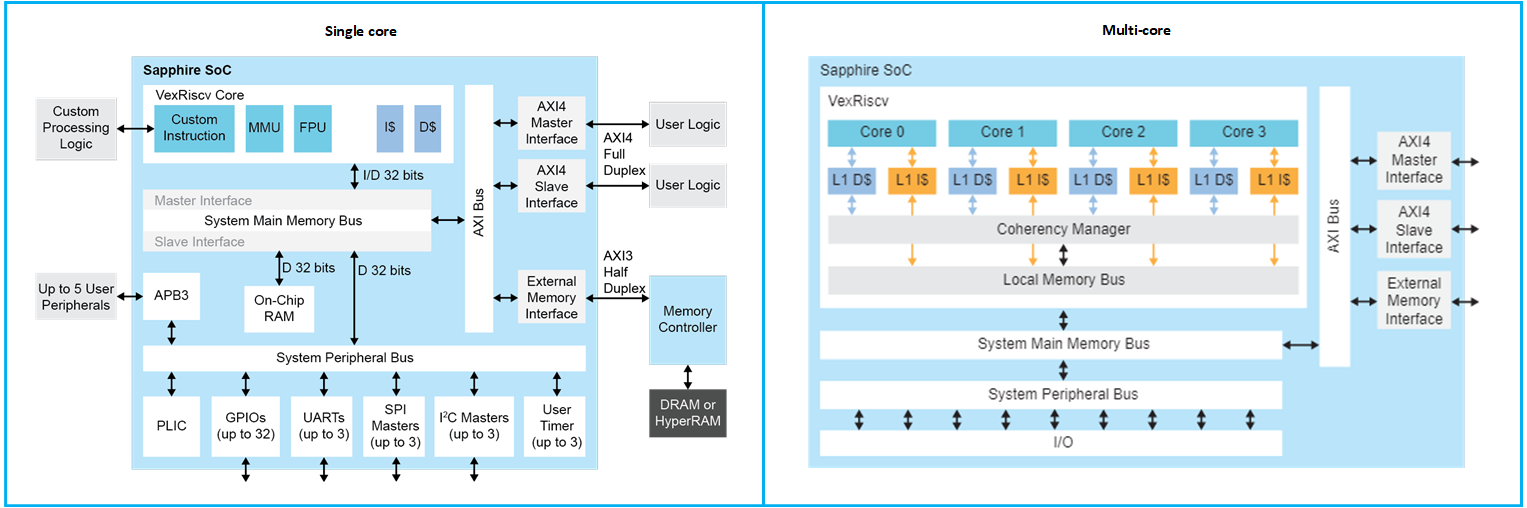
图 1:Efinity GUI 使设计师能够使用熟悉的编程语言配置其 Sapphire RISC-V核(左)以及所需的外设和总线,以实现完全配置的SoC。此功能扩展到非常多四个RISC-V核(右)。
具有定制指令能力的RISC-V
RISC-V 架构的独特之处在于它没有定义所有的指令;实际上,它将有些指令留待设计师定义和实现。 换句话说,可以创建一个自定义算术逻辑单元(ALU),它会在自定义指令调用时执行任意功能(图 2)。这些自定义指令具有与其余指令相同的架构(例如,两个寄存器输入,一个寄存器输出),保证总共可使用八个字节的数据,且其中四个字节可以传回RISC-V 。
然而,由于 ALU 构建在 FPGA 中,它既可以访问 FPGA数据、也可以从FPGA内提取数据。这允许用户扩展超过 8 个字节的数据,并使 ALU复杂性提高——访问之前放在 FPGA 内的数据(例如来自传感器)。就硬件加速而言,拥有任意复杂程度ALU 的能力是速度倍增的关键因素。易灵思 已经具备了定制指令的能力,并通过TinyML平台将其适配于AI和ML社区。
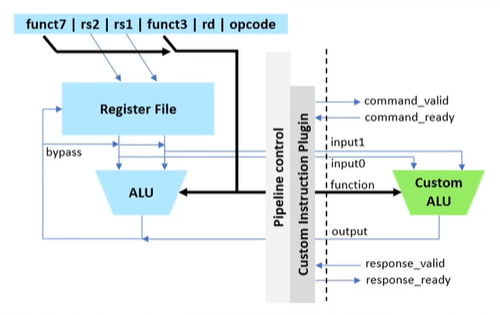
图 2:可以使用RISC-V创建自定义ALU,其中标准配置包括两个四字节宽的源寄存器(rs1 和 rs2)和一个四字节宽的目标寄存器 (rd)。
**图2抓取自TinyML 网络研讨会,可向易灵思 索取原始图像
使用TinyML平台进行硬件加速
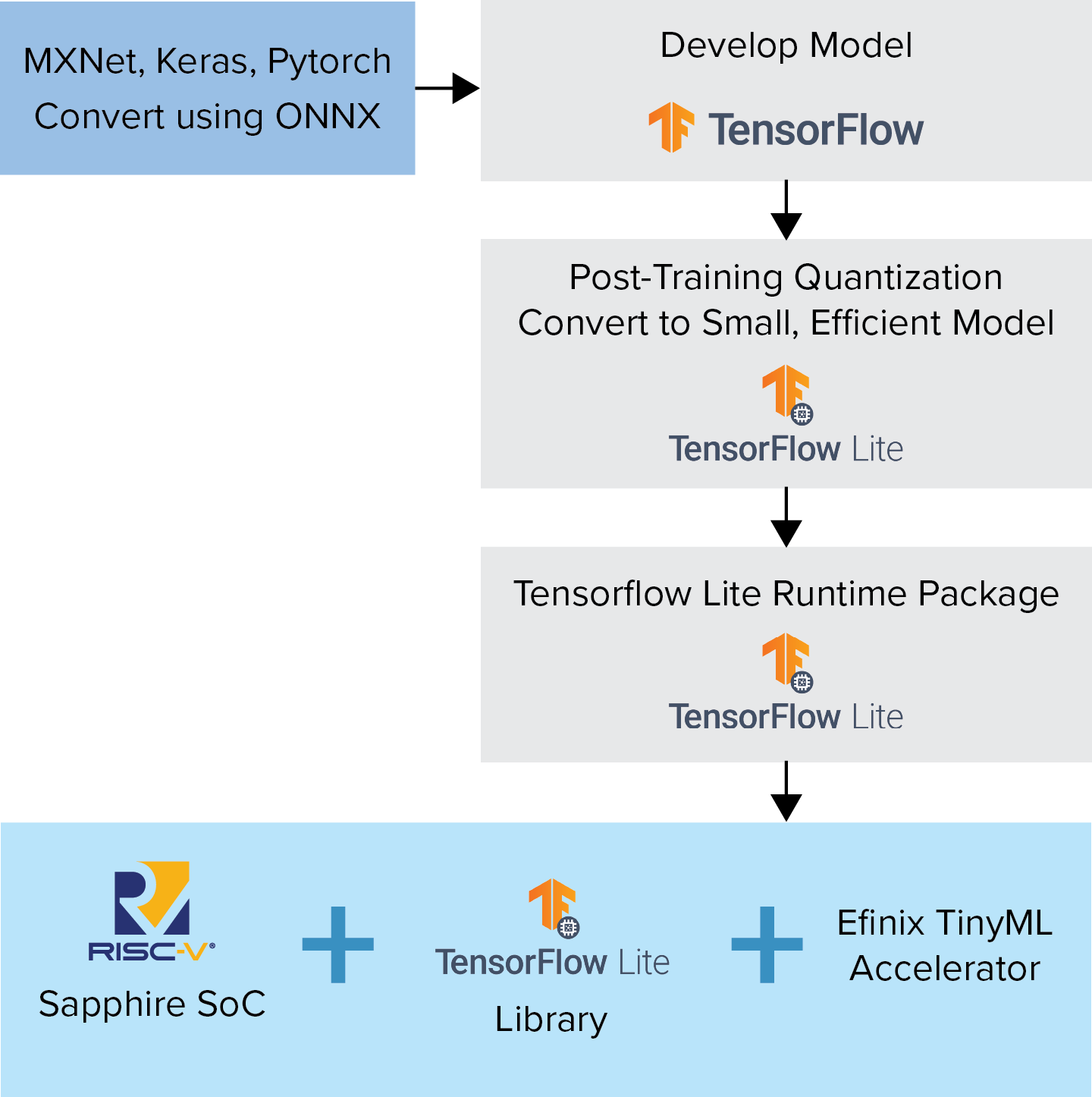
TinyML 平台简化了硬件加速过程,其中易灵思 采用了 TensorFlow Lite 模型中使用的计算原语,并创建了自定义指令以优化其在FPGA结构中加速器上的执行(图3)。通过该方式,TensorFlow 的标准软件定义模型被吸收进RISC-V中,并被加速到硬件速度水平;充分利用了丰富的开源 TensorFlow Lite 社区资源。使用流行的Ashling工具流简化了整个开发流程,使设置、应用创建和调试成为一个简单直观的过程。

图 3:TensorFlow Lite创建标准 TensorFlow 模型的量化版本,并使用函数库让这些模型能在边缘的MCU上运行。易灵思 TinyML采用这些TensorFlow Lite模型,并使用 RISC-V 核的自定义指令功能,在 FPGA 硬件中加速这些模型。
许多TinyML平台的自定义指令库都在易灵思 GitHub 上的开源社区开放,可以免费访问易灵思 Sapphire 核以及设计和开发高度加速的边缘AI应用所需的一切。
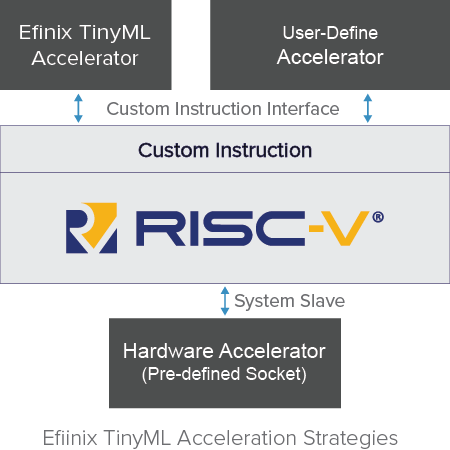
RISC-V核、易灵思 FPGA 结构和丰富的开源TensorFlow社区的结合赋能创造性的加速策略实现,可将其分解为以下几个步骤(图 4):
第 1 步:使用Efinity RISC-V IDE运行 TensorFlow Lite模型,
第2步:使用TinyML加速器,
第3步:用户定义的指令加速器,
第4步:硬件加速器模板。
如前所述,“第1步”是贯穿Efinity GUI 的标准流程,用户可在其中获取Tensorflow Lite 模型并在 RISC-V 上使用与标准 MCU 完全相同、熟悉的流程在软件中运行它——不必担心VHDL。在第1 步之后,设计师大概率会发现其正在运行的算法的性能并非优异,因此需要加速。“第2步”涉及硬件-软件分区,用户可以在其中实现TensorFlow Lite 模型中的基本构建块,然后直接单击并拖动以实例化自定义指令,使模型在 Sapphire RISC-V 核上的运行(方式)得到巨大加速。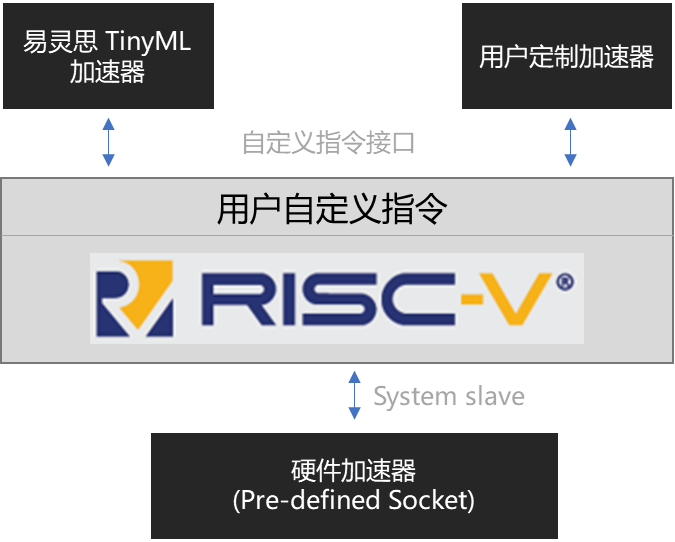
图 4:易灵思 加速策略。
用户自定义指令加速器
“第 3 步”支持设计师可在不使用TinyML平台中模板的情况下创建自己的自定义指令,从而允许用户在 RISC-V 核上实施创新、创建加速。
硬件加速器模板
最后,在 RISC-V 上加速所需的基本要素后,“第 4 步”将它们植入带有加速“Socket”的免费 易灵思 SoC 框架中。该量子加速器”Socket”允许用户“指向”数据、检索数据并编辑其内容;例如,对更大数据块执行卷积操作。
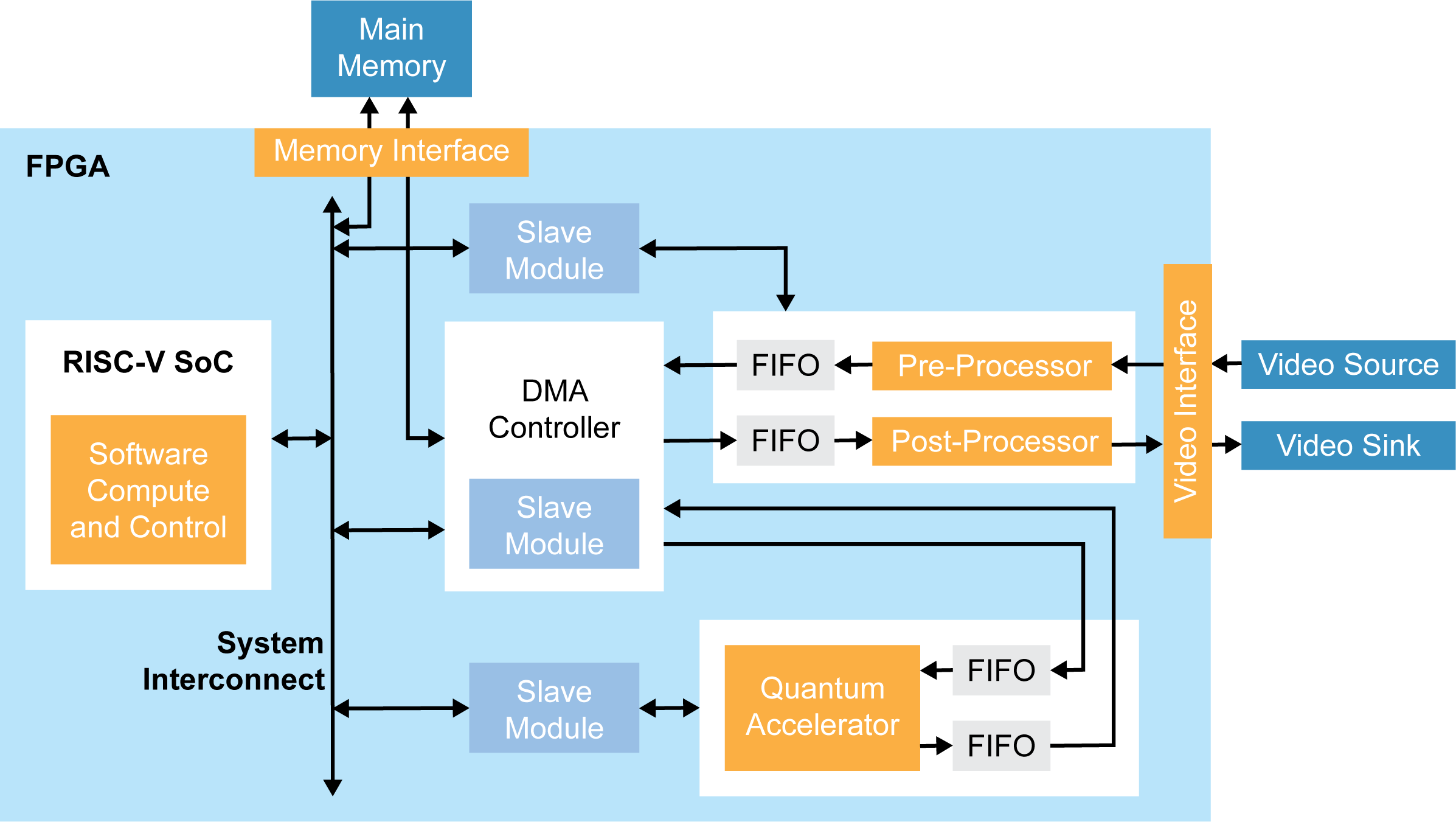
Sapphire SoC 可用于执行整体系统控制及执行固有顺序型或需要灵活性的算法。如前所述,硬件-软件协同设计允许用户选择是在 RISC-V 处理器中还是在硬件中执行此计算。在这种加速方法中,预定义的硬件加速器”Socket”连接到直接内存访问 (DMA)控制器和用于数据传输和 CPU 控制的 SoC 从接口,可用于人工智能推理之前或之后的预处理/后处理。DMA控制器实现了外部存储器与设计中其它构建块之间的通信(图 5):
在图像信号处理应用中,这看起来像是让 RISC-V 处理器与嵌入式软件一样执行 RGB 到灰度的转换,而硬件加速器在FPGA的流水线、流式处理架构中执行Sobel边缘检测、二进制腐蚀(binary erosion)和二进制膨胀(binary dilation)(参见“Edge Vision SoC 用户指南”)。这可扩展到多相机视觉系统,使用户能以极快的速度将其设计转化为产品并进行部署。
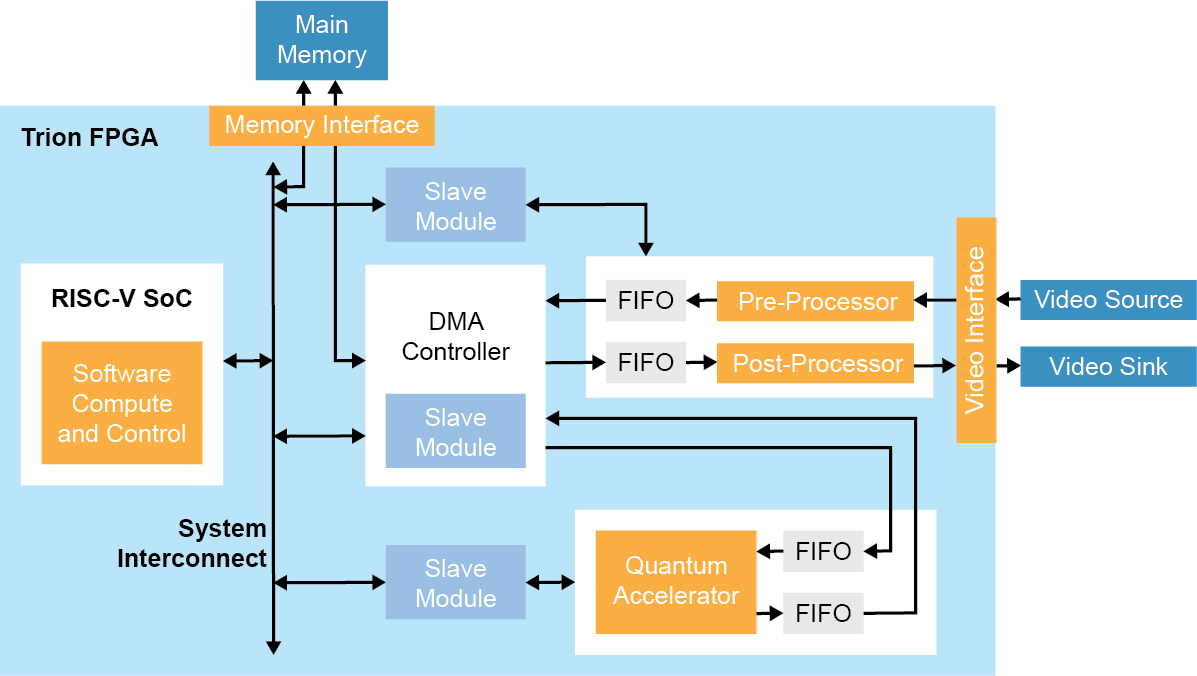
图 5:边缘视觉 SoC 框架示例图。
我们通过下面的案例来凸显该过程的简单性。MediaPipe Face Mesh(人脸网格)ML 模型实时估算数百个不同的三维面部特征。易灵思 采用此模型并将其部署在以300MHz运行的 钛金系列 Ti60 开发套件上。如图 6 所示,RISC-V核上运行的卷积对延迟的影响最大。要注意的是,FPGA 接近 60% 的资源占用率并不能实际反映 ML 模型的大小。实际情况是因为整个相机子系统都在 FPGA 中实例化,以便实时执行加速基准测试。
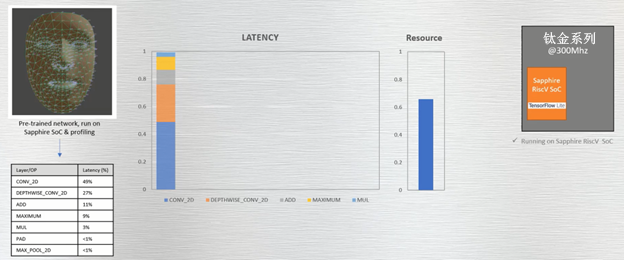
图 6:在 Ti60 开发套件上运行的 MediaPipe Face Mesh 预训练网络显示了延迟和所用资源。
使用 TinyML 平台的简单自定义指令(第 2 步)
创建并运行一个简单、自定义的——两个寄存器输入、一个寄存器输出——卷积指令,显示延迟时间缩短了四到五倍。随着用于加速 ADD、MAXIMUM 和 MUL 函数的自定义指令的应用,可进一步缩短延时。但由于 RISC-V 花费更少的时间执行这些操作,延迟改进会达到一个稳定水平(图 7)。
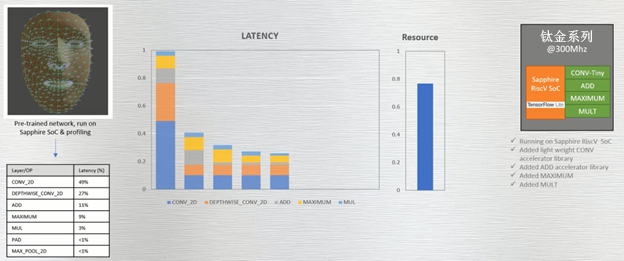
图 7:借助为 CONV、ADD、MAXIMUM 和 MUL 函数创建的简单自定义指令可显着缩短延迟。
使用DMA的复杂指令(第 4 步)
生成一个任意复杂的 ALU 来替换原始CONV。此举改变了原始曲线的斜率并再次显著的缩短了延迟。然而,由于复杂指令占用了FPGA 内部的更多资源,因此FPGA 的占用率也有所上升。再次强调:资源接近 100% 占用率的原因仅仅是因为该FPGA 包含了用于演示目的的整个相机子系统;需要注意的是延迟的相对缩短和资源占用率的上升(图 8)。
值得指出的是,若切换到更大逻辑规模的FPGA(例如 Ti180),在不到50% 可用FPGA资源的情况下,就可运行所有这些复杂的指令以实现大规模加速。这些明显的权衡恰恰使工程师能够轻松地可视化FPGA的延迟、功耗和成本/体积之间的取舍。具有严苛的延迟要求但更宽松功耗指标的边缘应用可选择更多的加速设计以显着提高性能。而在功耗严苛的应用中,降频降耗的诉求会抵消提升性能的努力,其间的权衡取舍应可实现以显着降低的功耗获得更适度、划算的性能提升。
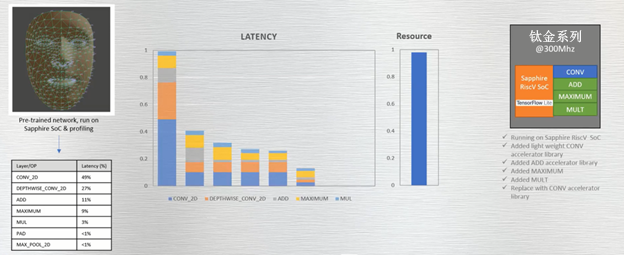
图 8:采用更大的自定义卷积指令以实现更快加速;但消耗的资源也水涨船高。注意:FPGA几乎被完全占用仅仅是因为该FPGA包含了整个相机子系统,如果 Ti60 只运行 ML 模型,其资源占用将大大降低。

简言之,易灵思 结合了熟悉的 RISC-V ISA 开发环境,并利用其自定义指令功能在架构灵活的 FPGA 结构中发挥作用。与许多硬件加速器不同,这种方法不需要任何第三方工具或编译器。借助机器指令加速实现的加速也是细粒度的——这是只有FPGA才可能实现的粒度级别。
边缘设备可在 易灵思 FPGA 的创新设计架构上进行原型设计和部署这一事实意味着该解决方案是面向未来的。可以在熟悉的软件环境中表达新模型和升级的网络架构,并在自定义指令级别实施加速,而只需少量 VHDL工作(带用于引导的可用模板库)。这种程度的硬件-软件分区(其中90% 的模型保留在RISC-V上运行的软件中)支持极快的上市时间。所有这些方法的组合产生了一个优雅的解决方案,真正降低了实现边缘设备的进入门槛。设计师现在有世界优异的嵌入式处理功能可用,可通过非常先进的工具流访问该功能,并在革命性的易灵思 Quantum 结构上进行实例化。
本文由易灵思供稿,电子工程专辑对文中陈述、观点保持中立
文章来自:https://www.eet-china.com/








{kind=link}
{kind=link}
{kind=link}
{kind=link}