











据路透社消息,当地时间周一(5月23日),英特尔(Intel)就其计划于2025年推出的一款人工智能(AI)运算芯片提供了更多细节。
英特尔在德国举行的一个超级计算会议上表示,即将推出的“Falcon Shores” (猎鹰海岸)芯片将拥有288GB的HBM3内存和 9.8TB/s 的总内存吞吐量,正如预期的那样,它将支持较小的数据类型,如 FP8 和 BF16。这些细节也是英特尔实施战略转型,抢占人工智能处理器市场,以追赶英伟达和AMD的首批披露内容。

Falcon Shores是在Rialto Ridge 取消后的替代品,也是 Ponte Vecchio 的指定后续产品。根据早前报导,Falcon Shores 将会是一款混合型态的XPU产品,因为在这个封装内将会整合 GPU、CPU 与 Memory 在内。然而在周一的会上,英特尔确定 Falcon Shores 将不再是 XPU,而回归到单纯的 GPU 而已。

Falcon Shores GPU 将会是英特尔Xeon Max GPU 系列产品中的一环,采用标准以太网交换,很像英特尔专注于 AI 的 Gaudi 架构。此外,Falcon Shores GPU 将会如同 Ponte Vecchio 般采用Chiplet模块式设计,允许针对单一 GPU 进行程序处理。这个基础性架构非常灵活,可以随着时间的推移集成Intel和客户的新IP(包括CPU内核和其它芯粒),使用Intel IDM 2.0模式制造。
该设备的基本草图还包括一个通用的基于 GPU 的编程接口 OneAPI,它将允许与其他 CPU 和架构广泛兼容。 英特尔还将 CXL (Compute Express Link)支持列为一个关键的差异化因素,这让GPU、AI 芯片和其他加速器可以轻松访问大型存储和内存池。
下面我们来分析一下英特尔从 Falcon Shores 中抽出 CPU 内核背后的深层次原因。
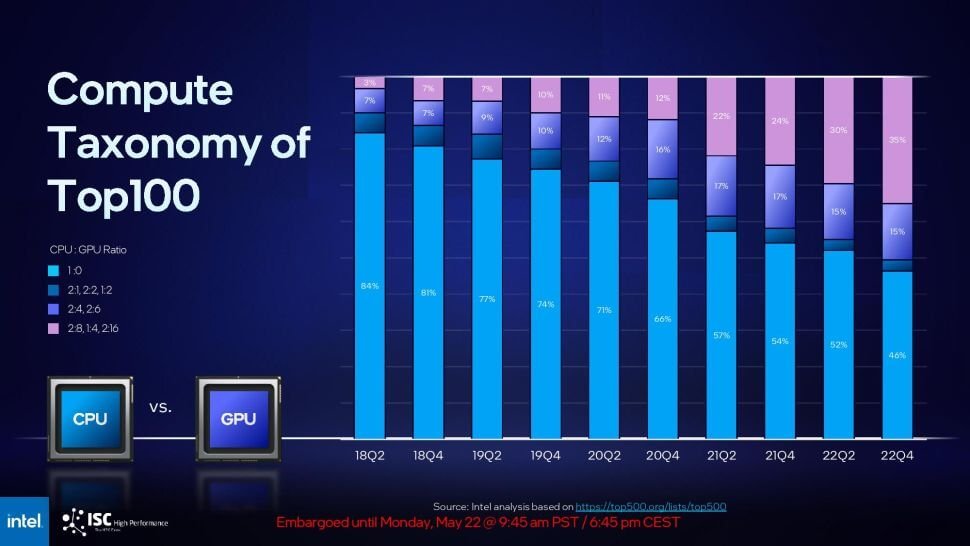
英特尔表示,当前计算环境还不成熟,要实现将 CPU 和 GPU 内核混合到同一个 Falcon Shores 封装中的最初目标还为时过早。 如上图所示,随着生成 AI 和 LLM 进入 HPC 空间,不同处理器的工作负载在改变,CPU 和 GPU 内核的优异组合随着时间的推移而发生变化。 因此也引发了英特尔关于如何构建下一代超级计算架构思维的转变,他们认为现在还不是将客户锁定在特定 CPU 和 GPU 比例的时候。
此外,从设计上讲,处于前沿的超级计算机是针对特定任务的高度专业化设计,针对架构的软件调整只是运行超级计算机的常规操作。 这些因素意味着 CPU/GPU 比率并不是英特尔从设计中移除 CPU 内核的少数原因。
英特尔还指出,Falcon Shores允许其客户使用各种不同的 CPU,逻辑上包括 AMD 的 x86 和 Nvidia 的 Arm 芯片,以及他们的 GPU 设计,因此不会限制客户只选择英特尔的 x86 内核,CPU 和 GPU 的解耦将为具有不同工作负载的客户提供更多选择。
英特尔表示,使用CXL接口的目的是让其客户能够利用可组合的架构,在他们的定制设计中将各种 CPU/GPU 比率结合在一起。 然而,CXL 接口仅在芯片组合之间提供 64 GB/s 的吞吐量,而像 Nvidia 的 Grace Hopper 这样的定制 CPU+GPU 设计可以在 CPU 和 GPU 之间提供高达 1 TB/s 的内存吞吐量。 对于许多类型的工作负载——尤其是需要内存带宽的 AI 工作负载,这比 CXL 实现具有性能和效率优势。
一直到 2025 年的 Falcon Shores 出来前,Ponte Vechhio 仍是英特尔AI及 HPC 市场的优异 GPU 方案。它将不得不与更先进的 HPC 架构竞争,例如 Nvidia 的 Grace Superchips 和 AMD 即将推出的CDNA3/Zen4 混合体(exascale APU) Instinct MI300,它们都会在 2023年推出。
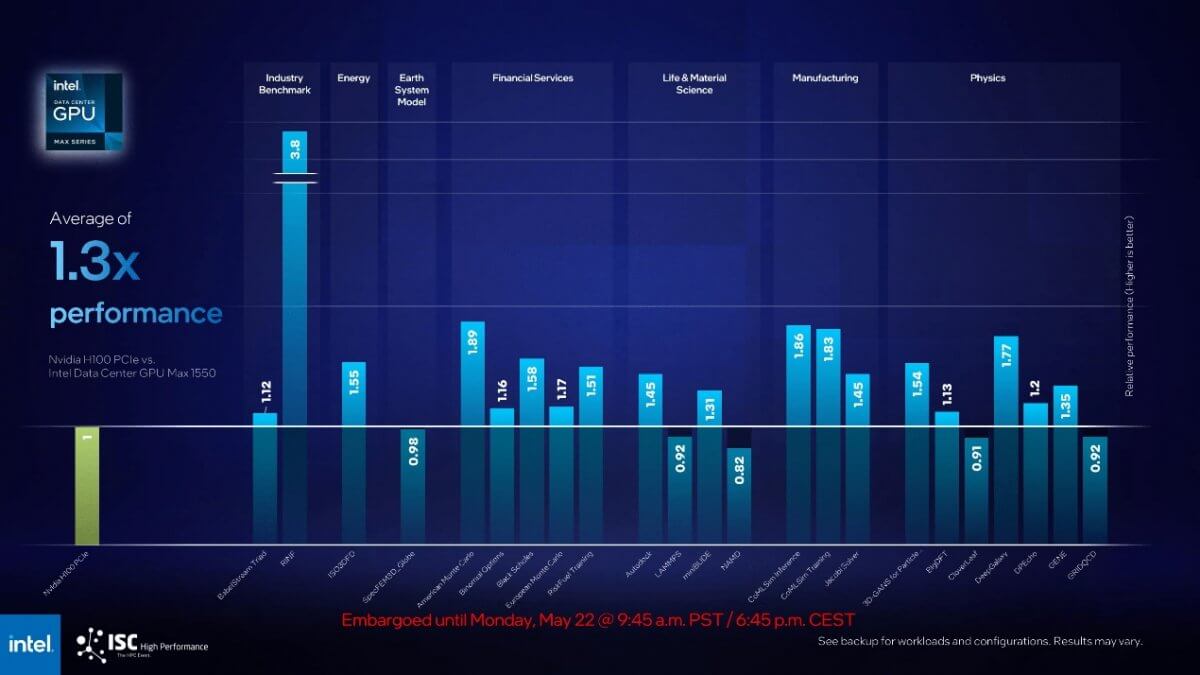
英特尔数据中心 GPU Max 1550 (Ponte Vecchio) 与 NVIDIA H100 PCIe (Hopper)对比
此次更动 Falcon Shores 的原因主要是英特尔目前规划拥有 2 条产品线,而 Falcon Shores 的推出将大幅度提升产品的灵活性。至于 HPC 用的 XPU 部分仍在持续进行,但它不会是 Falcon Shores 最初发布的一部分。
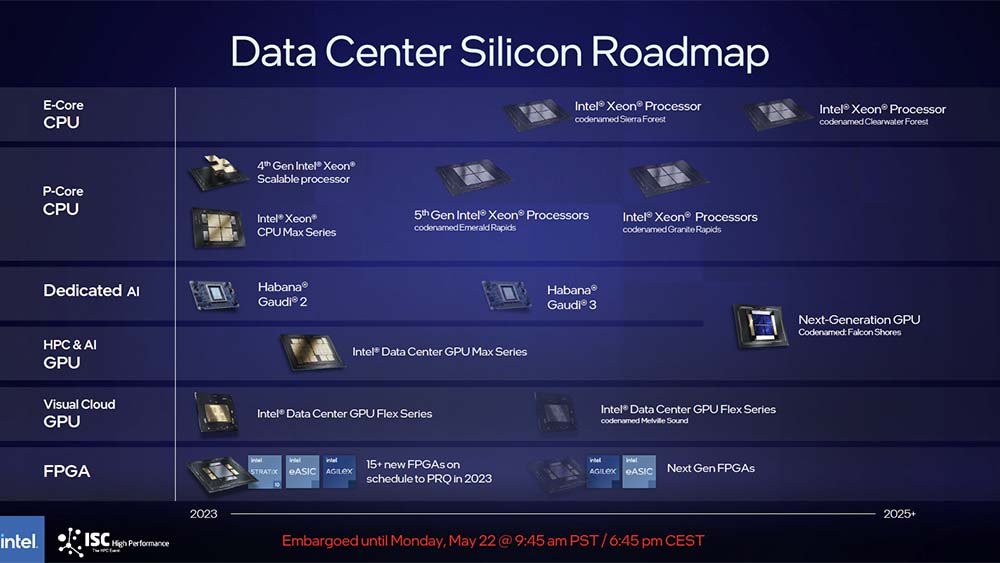
原本用于虚拟、云加速市场的是Arcitic Sond M,按照之前的规划,它们应该在今年被Rialto Bridge和Lancaster Sound系列新品取代。但最新的路线图中,这两款产品的开发被终止了,转而直接开发下一代的产品,也就是Falcon Shores。
另一方面,AI 部分用的 Habana Gaudi 在进入第 3 代以后,将不会有任何更新,而后续也会被 Falcon Shores 替代。英特尔称,他们“计划整合 Habana 和 AXG 产品 (GPU)路线图”,但透露的整合细节很少。
Gaudi 计算架构与标准 GPU 有很大不同,因此其计算架构似乎无法完全集成到 GPU 中。 因此,英特尔可以将Gaudi设计的较小部分(例如其网络接口或其他 IP 块)整合到其 GPU 中。
据悉,AMD的Instinct MI300和英伟达的 Grace Hopper均采用混合式CPU+GPU设计,这种做法的优势是可以降低成本并节省电力,但会将客户产品设计与供应商方案配置高度绑定。
与他们相比,英特尔的纯GPU+灵活搭配CPU方案对于某些工作负载来说很好,但它可能无法在某些应用程序的功率、成本或性能方面与对手竞争。
文章来自:https://www.eet-china.com/







