











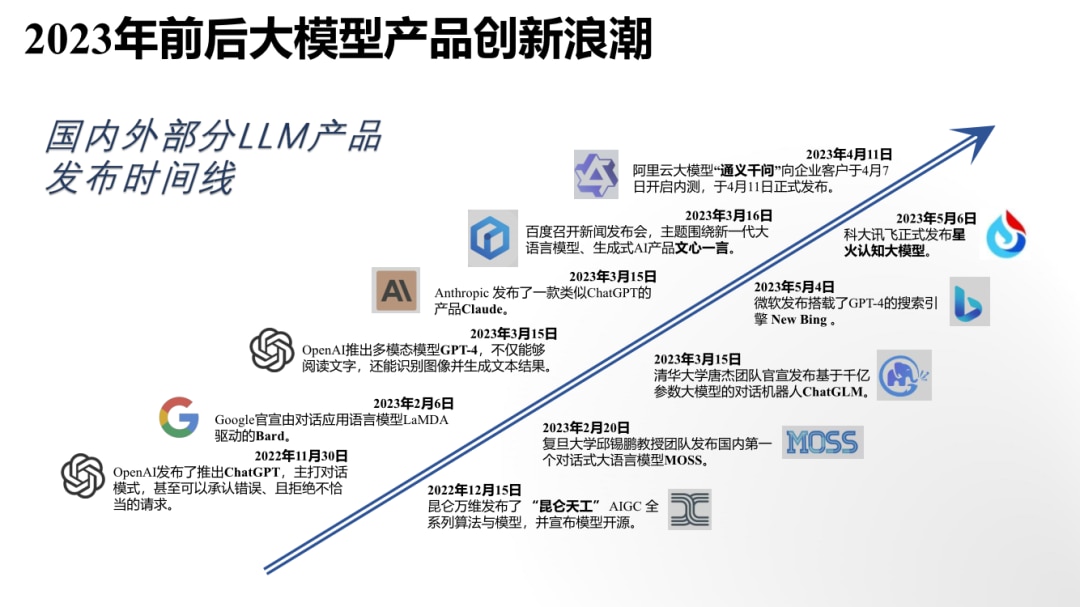
近年,大语言模型以其强大的自然语言处理能力,成为AI领域的一大热点。它们不仅能生成和理解文本,还能进行复杂的分析和推理。近日,清华大学新闻与传播学院发布了《大语言模型综合性能评估报告》。

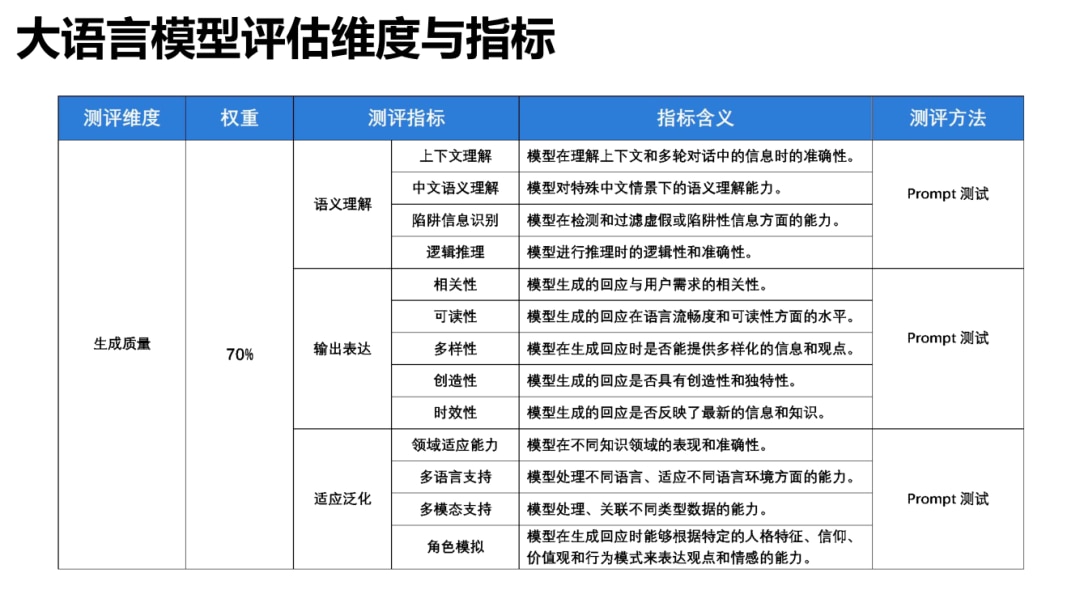
该报告还探讨了这些模型在不同知识领域,如创意写作、代码编程、舆情分析、历史知识等方面的回答情况,以及其在解决实际问题中的有效性和局限性。从生成质量、使用与性能、安全与合规三个维度,对目前市场上的7个大型语言模型进行了全面的综合评估。
根据各大语言模型在各项性能指标上的表现,分析其背后的技术和架构差异,以及这些差异如何影响其综合性能。评估完成后,报告深入分析了不同大语言模型之间的优劣,并提供竞品对比。
通过这一深入的评估和比较,该报告旨在为读者提供关于大语言模型的全面和客观的视角,以帮助他们在选择和应用这些模型时做出更加明智的决策。
大语言模型(LLM)是基于深度学习技术构建的强大语言理解和生成模型,通过大规模文本数据的训练,它能够生成具有语义和语法正确性的连贯文本。基于注意力机制的序列模型,LLM能够捕捉上下文信息,并在各种自然语言处理任务中广泛应用,如对话系统、文本翻译和情感分析。
大模型的显著特点:
1、数据驱动,自主学习
2、类人的表达与推理能力
3、迁移学习的能力
4、跨模态的理解与生成
大模型开发的充要条件:
1、大规模的数据
2、强大的计算能力
3、高效的算法和模型架构
4、高质量的标注和标签
在对大模型的综合性能评估上,该报告主要基于几点考量。
工具选择:评估可帮助用户和企业了解各个模型的优劣,从而选用非常适合其需求和应用场景的工具。
用户体验:评估可以识别生成结果的错误,从而改进用户体验并提供更好的服务。
风险管理:评估可以揭示潜在的风险,如偏见、敏感内容处理不当或隐私泄露等,从而制定相应的策略来减少这些风险。
优化创新:评估可以揭示模型在处理不同任务时的性能差异,提供了改进和创新的方向。
市场竞争:综合性能评估是展示产品竞争优势的方式,也是了解市场需求和竞争格局的途径。
合法合规:评估模型的性能,特别是在内容安全性、隐私保护和版权保护等方面是确保其符合法律和监管要求的关键步骤。
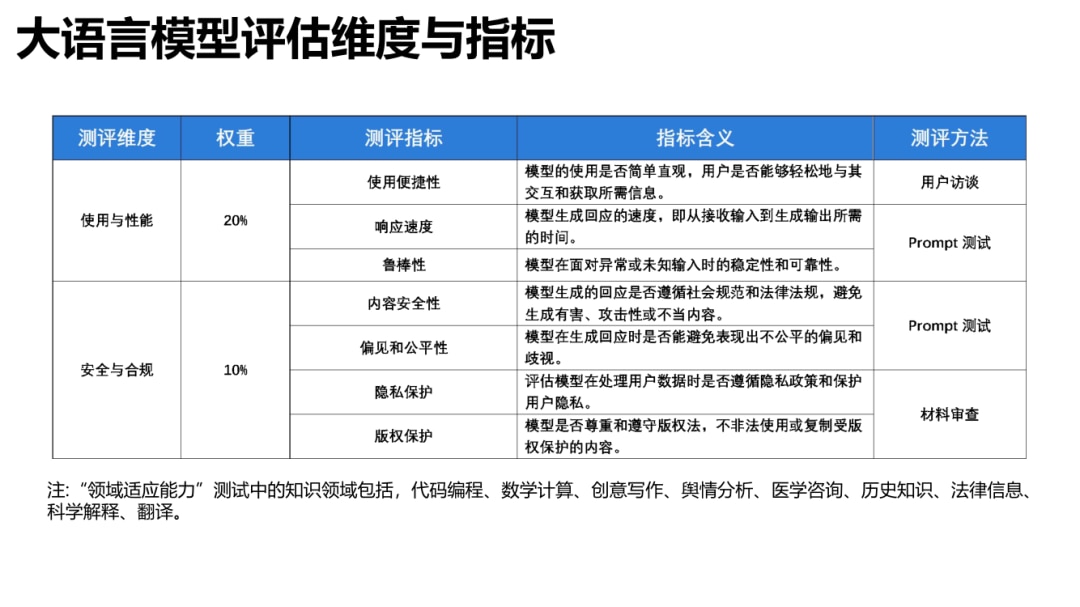
在评估规则上,采用5分制,以“上下文理解”为例:
5分——回答完全理解了上下文,并且高度相关。
4分——回答理解了大部分上下文,但可能略微缺乏深度或完整性。
3分——回答对上下文有基本理解,但可能有遗漏或不够准确的部分
2分——回答在上下文理解上有明显问题,相关性较弱1分:回答几乎没有理解上下文,与之(完全)不相关
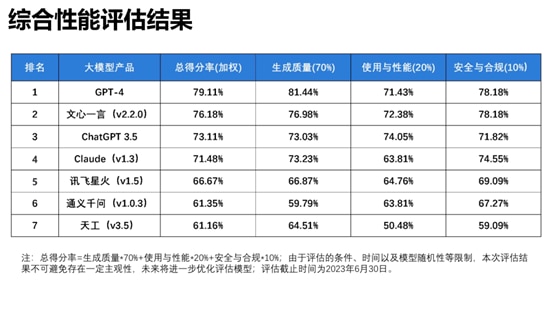
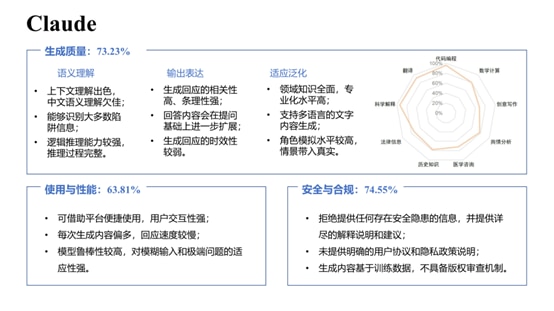
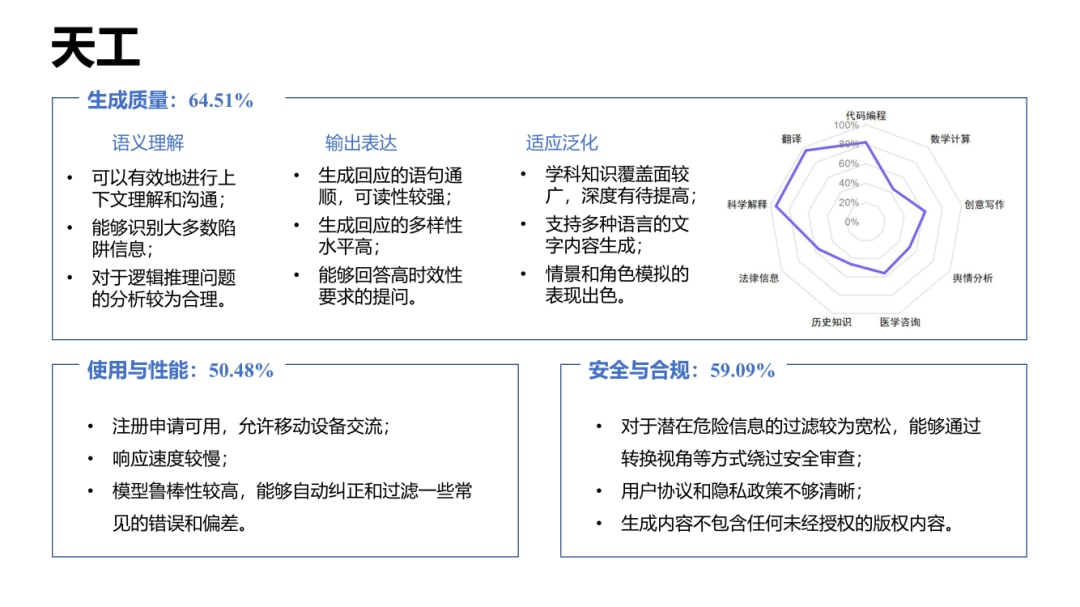
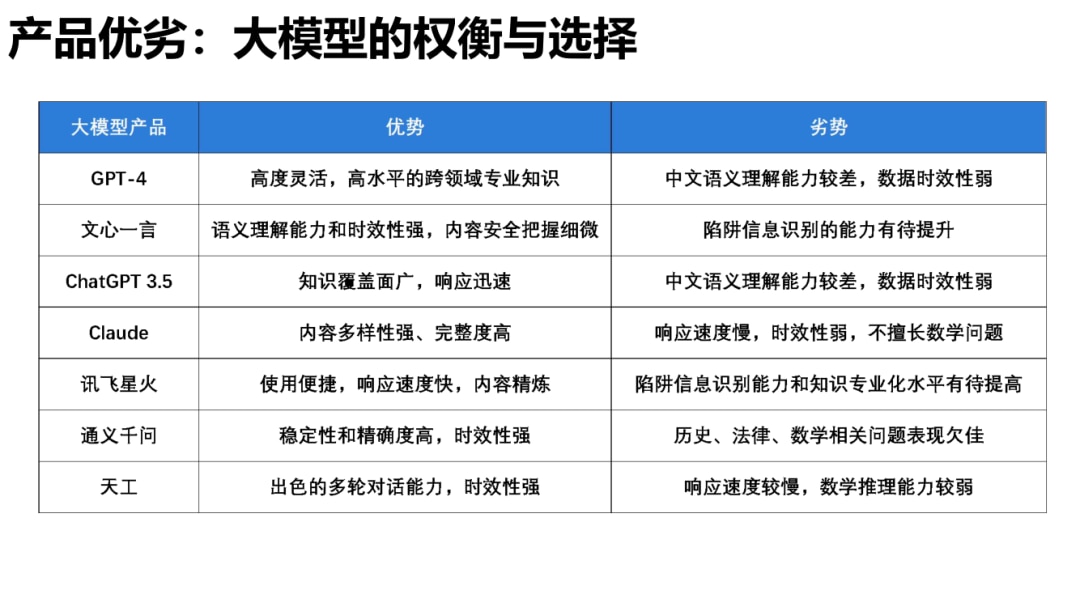
该报告总共对文心一言、讯飞星火、通义千问、昆仑天工、GPT-4、ChatGPT 3.5 和 Claude 七个大语音模型进行了评估分析。据综合性能评估结果显示,GPT-4 排名名列前茅,文心一言和 ChatGPT 3.5 分别排名第二、三位,阿里云通义千问则排在第六位。
综合来看,文心一言语义理解能力突出,特别是具备更好的中文理解能力,更懂中国文化,同时时效性强、内容安全把握细微,这源于其知识增强、检索增强和对话增强的技术创新。
在生成质量方面,基于对语义理解、输出表达、适应泛化的综合评测,文心一言得分率76.98%,仅次于GPT-4,遥遥名列前茅于包括ChatGPT在内的其他大语言模型。
在安全合规方面,基于对内容安全性、偏见和公平性、隐私保护等综合评测,文心一言得分率78.18%,与GPT-4并列排名名列前茅,远超其他大语言模型。报告显示,文心一言内容安全性好,注重用户隐私保护和版权保护。
清华大学新闻与传播学院教授、博士生导师沈阳表示:“今年3月,百度在全球大型科技公司中率先发布了大语言模型文心一言,让中国名列前茅时间参与到世界前沿科技竞争中。我们在这次评测中也看到了文心一言各方面能力的进步,特别是在中文语义理解方面,表现惊艳。国产大模型的快速发展,让技术落地更可期。”





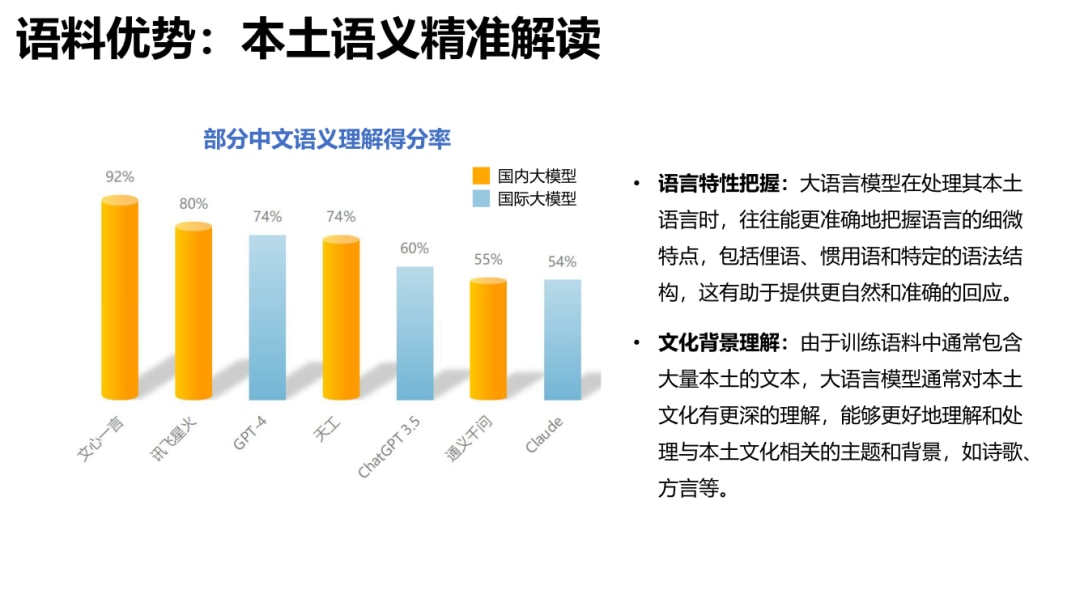
其中,在部分中文语义理解方面,文心一言以92%的得分率排名榜首,超越讯飞星火、GPT-4。凭借知识增强的核心特色,文心一言对本土语言特性把握更精准,同时由于训练语料中包含大量本土文本,对本土文化理解也更深刻,能够更好处理与本土文化相关的主题和背景,如诗歌、方言等,具备更强的国内落地空间。
飞桨与文心协同优化,文心大模型3.5最新版本实现了基础模型升级、精调技术创新、知识点增强、逻辑推理增强等,模型效果提升50%,训练速度提升2倍,推理速度提升30倍。
当下,推进行业大模型应用落地成为大势所趋。百度文心大模型此前已联合国家电网、浦发银行、泰康、吉利等企业单位,合作发布了11个行业大模型。目前文心大模型拥有中国最大的产业应用规模,15万家企业申请接入文心一言测试,在超过400个场景中已取得相当不错的测试效果。

1.强化跨语言迁移学习
发挥本土语料优势的同时,减少模型的语言偏向,提高模型在非母语语言上的理解和生成能力。
2.扩大训练数据的范围
关注互联网大数据,同时采用教科书、文学及其他领域的数据进行补充训练,拓展模型的知识面。
3.加强利用人工数据
帮助模型提高语义理解,生成更人性化的回复。
4.推进敏感和有害信息的精准化过滤
现有过滤机制效果不彰,需要标注更多真实例子,开发更加渐进和语境化的过滤方式。
5.理解社会影响和伦理限制
任何高级AI系统的发展都可能产生深远影响,研究者需要意识到自身的社会责任,考虑如何最大限度地发挥技术优势,同时减少潜在风险。
文章来自:https://www.eet-china.com/







