











今年PC行业的内卷还在持续,尤其AMD和Intel的技术与产品竞争仍处于胶着状态。AMD这边的Zen 4架构表现虽然未如预期,但这家公司的新年产品仍有不少亮点。
月初的CES上,AMD面向个人电脑发布的新款Ryzen 7000系列CPU中,继续包含了采用3D V-Cache的型号,且相比去年多有强化。我们此前特别撰文谈过3D V-Cache技术——简而言之,这是一种增加处理器L3 cache的方案:将L3 cache单独作为一片die(Extended L3 Die,以下简称L3D),以先进封装的方式叠到原本的处理器die上方,大幅增加CPU的cache容量。
其实在去年的IEEE ISSCC上,AMD有进一步详述3D V-Cache技术。这次我们也借着AMD的新品发布,来再度谈谈这项给CPU堆cache的技术。
处理器采用更大的、在垂直方向叠起来的L3 cache,在PC市场上,是AMD于游戏用户的杀手锏——隔壁Intel没有用这项技术。所以3D V-Cache现阶段还真是AMD在市场上差异化竞争的组成部分。不过我们此前也特别撰文提到过,面向个人电脑市场的CPU,堆L3 cache的价值并没有那么大:主要价值都在游戏上,对其他PC应用(比如生产力产经)甚至有负加成。
AMD本身也将这个系列的型号主要定位于游戏用户,但这次发布的新品部分弥补了上代产品的不少短板。

 CES上AMD发布了3款采用3D V-Cache的处理器:Ryzen 9 7950X3D、7900X3D和Ryzen 7 7800X3D。初代采用3D V-Cache的处理器就只有一款;这次AMD显然是在初代试水之后,更看好这项技术了。
CES上AMD发布了3款采用3D V-Cache的处理器:Ryzen 9 7950X3D、7900X3D和Ryzen 7 7800X3D。初代采用3D V-Cache的处理器就只有一款;这次AMD显然是在初代试水之后,更看好这项技术了。
其中较高配的Ryzen 9 7950X3D为16核心。由于3D堆叠能让L3 cache增多64MB,所以7950X3D的L3 cache总容量为128MB。值得一提的是,7950X3D核心睿频达到了5.7GHz,与原本没有堆3D V-Cache的7950X一样;只不过基频相比7950X降低了300MHz。
这一点之所以重要是因为,上代的5800X3D睿频只有4.5GHz——这就让5800X3D,在除游戏之外的其他绝大部分负载中,性能弱于原版5800X。堆叠cache,还是要让核心部分付出代价的。这次睿频没降,也就不至于让更依赖核心峰值性能的负载受到太多不良影响——虽然基频还是略有下降的。
与此同时7950X3D标定的TDP为120W,PPT(Package Power Tracking)162W。这两个标称值还低于原版7950X的170W/230W,可能是因为基频下降、全核睿频相对不带L3D的7950X更低、以及新增cache die容许略高的运行温度。有一点格外值得一提,7950X3D这个处理器16个核心,按照Zen 4架构是分成了两个CCD(Core Complex Die)的——也就是两片die,每片die有8个核心。


只有一片die是叠了L3D的:Lisa Su较早在发布会上展示的3D V-Cache处理器也是只在一片die上叠cache(上图中左上的那片die),另一片仍然是普通的CCD die(右上那片die;下面较大的那片是I/O die)。没有叠cache的CCD die上的核心才能用上较高频率,而叠了3D V-Cache这边的核心做不到全速运转(或这片die的全核睿频更受限制)。所以3D V-Cache依然对堆叠的那片L3D的处理器核心性能产生了少许影响。
基于这一点,AMD目前正在跟微软合作进行Windows优化,AMD芯片组驱动能够识别不同的游戏,选择更倾向于堆叠了L3D的CCD,还是更倾向于没有叠cache的CCD。
另外两个型号7900X3D和7800X3D,分别是12核心+128MB L3 cache,以及8核心+96MB L3 cache。在7800这个型号上,AMD今年只推了带L3D的7800X3D,而没有出不带L3D的版本,所以没法做规格上的直接比较了。
再有就是上代5800X3D是无法对核心做超频的,这代的三颗处理器开始支持自动超频PBO,以及使用Curve Optimizer;只不过仍然无法直接进行超频操作。

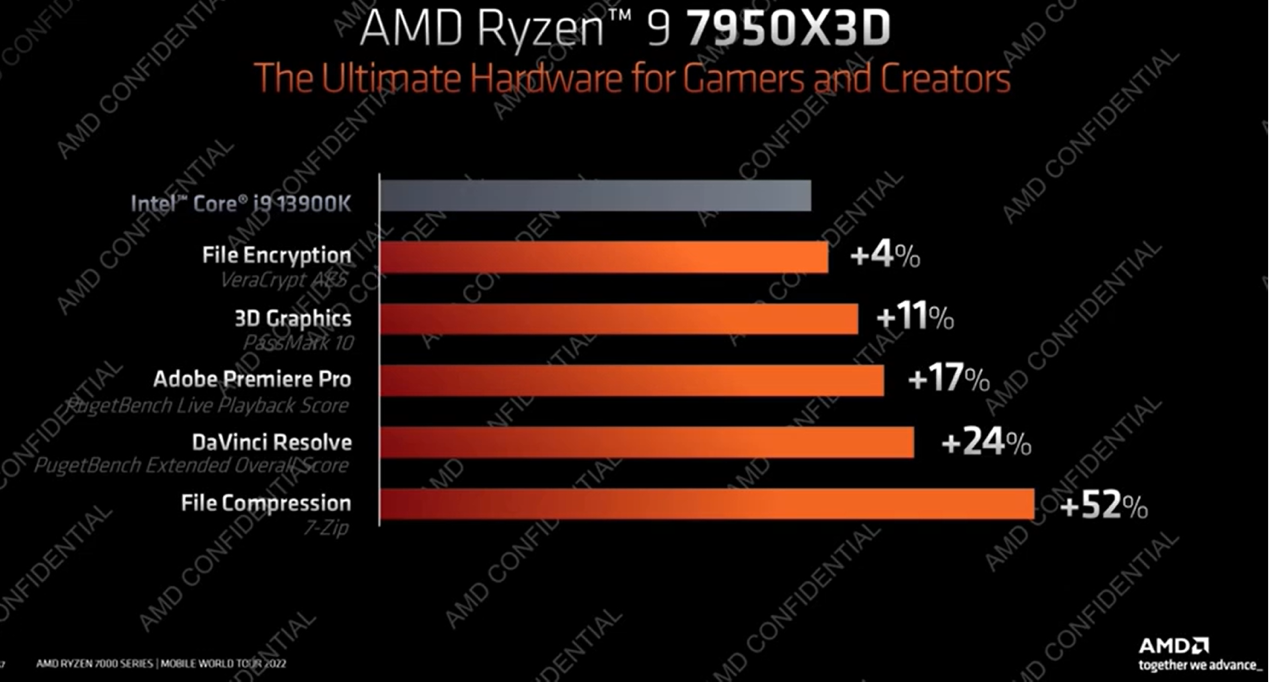
AMD宣称,Ryzen 9 7950X3D相比于Intel酷睿i9-13900K,在游戏中的表现名列前茅13-24%;部分生产力应用名列前茅4-52%。不过从AMD此前给出名列前茅方数据的可信度来说,这个数据还是仅供参考。而从此前5800X3D的游戏表现来看,这代处理器的1080p分辨率游戏表现应该的确会相当不错——非常值得期待。
3D V-Cache技术更大的服务场景应该是面向服务器的Epyc处理器。去年AMD把3D V-Cache应用到了挺多Epyc处理器上,从16-64核处理器都有。8个CCD的Epyc处理器,如果每个都叠上L3D,则处理器总共能堆出768MB的L3 cache——这个数字以前还真是不可想象。
AMD暂时还没有公布这几颗芯片的售价。从去年的情况来看,3D V-Cache版本会比原版贵一些——最终售价对于用户来说,基本就是在更多的核心数和更大的cache容量之间做抉择,看你更愿意为SRAM买单,还是为逻辑电路买单了——这还真得看用户购买CPU的真实用途在哪儿了,因为增大L3 cache容量呈现出了显著的边际递减效应:增加cache命中率带来的那点红利,很多时候无法抵消延迟增加造成的不良影响。
从去年IEEE的技术汇报来看,半导体制造工艺虽然还在进步,但器件微缩主要体现在逻辑电路方向上,SRAM bitcell尺寸的缩减速度急剧放缓,尤其从台积电N5到N3工艺,SRAM单元面积微缩幅度是5%。而且很快要大规模量产的N3E工艺,SRAM单元面积还要增大。这其实是技术发展过程中的桎梏。
3D V-Cache是符合这样的时代发展主旋律的,也就是把SRAM往垂直方向去堆。而且这也增加了产品SKU的灵活性,毕竟很多应用场景其实并不需要那么大的cache。AMD表示,在没有增加横向datapath距离的情况下就增加cache容量,保持动态低功耗和低延迟的同时,也缩减了封装尺寸——节约的尺寸可以用来做其他事,比如说增加更多的核心。

3D V-Cache处理器总体包含三个组成部分,CCD(上图最下层)、L3D(上层中间部分)和结构支持die(两侧的die)。对AMD Zen架构处理器有了解的同学应该很清楚CCD是什么——现在的架构中,大体上8个核心构成一个CCD(如下图),当然CCD内部本身也是有L3 cache的。比如说原版Ryzen 9 7950X,两片CCD总共配有64MB L3 cache。
不过AMD在ISSCC上说,往CCD上面堆L3D并不是临时起意。对于3D V-Cache的支持,无论是架构上还是物理电路上,都是从此前Zen 3处理器设计之初就做好了准备的。也就是说从最初设计CCD、还没有向市场推出3D V-Cache版本的处理器之时,CCD上面就预留了必要的逻辑电路以及TSV(硅通孔)信号pad。这就极大地节省了NRE成本、减少了掩膜组数量,简化了整体的chiplet设计。
换句话说,Zen 3架构的CCD原生就支持L3D扩展,包括TSV柱。AMD表示这种预留会对面积造成大约4%的影响——也就是需要额外4%的面积。
往上叠加的L3D这片die,制造工艺和CCD是一样的。Wikichip在分析文章中提到,L3D内部有13层铜层,和1层铝层。L3D的确就是纯粹的cache die。在Zen 3架构那一代(即Ryzen 5000系列,台积电N7工艺),L3D总共64MB SRAM,面积41mm²。
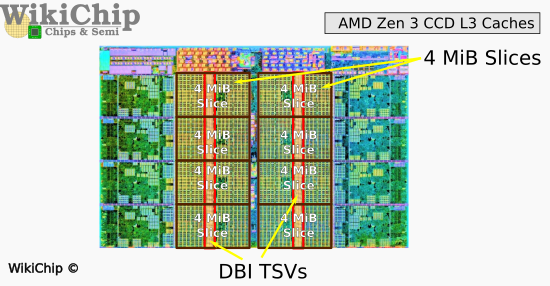
来源:Wikichip
L3D叠在上层,刚好覆盖差不多一半的CCD;L3D仅位于CCD部分的L2/L3 cache区域上方——因为cache区域的功率密度相对更低,则 3D堆叠产生的散热影响会相对更小一些。CCD上面的L3 cache设计为16-way set associative;总共8个切片,每片4MB。L3D也是这种设定。
所以L3D也是8个切片,每片包含8MB数据,和816KB的tags/LRU。上一代的5800X3D因此就有了总共96MB L3 cache。AMD提供的数据是,新增堆叠的L3 cache,只会有增多4个周期的延迟。
除了CCD和叠在上面的L3D之外,还有做结构支持的die——在L3D旁边,也就是相对的位于下层CCD的处理器核心区域上方。这是一种物理结构上的辅助设计,主要是在键合(bonding)过程中;与此同时也作为CPU die的散热通道:结构支持die需要在Z轴达成高度的匹配,毕竟最终封装的散热顶盖也需要与die做到充分接触。
AMD说L3D的设计是往高密度、低功耗的方向走的。实际在Zen 2走向Zen 3架构的时候,AMD就为处理器选择了高密度SRAM bitcell(而非高电流单元)。如此一来,每个核心分配到的L3 cache切片容量就更大,同时保持die面积可控。L3D则用了高密度的8T SRAM bitcell,有功耗方面的红利。其他缩减功耗的特性还包括用更高Vt的器件、floating bitline,以及一些电源门控技术。
Zen 2到Zen 3架构变化过程中,每个CCX(core complex)的核心数翻番到8个,则核间通讯架构就需要重做。Zen 2时代,CCX内部的核心数还没有这么多,所以采用crossbar型核间通讯。到了Zen 3,Wikichip在剖析文章里提到,由于核心数增多,所以核间通讯改用ring bus双向环形总线。Zen 3每个CCD的L3 cache是32MB(不加L3D的情况下),分成8个切片(每核心4MB),也就是8 s较好s。
在新增L3D以后,每核心可分配到的L3 cache增大至12MB,仍然是双向环形总线(64MB L3D,每个切片8MB——加上原本CCD上每个切片4MB,也就是每个s较好 12MB)。
有关供电的详情,由于篇幅原因不做赘述。有兴趣的读者可以去看一看Wikichip的分析。简单来说,CCD有三种主要供电轨,RVdd——用于L3 cache logic;Vdd是为核心供电的;VddM针对L2和L3数据bitcell做门控供电。

这里再谈一下Hybrid Bonding混合键合。3D V-Cache的3D堆叠采用的是Hybrid Bonding方案,此前初代产品在做宣传的时候,很多同学就应该已经知道了。这在高性能处理器上应该是Hybrid Bonding的为数不多的应用。这种混合键合能够把两片wafer或者两片die键合到一起,而且是直接的铜到铜——电介质到电介质的互联,而不用microbump。
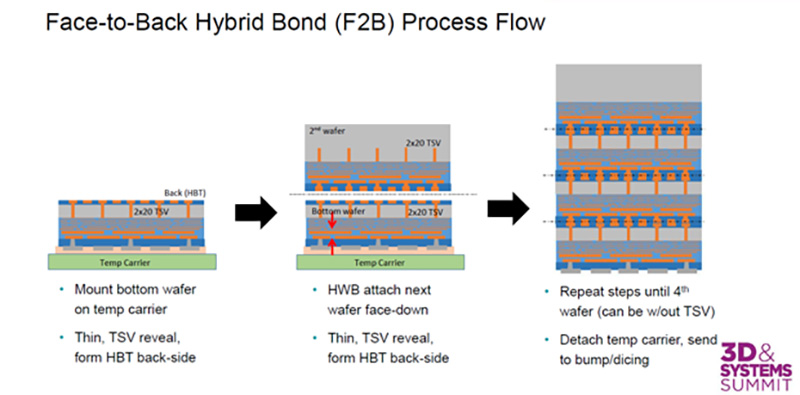
来源:GlobalFoundries
具体到台积电的技术,用的SoIC工艺的F2B(face-to-back)键合。封装时,CCD本身面朝下,以C4介面面向substrate;CCD的背面通过薄化(thinned down)露出TSV;然后L3D die同样面朝下,混合键合到CCD上;最后把结构支持die键合上去。就微观层面来看,L3D的M13金属层通过BPV(Bond Pad Via)连接到BPM(Bond Pad Metal)上。
AMD说,3D V-Cache应用的SoIC封装能够做到最小9μm的TSV间距。这种较小的间距,本来也就是Hybrid Bonding的优势所在,此前电子工程专辑谈先进封装工艺的文章详细阐述过。不过TechInsights的逆向工程显示,Zen 3架构的这代产品TSV间距是17μm。理论上最新发布且采用了新制造工艺的Ryzen 7000系列3D V-Cache新品应该进一步让这个间距下降了。
Hybrid Bonding本身包括低电阻之类的优势就不多谈了,毕竟也还算知名;显著更小的互联间距才是其相比其他方案的真正优势。
最后值得一说的是,台积电的F2B SoIC这套方案是完全可重复操作的。也就是说L3D本身的背面可以再做一次这样的键合。那么理论上就能再往上堆L3D了。而且Wikichip认为,操作上所需的改动并不大——只不过需要供电方面的一些调整,供电到叠层上方,以及一些Die-to-Die信号的额外逻辑电路。
还是那句话,虽说就个人电脑来说,再增大L3 cache对于绝大部分非游戏类应用而言并没有太大价值,甚至产生副作用;但当应用方向明确为存储敏感型的,那么大cache就会非常有价值。
想必新发布的三款采用了3D V-Cache的处理器,能够在新一年的游戏应用上大杀四方了。等产品发布时,可以看看它们与酷睿i9-13900K的对比结果,毕竟这代酷睿处理器也大幅增加了cache容量,而且核心数和频率都提高了。而且在游戏设定更高分辨率时,3D V-Cache的优势可能逐渐消失。当然对Epyc客户而言,关注点可能又不同了。
文章来自:https://www.eet-china.com/







