











对Intel显卡来说,现在最欠缺的是什么呢?无论是Arc图形卡、Flex数据中心加速卡,还是Ponte Vecchio这种绝对HPC方向的GPU,关键肯定都在软件上。说显卡,无非图形卡和HPC/AI加速两个方向。
就GPU硬件,Intel的这一代产品布局已经是相对完备的了。现在要做的,一是图形卡驱动持续更新,提升视觉、图形类应用的性能和效率——这也是过去一年,我们在持续跟进的。今年5月底,Intel召开媒体会时说自Arc显卡发布以来,其驱动更新已经达到21个版本,DirectX 9老游戏效率大幅提升。
二是在生成式AI大背景下,要求GPU有能力、且面向开发者更方便地对大模型做training和inference的加速,这需要软件框架、各种库、中间件之类的工作跟进。今年Computex期间,Intel特别宣传了轻薄本的AI能力;同期的媒体会上,Intel也展示了用Arc A770加速,藉由OpenVINO插件在GIMP中跑Stable Diffusion——不过当时我们说过,这个演示看起来还相对初级。

针对这两个方向,Intel在时隔2个月后,趁着邀约参观英特尔大湾区科技创新中心的空,又更新了一波显卡相关的生态进度。比如说Arc显卡驱动更新了30个版本,以及重构DirectX 11驱动,提升DirectX 11老游戏的性能和效率;
AI方面,则就端侧做了更复杂的演示,包括ChatGLM-6B、Llama 2-13b等模型在酷睿轻薄本上的推理——当然未必是Arc GPU相关的——因为这一个月,我们听到不少Intel就其CPU做高效AI推理的宣传,但GPU部分据说相比2个月前演示的性能也已经得到大幅提高——看得出来Intel在这个方向上正牟足劲往前冲。
其实在最近刚刚结束的Intel中国学术峰会上,Intel就生成式AI相关的技术,及其生态构建做了相当详实的内容分享,包括HPC AI训练方向,毕竟这是现在的大热门——很快我们会对这部分内容做单独介绍。本文就AI相关的更新,主要就谈谈客户端侧的生成式AI推理演示,这应该也是最贴近普通用户的部分。

值得一提的是,这次Intel也在分享会上特别展示了上图这张专用于边缘侧,确保7×24小时工作可靠性(应该主要是指供电设计,及板卡上的分立器件稳定、寿命与可靠性),和蓝戟合作采用涡轮风扇方案的显卡——芯片和存储具体为A770 16GB;目前无更多信息,包括TDP多少。Intel表示这张卡会在9月初量产,猜测强调的主要是有高可靠性和高强度需求的边缘侧AI推理应用场景。
先来谈谈图形渲染相关的性能提升。其实在Arc显卡今年Q1’23版本驱动更新过后,我们就已经没怎么预期Arc显卡还能通过驱动更新,换来多少游戏性能的飞跃了。Q1’23驱动更新,主要是让老游戏,尤其是DirectX 9老游戏,性能得到大幅提升——当时我们在体验过后,是说更新驱动,基本等于买了张新显卡。
当时Intel主要是对DirectX 9相关的驱动部分做重构——因为Intel较早发布的驱动,对于DirectX 9老游戏,是基于D3D9On12中间转换层来实现向前兼容的。所以在重构DirectX 9驱动后,某些DirectX 9老游戏甚至能获得将近成倍的性能提升——Intel的数字是Q1’23 Arc Update驱动更新,相比较早版本驱动,DirectX 9老游戏平均性能提升43%。
这次就轮到DirectX 11了。其实从我们的测试来看,Q1驱动更新也对DirectX 11游戏有性能加成,只不过没有DirectX 9那么明显。而这次驱动更新(名为Q3’23 Update,版本号≥31.0.101.4571)过后,Intel名列前茅方数据显示DirectX 11游戏性能平均提升19%。Intel给出了11款游戏的平均帧率实测结果如下:
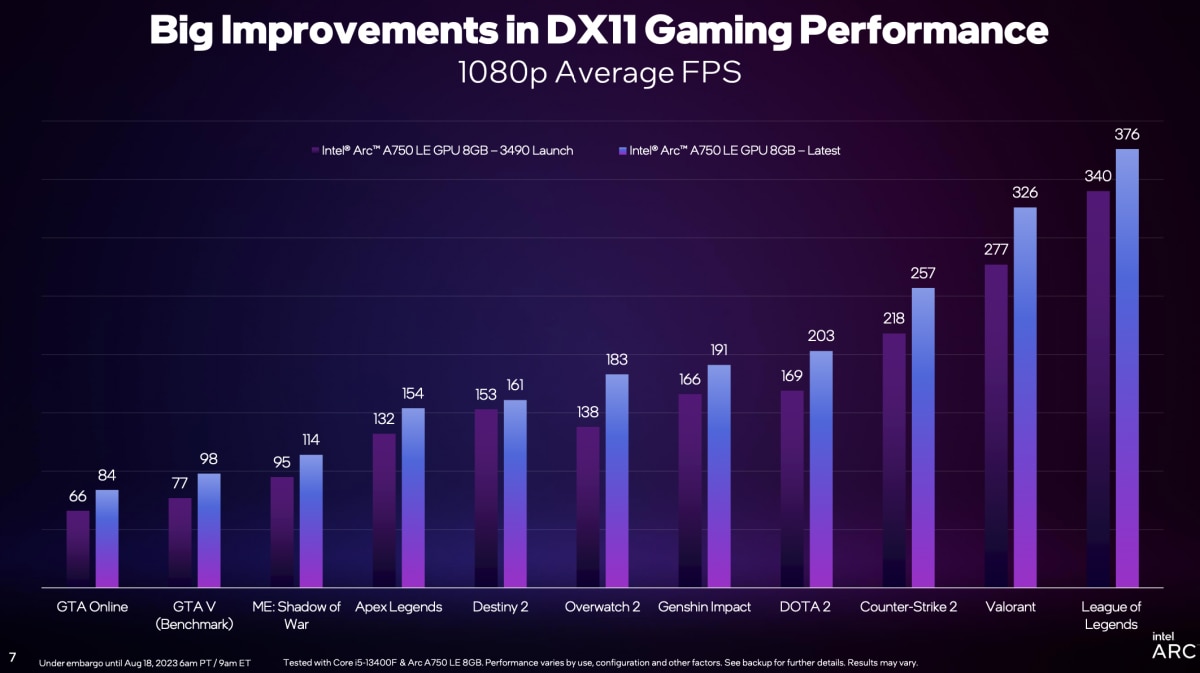
这个对比是基于Arc A750 LE 8GB测得的,相比最初版驱动,更新Q3’23驱动后不同游戏性能提升幅度在5%-33%之间。包括《英雄联盟》(DirectX 11)在新驱动下,平均帧率提升11%;《原神》平均帧提升15%;《CS2》帧率提升18%;《DOTA2》帧率提升20%;《守望先锋2》帧率提升33%等…
1% low帧(99th Percentile)情况也类似,不同游戏这一数值的提升幅度在9%-45%之间,具体如下图。综合不同测试,得到1% low帧提升幅度也有20%。这个数值对实际游戏的流畅度体验是很有价值的。
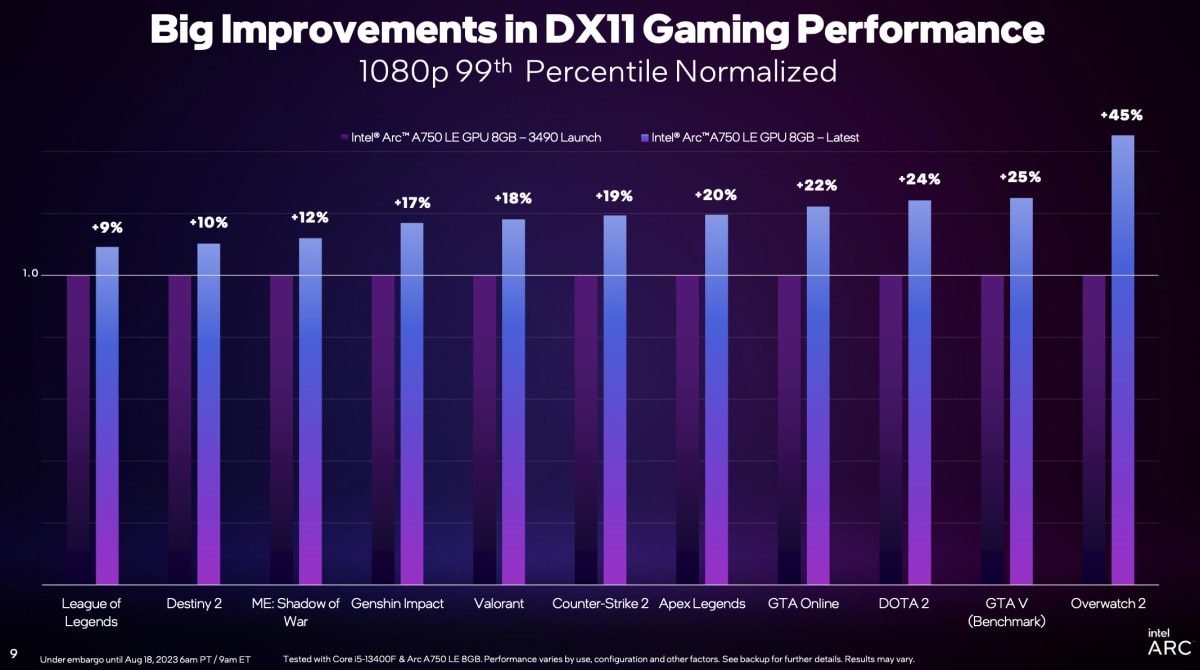
Intel说之所以选择在DirectX 11 API部分下功夫,主要是因为DirectX 11仍然有着广泛的游戏和玩家基础,像《GTA:Online(侠盗猎车手)》《DOTA2》《守望先锋2》之类的游戏有着庞大的用户基数。
但需要注意的是,看上面这组数字对比选择的CPU型号为酷睿i5-13400F。如果把CPU换成更高端的酷睿i9-13900K的话,则这些游戏的平均帧和1% low帧提升幅度会小有下降,具体如下图:
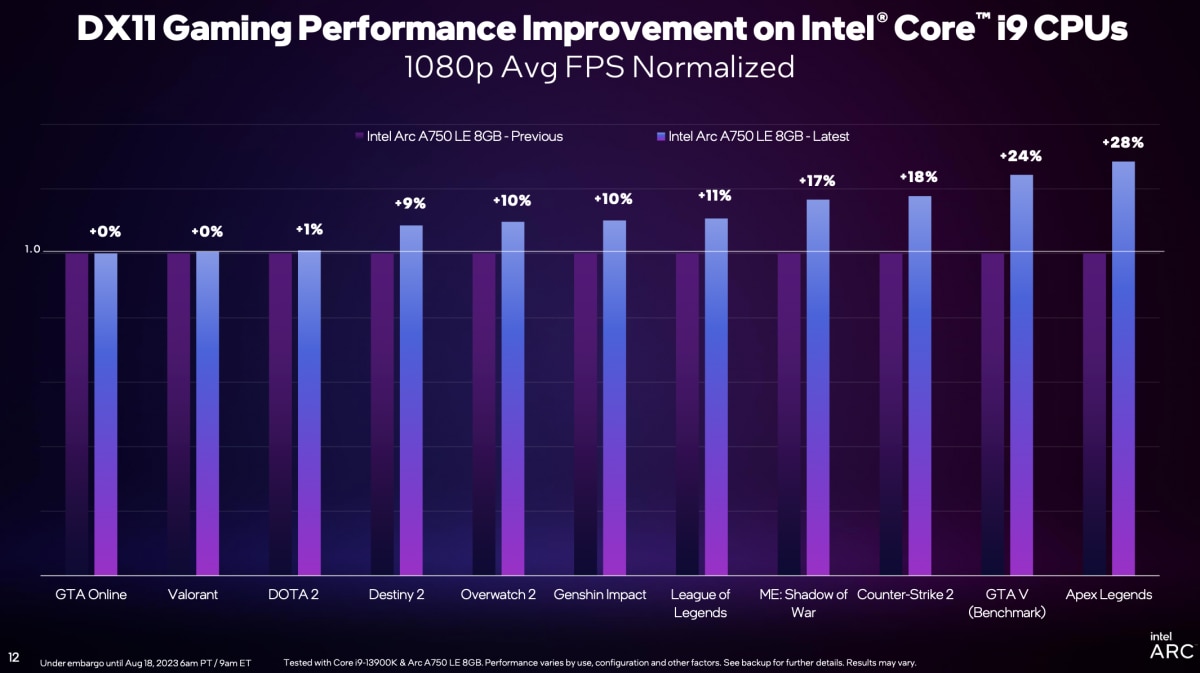
从平均帧的角度来说,酷睿i5-13400F搭配Arc A750,新旧驱动的DirectX 11游戏性能提升平均19%;而酷睿i9-13900K搭配Arc A750,这个数值则在12%左右。也就是说Q3的新版Arc GPU驱动,对定位更低的CPU平台会带来更显著的性能提升。
有关这个问题,Intel给出了更详细的解释,引入了“GPU Busy”的概念。在谈GPU Busy之前多说一句,Intel在QA环节解释说,DirectX 11驱动改进方向,和此前重构DirectX 9驱动思路“类似”,“但不完全一样”,“也是重构了DirectX 11应用层面的驱动——应用层面驱动是驱动的一部分,但并非全部”。
可能后续Intel就Arc驱动改进的技术细节,还会给出更多信息。
关注游戏和图形技术的同学,应该知道“frametime”帧生成时间这个概念。处理器花在每一帧上的时间越短,自然就越好。要明确frametime的概念,需要对游戏过程中CPU、GPU的工作方式有个了解。下面这张图给出了简化的游戏过程中,CPU和GPU的工作逻辑。
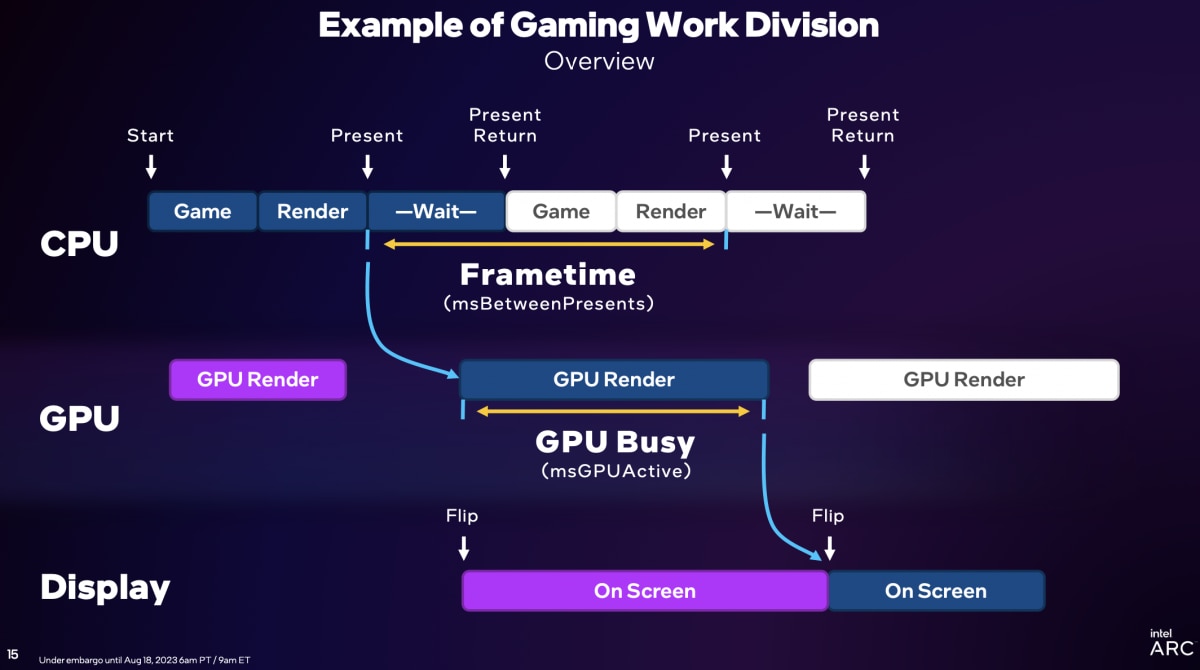
“CPU首先处理游戏的逻辑部分,包括物理计算、命中检测,将目标移动到新的位置,可能还会绘制新的几何图形等——这些都构成了逻辑部分,可能还要监测鼠标、键盘。”Intel在解释这条流程链条时说,“接下来进入CPU render部分,这部分主要是把游戏状态传递给渲染器,渲染器再将其转为标准的DirectX命令(调用)。”
“为数不多的present出来,这个命令会继续往下走。CPU就开始等待(wait),等待present返回;随后“下一个逻辑部分、下一个present”再次进入这个流程。
在“名列前茅个present出去之后(标准的DirectX命令,draw call),就交给驱动——驱动需要做很多工作,比如内存管理、数据获取等等工作,包括着色器编译——驱动将其转成GPU听得懂的语言,通过命令缓冲区,传递给GPU”,“GPU就做渲染”(GPU render)——这部分很多同学应该就比较熟悉了,最终通过frame buffer做显示输出。
这个过程里,将一帧present,到下一帧present的时间间隔称为frametime(而不是present返回,到下一个present出现)。各类游戏资源监测工具应该都是这样计算frametime的。
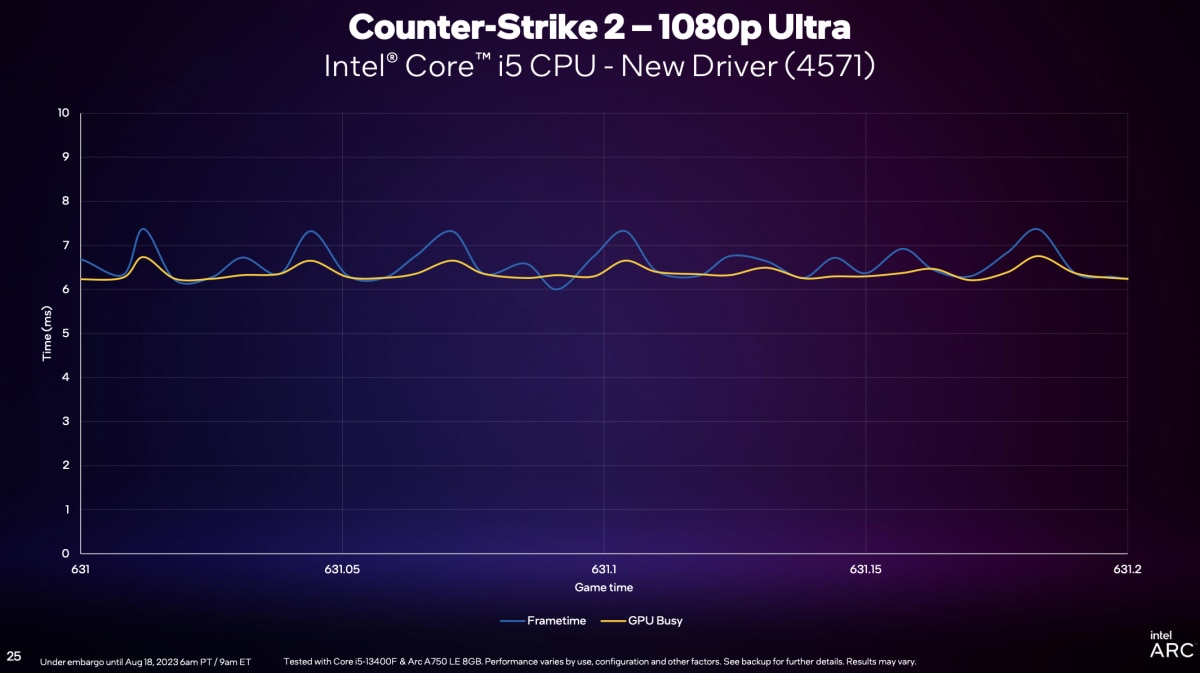
这个过程里,”GPU做渲染的时间,原则上应该和frametime差不多,这样GPU才算是发挥得比较好。如果frametime远远大过GPU render的时间(定义为GPU Busy),就表明负载瓶颈在CPU上。”下面这张图给出了初版驱动(3490)下,《守望先锋2》游戏过程中(1080p Ultra画质),不同时间点frametime和GPU Busy的差异。
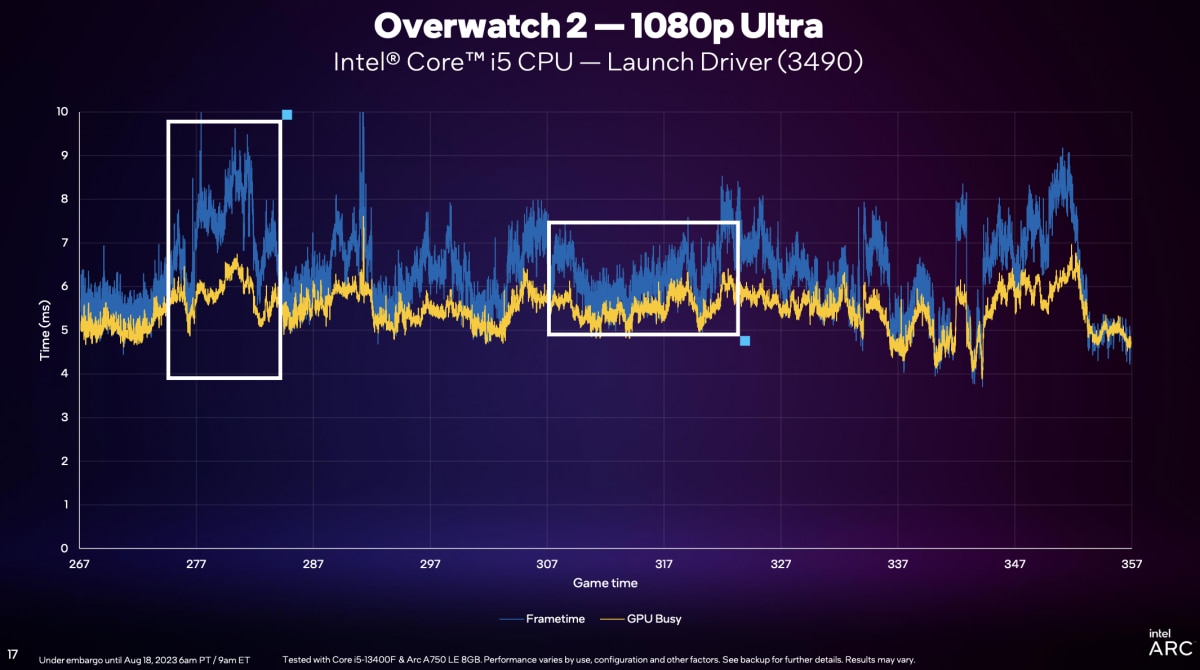
图中左侧框出的部分能明确看到,两个值的较大差异,表明了“CPU受限”,”wait这块,和GPU Busy中间太久”。“关键是转成DirectX命令、交给驱动,CPU到底在等什么?”“其实驱动要处理的工作很多,包括和DirectX做交接——对此做优化,是我们工作的重点。驱动要在合理的时间内接管DirectX,更快地去做响应。”
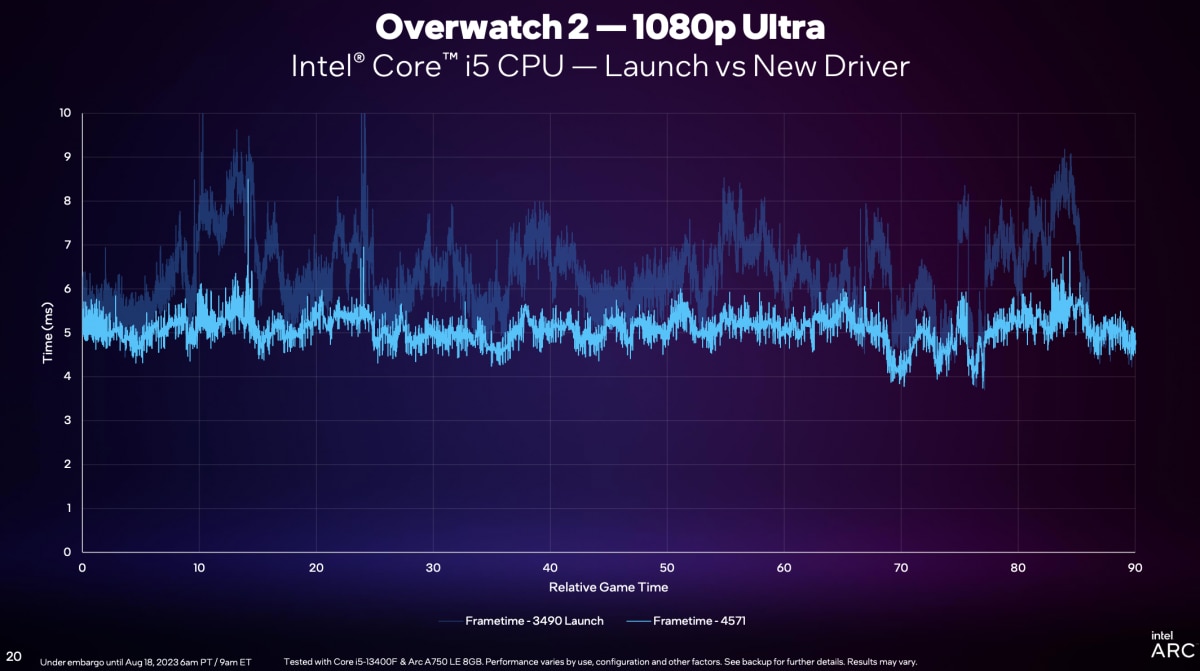
“我们的新版驱动,和最初的驱动有很大不同。不仅去掉了毛刺,frametime也从先前的6-10ms,变为5-6ms,这个进步是巨大的。”下面这张图新旧驱动的对比,已经体现了这种变化——仍然是《守望先锋2》游戏过程里的frametime变化。“但这还是不够的,还需要看GPU Busy。”
所以新版驱动在这部分努力过后,搭配酷睿i5-13400F + Arc A750,这款游戏中的frametime和GPU Busy这两个值重合度就显得很高(如下图);很大程度解决了CPU受限的问题。
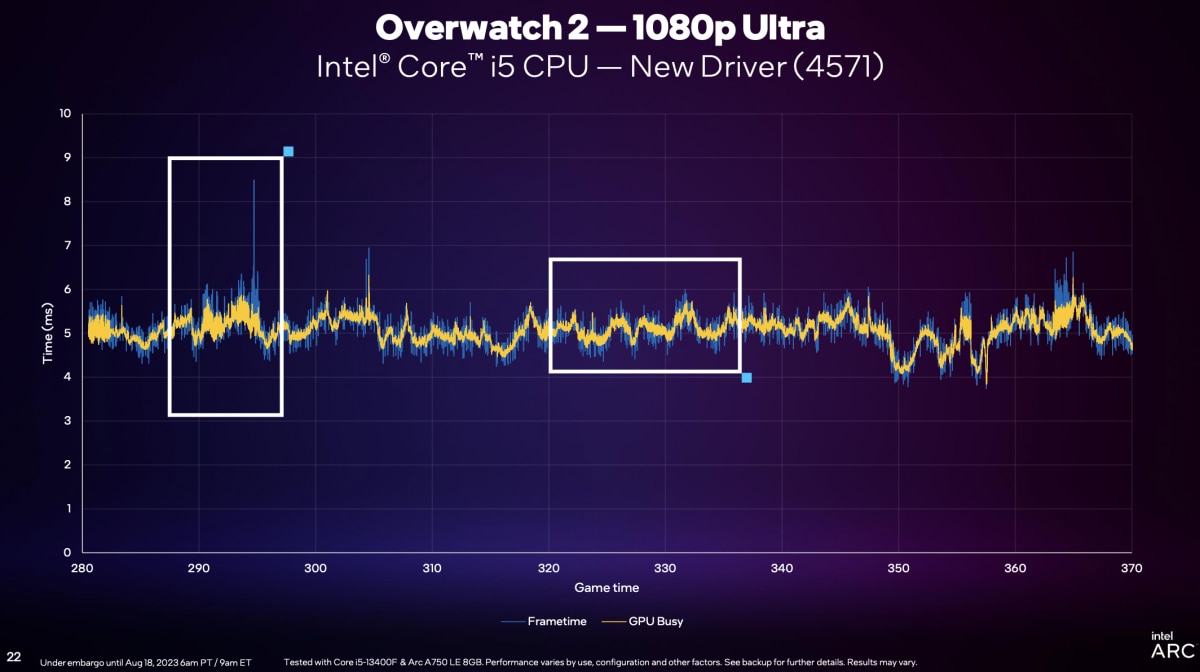
“CPU和GPU平衡,或者说未来GPU还会有发挥空间。”所谓的“GPU还有发挥空间”是指GPU Busy这部分的时间还可以缩短,“这是另一个话题了,下个季度我们还会对这块做更详细的解释。”
就CPU侧具体如何减少“wait”时间,达成frametime的缩短,Intel方面强调,“在DirectX命令转换之后,驱动要做一些事情。驱动具体何时介入,这里面有很多事情要做。”“这个过程很复杂”;
另外上面的图“只展示了游戏主线程,还有很多辅助线程没有展示”,“很多辅助线程把DirectX 11的draw call编译为GPU认识的指令——这个编译过程,也包括数据传输过程,以前这个环节的优化度不够。这次优化,是将辅助线程的效率做了大幅提升。“
“过去DirectX 9游戏性能大幅提升,和(这次)DirectX 11性能大幅提升,我们攻坚的核心困难点就是CPU受限。其实Arc GPU渲染能力,render time是很快的——3DMark能够反映基本渲染能力。”“过去8个月,我们将CPU侧等待效率提升了N多倍,这也解释了为什么酷睿i5处理器上看起来收益最大。”
Intel自己公布了新驱动下,《CS2》游戏在选择1080p Low和1080p Ultra两档画质下,frametime和GPU Busy的差异。很明显1080p Low画质下是更加CPU受限的——这符合直觉,因为低画质下GPU的工作会相对少一些——而且其实两者的frametime峰值相差并不算大。不过实际上,我们认为这个问题可能会更加复杂。
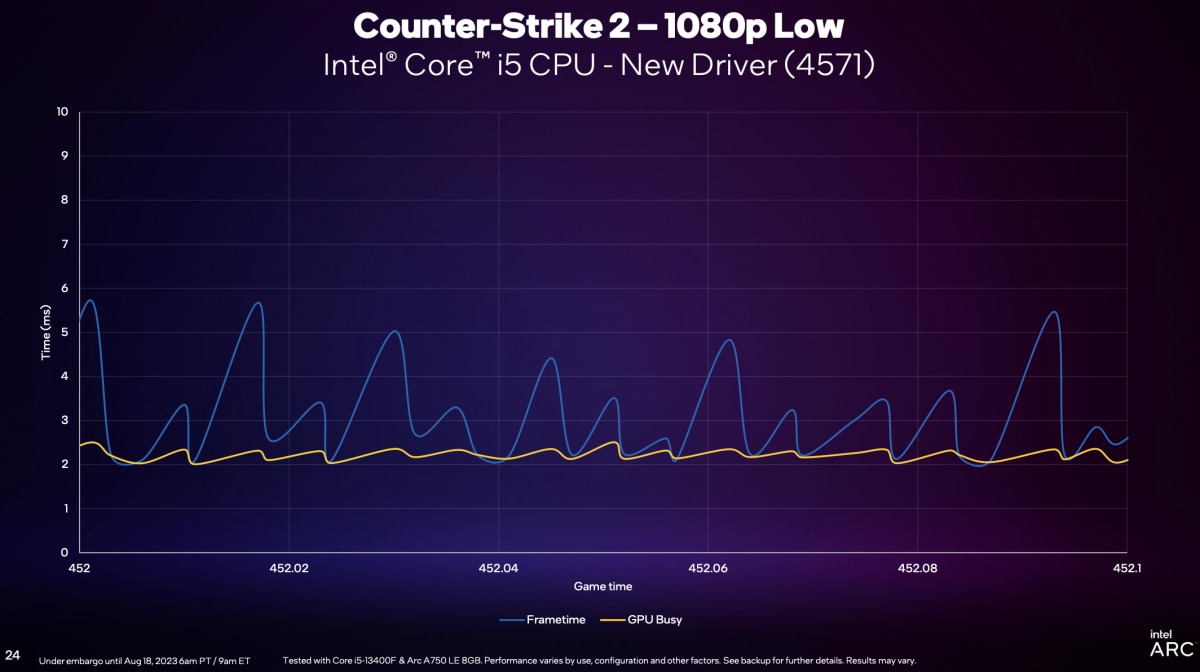
以上是Intel方面给出的有关“GPU Busy”概念的科普,未来我们或可做进一步深入研究。
大概是为了推广GPU Busy的全民理解吧,这次Intel还特别更新了PresentMon Beta版监测工具。这个工具似乎前两年就存在于Github上了。最新的beta版就有实时显示GPU Busy数值的特性——关键它还支持N和A家的卡,对DirectX 9/11/Vulkan等等主流API都提供支持。有兴趣的同学可以去下载试试。PresentMon引入GPU Busy的一大价值,应该在于让玩家了解,针对特定游戏,如何搭配CPU和GPU可达到更高效。
图形部分讲完,就该谈谈GPU的另一个职能AI了——不过不是XeSS这样的AI超分,而是生成式AI(或称AIGC)。这部分的技术相关内容,Intel在这场媒体会上,仍然没有多做介绍。
不过Intel主要给了生成式AI的现场演示:其一是跑Stable Diffusion,其二是ChatGLM-6b和现在很火的Llama 2-13b(最近采访国内AI芯片公司,各个都说Llama 2前途无量)…真正HPC相关的training部分肯定不会放到这类活动现场来说。其实Intel就AI的野心,和英伟达一样,也是端到端全栈覆盖的pipeline;而客户端业务——主要以PC为主,显然是其倡导“AI everywhere”的一部分。
就后者,也就是LLM的推理部分,Intel自然是要谈其主导的开源项目BigDL的——这东西的一大职能应该就是简化在端侧PC上的LLM推理。“通过BigDL-LLM库,我们可以对跑在本地的各种LLM做优化和支持。”现在Intel一直在宣传的,用轻薄本跑生成式AI,就有其功劳。

恰好近期Intel中国学术峰会上,英特尔院士、大数据技术全球CTO戴金权就在主题演讲中详细介绍了BigDL-LLM,提到“任何Hugging Face transformers模型”支持,包括Llama、ChatGLM、MOSS、StarCoder等,“通过BigDL库,对大语言模型做量化,减轻本地硬件资源需求”。
这次媒体会上演示的,其一是ChatGLM2-6b的中文对话——跑在一台采用酷睿i7-13700H处理器,仅有Xe核显的轻薄本上。从演示来看,6b规模的推理响应速度相当快——现场看到first latency——也就是为数不多的token生成时间342.22ms,after latency——平均token生成速率71.1ms/token。
参数规模扩大一倍,英文对话基于Llama 2-13b模型做文字生成,会看到明显更加复杂的回答,但生成速度也仍然很快,至少是不影响阅读体验的程度。
另外不可或缺的肯定还有跑文生图的Stable Diffusion,仍然是用OpenVINO加速——演示中当然也特别提到OpenVINO对开发者很友好,“安装方便,一行代码解决”,“应用OpenVINO,加速PyTorch模型,只新增一行代码”。跑的具体是Stable Diffusion Automatic1111。
Intel演示的推理关键词为“a tall stack of pancakes, cropped food photography”,生成512×512分辨率的图片。做推理的设备,一台就是酷睿i7-13700H轻薄本(不带独显),这里应该就明确用到了Xe核显加速。生成过程大约17秒。
改用Arc A770独显加速,这一例达成速率约9.65it/s(每秒迭代数),生成一张图片大约2秒多。另外Intel也演示了图生图(image-to-image),基于小木屋的图片,Arc A750以8.9it/s的速度在2秒多的时间里再绘制了一幅小木屋的图片。
光这么说,其实还是比较枯燥和无力——有条件的同学可以自己去尝试一下,毕竟就是一台轻薄本的事。Intel补充说“目前Arc GPU在所有GPU产品中的表现都是很耀眼的”,比2个多月前演示时进步了很多。据说Arc A770的生成式AI性能,已经达到RTX 3080 8GB到3080 12GB之间的性能水平——这个说法还是很模糊。大概是说上述这几个典型优化过的生成式AI场景。
其实戴金权在主题演讲里还给出了StarCoder-15.5b规模的LLM推理demo,也就是说Intel轻薄本目前在BigDL-LLM的加持下,是能够做到较高160亿参数大模型的本地推理支持的。
以低门槛跑规模并不是那么大的生成式AI,在诸多领域应该都有相当大的意义。当然这件事对Intel扩张AI生态应该也非常重要。当时戴金权在会上说:“把AI大模型搬到轻薄本上,或者其他客户端、设备端的场景,我们还能做些什么?我觉得这是非常重要、可以探索的方向。”
其实在其他AI方向的应用上,前不久Intel NEX(Network and Edge Group)业务在2023英特尔网络与边缘产业高层论坛上,展示边缘侧不同行业的应用场景(顺带一说,这次我们参观的英特尔大湾区科技创新中心有个专门的展示区,其中大部分demo都和NEX产业高层论坛上的展示几乎一样,有兴趣的可以移步看一看Intel处理器在边缘端的应用)。
其中有几个例子当时就给我们留下了很深刻的印象。比如说开域展示的数字门店方案,AI Box里面只配了12代酷睿i5处理器,没有其他加速器的情况下,基于CV来进行门店管理,包括员工有没有穿制服、戴口罩,面包店的货架铺满率检测,餐厅餐桌是否清理的检测等。这样的例子还是能够说明,Intel在中间层和底层软件部分,AI方向上的努力的。
这次媒体会上,Intel又展示了Arc A770加速的人物动作3D数字重建应用:通过常规摄像头进行人物动作捕捉,抓取27个骨骼点、做3D渲染和人体重构——也就是生成所谓的数字人,在数字播放器中进行动画渲染,帧率可以达到70fps,“实时性堪称完美”。
虽说这类应用在构建“元宇宙”的问题上,丰富与多样性和N卡还是有差距;但就Arc显卡发布一年不到的生态建设水平来看,已经称得上神速了——而且是顶着图形渲染和HPC AI加速生态同时共进的巨大压力。
后续我们会对Intel的AI生态建设做更详细的报道,现在这应该也是Intel的一个重大课题了。另外基于我们手头的酷睿处理器和Arc GPU,我们也会尝试搭建生成式AI环境,来实际上手跑一跑本地的生成式AI——各位同学可以在电子工程专辑的微信视频号上期待一下。

文章来自:https://www.eet-china.com/







