











数据标准化是一种重要的技术,通常来说,在使用许多机器学习模型之前,我们都要使用它来对数据进行预处理,它能对输入数据集里面的各个特征的范围进行标准化。

一、什么是数据标准化
数据标准化是一种重要的技术,通常来说,在使用许多机器学习模型之前,我们都要使用它来对数据进行预处理,它能对输入数据集里面的各个特征的范围进行标准化。
一些机器学习工程师通常在使用所有机器学习模型之前,倾向于盲目地对他们的数据进行标准化,然而,其实他们并不清楚数据标准化的理由,更不知道什么情况下使用这一技术是必要的,什么时候不是。因此,这篇文章的目标是解释如何,为什么以及何时标准化数据。
当输入数据集的特征在它们的范围之间具有大差异时,或者它们各自使用的单位不同时(比如说一些用米,一些用厘米),我们会想到对数据进行标准化。
这些初始特征范围的差异,会给许多机器学习模型带来不必要的麻烦。例如,对于基于距离计算的模型来说,当其中一个特征值变化范围较大时,那么预测结果很大程度上就会受到它的影响。
我们这里举一个例子。现在我们有一个二维的数据集,它有两个特征,以米为单位的高度(范围是 1 到 2 米)和以磅为单位的重量(范围是 10 到 200 磅)。无论你在这个数据集上使用什么基于距离的模型,重量特征对结果的影响都会大大的高于高度特征,因为它的数据变化范围相对更大。因此,为了预防这种问题的发生,我们会在这里用到数据标准化来约束重量特征的数据变化范围。
二、如何进行数据标准化?
Z-score 是较受欢迎的数据标准化方法之一,在这种方法中,我们对每一项数据减去它的平均值并除以它的标准差。一旦完成了数据标准化,所有特征对应的数据平均值变为 0,方差变为 1,因此,所有特征的数据变化范围现在是一致的。(其实还有许多数据标准化的方法,但为了降低难度,我们在这篇文章中只使用这种方法。)
三、什么时候需要进行数据的标准化?为什么?
如上所示,在基于距离的模型中,数据标准化用于预防范围较大的特征对预测结果进行较大的影响。不过使用标准化的原因不仅仅只有这一个,对于不同的模型会有不同的原因。
那么,在使用什么机器学习方法和模型之前,我们需要进行数据标准化呢?原因又是什么?
1- 主成分分析:
在主成分分析中,方差较大或者范围较大的特征,相较于小方差小范围的数据获得更高的权重,这样会导致它们不合常理的主导名列前茅主成分(方差最大的成分)的变化。为什么说这是不合常理的呢?因为导致这一特征比其他特征权重更大的理由,仅仅是因为它们是以不同的尺度测量的。
通过给予所有特征相同的权重,数据标准化可以预防这一点。
2- 聚类:
聚类模型是基于距离的算法。为了测量观测对象之间的相似性,并将它们聚集在一起,模型需要使用距离度量 距离度量(Distance Metrics)。在这种算法中,范围较大的特征会对聚类结果产生更大的影响。因此,在进行聚类之前我们需要进行数据标准化。
3- KNN:
k-最近邻(分类算法)是一个基于距离的分类器,其基于对训练集中已标记的观察结果的相似性度量(例如:距离度量)来对于新数据进行分类。标准化使所有变量对相似性度量的贡献相等。
4- SVM:
支持向量机尝试最大化决策平面与支持向量之间的距离。如果一个特征的值很大,那么相较于其他特征它会对计算结果造成更大的影响。因此,标准化使所有特征对距离度量具有相同的影响。

5- 在回归模型中测量自变量的重要性
你可以在回归分析中测量变量的重要程度。首先使用标准化过后的独立变量来训练模型,然后计算它们对应的标准化系数的绝对值差就能得出结论。然而,如果独立变量是未经标准化的,那比较它们的系数将毫无意义。
6- Lasso 回归和岭回归
Lasso 回归和岭回归对各变量对应的系数进行惩罚。变量的范围将会影响到他们对应系数受到什么程度的惩罚。因为方差大的变量对应的系数很小,因此它们会受到较小的惩罚。因此,在使用上面的两个回归之前需要进行标准化。
四、什么时候不需要标准化?
逻辑回归和树形模型
逻辑回归,树形模型(决策树,随机森林)和梯度提升树对于变量的大小并不敏感。所以数据标准化在这里并不必要。
延伸阅读:
在回归问题和一些机器学习算法中,以及训练神经网络的过程中,通常需要对原始数据进行中心化(Zero-centered或者Mean-subtraction)处理和标准化(Standardization或Normalization)处理。
- 目的:通过中心化和标准化处理,得到均值为0,标准差为1的服从标准正态分布的数据。
- 计算过程由下式表示:x′=x−μσx^{‘}=\frac{x-\mu }{\sigma }
- 下面解释一下为什么需要使用这些数据预处理步骤。
在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表征的。比如在预测房价的问题中,影响房价yy的因素有房子面积x1x_{1}、卧室数量x2x_{2}等,我们得到的样本数据就是(x1,x2)(x_{1},x_{2})这样一些样本点,这里的x1x_{1}、x2x_{2}又被称为特征。很显然,这些特征的量纲和数值得量级都是不一样的,在预测房价时,如果直接使用原始的数据值,那么他们对房价的影响程度将是不一样的,而通过标准化处理,可以使得不同的特征具有相同的尺度(Scale)。这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了。
- 简言之,当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理。
- 下图中以二维数据为例:左图表示的是原始数据;中间的是中心化后的数据,数据被移动大原点周围;右图将中心化后的数据除以标准差,得到为标准化的数据,可以看出每个维度上的尺度是一致的(红色线段的长度表示尺度)。
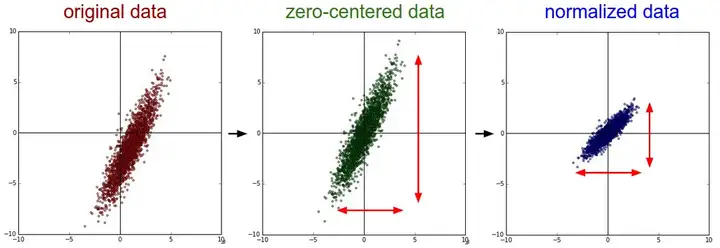
其实,在不同的问题中,中心化和标准化有着不同的意义,
- 比如在训练神经网络的过程中,通过将数据标准化,能够加速权重参数的收敛。
- 另外,对于主成分分析(PCA)问题,也需要对数据进行中心化和标准化等预处理步骤。








