











好像大家真正关注AI,是在“爆发”的ChatGPT、Stable Diffusion这些生成式AI出现之时。但实际上,手机、PC之上的端侧AI推理也发展好些年了,拍照、视频会议之类的场景早就开始应用AI了,只不过大概着力点都不在痛点创新上,感知就没有那么强烈。
最近讨论端侧设备跑生成式AI的话题也挺火的——当然核心还是在于网络模型推理:比如现在数码圈测个图形卡,普遍也是要跑一跑Stable Diffusion的。前不久Intel Arc媒体交流会上,Intel自己也用Arc独显去跑了Stable Diffusion。
最近Intel特别就“AI在PC的规模化发展技术趋势”话题搞了个媒体会,Intel又给我们展示了用PC端的CPU+核显GPU+VPU,在GIMP里面借助OpenVINO插件来跑Stable Diffusion。
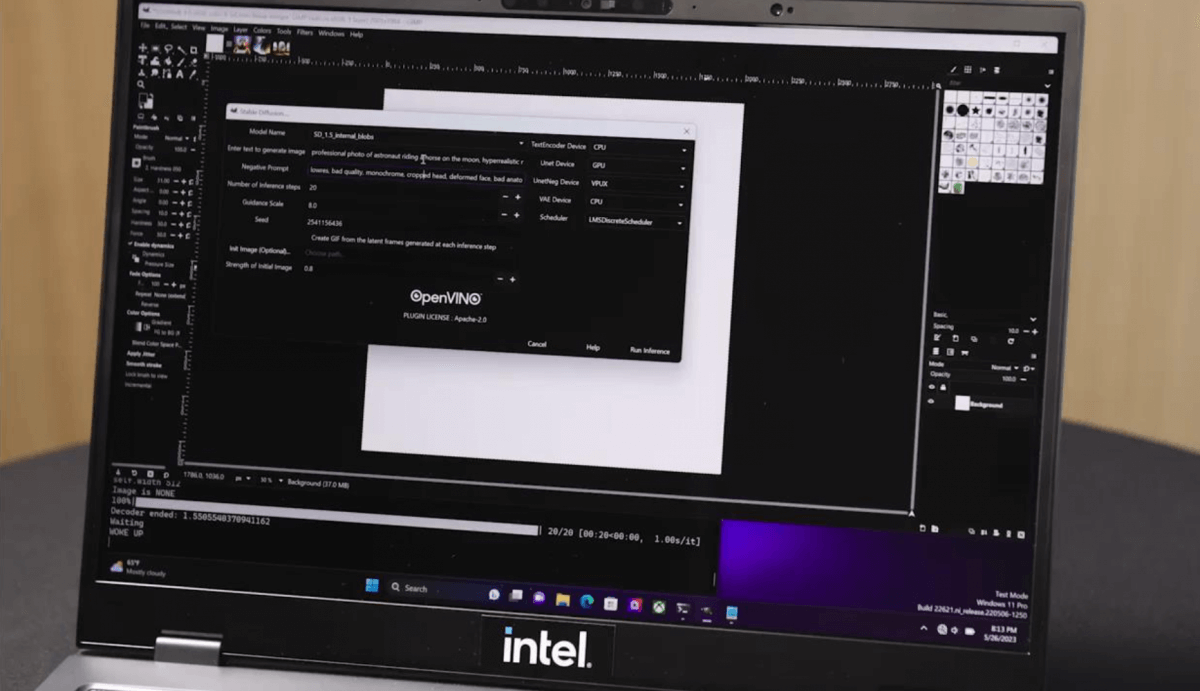
这个场景的独特之处,一方面在于基于异构计算来跑生成式AI,另一方面展示的是个低功耗平台,没有独显和大型AI芯片参与,竟然也能跑——Intel展示这个场景是为了说明,未来的轻薄笔记本有AI方面的潜力。
预计今年下半年或明年要到来Intel的Meteor Lake处理器(理论上应该是14代酷睿,虽然Intel还未将其正式定义为14代酷睿)上,我们就能上手这个AI推理场景。趁此机会,我们也能窥见未来1-2年内,对于PC来说,AI会产生哪些显著的影响。
虽然我们感觉用Meteor Lake这样一颗PC上的处理器来跑生成式AI,实在也是目前的“情势所迫”。但的确借助现有软硬件,能在20秒推理一次text-to-image过程,总算是可用的。Intel表示,这个演示是为了表明,降低了普通用户使用生成式AI的门槛,用“轻薄笔记本也能跑Stable Diffusion这种大模型实现文生图”。
有关Meteor Lake这颗尚未正式上市的处理器,我们在过去一年的文章里已经做了大量解析,从chiplet式的大框架,到2.5D/3D封装,再到Intel 4工艺——毕竟Meteor Lake全身上下都是半导体技术热点。而且Intel自己也是时不常地就让Meteor Lake露个脸,流片、die shot都自曝了一遍。

有兴趣的同学可以去看看我们之前的详细解读,这里不再做扩展。不过有一点值得一提,即Meteor Lake整颗芯片上,除了CPU、GPU之外,还有个VPU单元。关注Intel的同学对于VPU应该不会陌生,VPU本身是个视觉AI加速器,来自于Intel早些年收购的Movidius。
在13代酷睿(Raptor Lake)平台,Movidius VPU是作为独立芯片,可应用于13代酷睿笔记本上的。而到了Meteor Lake上,VPU就成为了整颗芯片的一部分,虽然我们目前暂时不知道它会放在哪颗die上。
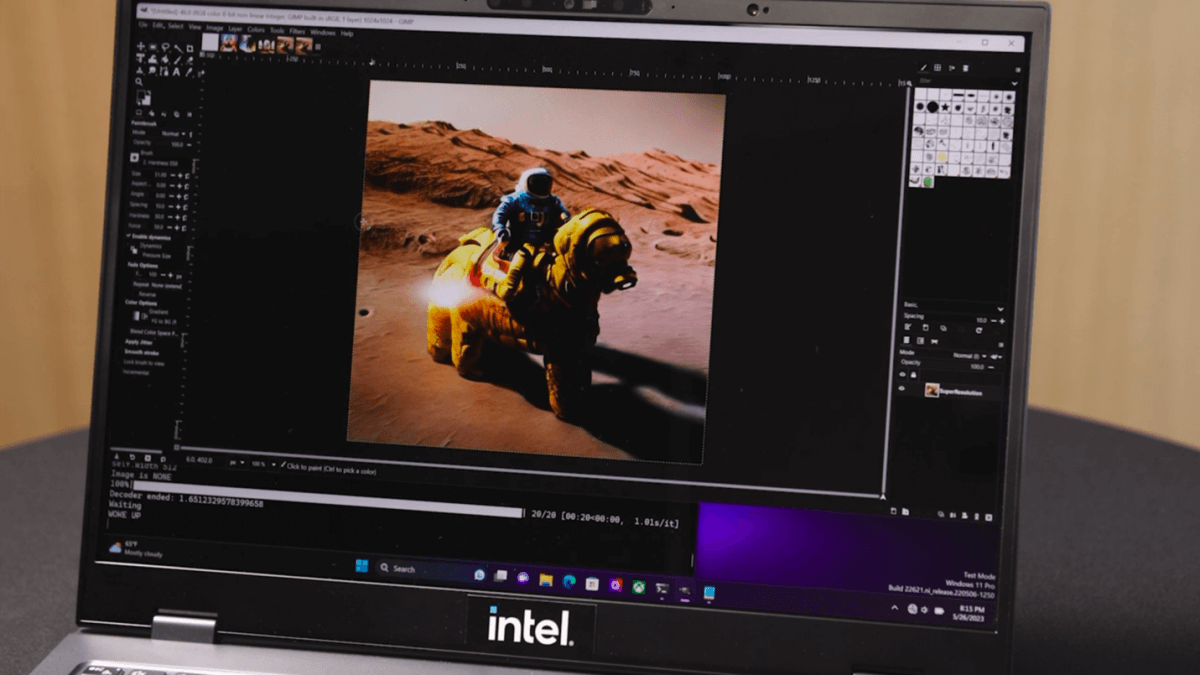
如上所述,这次Intel演示用Meteor Lake来推理Diffusion模型,是同时用到了CPU、核显和VPU的。输入的提示语是“月亮上,宇航员骑着一只马”…输出大约需要20秒。其实这个时间的参考价值可能并不大,毕竟Intel没有提供横向对比对象。
Intel解释说这个过程是“将不同的层放在不同的IP上,比如VPU承载VNET模块的运行,GPU承载encoder模块的运行”;“所以整体上来讲,是把整个模型分散到不同的IP上。不同IP模块配合,充分利用系统资源。”除此之外,demo还跑了宇航员骑马图像的AI超分——完全基于VPU,这就相对常规了。
整个调度过程是由Intel的OpenVINO完成的。OpenVINO这个工具本身能够实现写一次代码,就在包括CPU、GPU、VPU和FPGA在内的不同Intel平台上,做深度学习部署。OpenVINO中的Model Optimizer先将训练模型转为OpenVINO的IR格式,在受支持的设备上先做优化;然后Inference Engine推理引擎在不同的插件上做推理。不过据说演示的这一例尚未实现完全动态化。
在端侧做本地AI推理,包括隐私、实时性等在内的好处就不多说了——实际就业务运转逻辑来看,端侧AI芯片市场机遇,都是行业参与者不愿错过的。所以未来也不大可能所有AI计算都在云端,或者边缘数据中心进行。
Intel说PC有很多应用场景需要AI算力。而且AI算力需求实则这些年是一直在提升的。从过去视频会议的背景模糊、美颜、人声降噪,到未来借助自然语言与PC沟通来协助办公——虽然我们认为,后者的AI呈现形态在未来仍然很难在本地跑起来。
其实即便是如今司空见惯的视频会议语义分割、声音降噪等,算法和算力需求也在发展。比如下图呈现的,据说现在的噪声抑制和背景分隔,相比于2年前的复杂度分别提升了50倍和10倍;大热的生成式AI就更不必多说了。

PC处理器还是Intel的天下。Intel想要抓住PC端的AI机会也是很早之前就开始的了。虽然普罗大众在谈AI时,都更喜欢将其与GPU或者VPU之类的专用AI芯片/单元挂钩,但AI计算-尤其在端侧,并不只是AI芯片的事情。早在11代酷睿处理器的AVX-512新增支持上,Intel就在宣传针对AI和机器学习加速的Deep Learning Boost,支持VNNI指令(Vector Neural Network Instructions)。
另外,可能很多同学未曾留意,Intel酷睿SoC上早前就有GNA(Gaussian Mixture Model and Neural Network Accelerator),这是个低功耗协处理器,主要用于语音识别与音频应用方向的部分辅助特性。Intel似乎是从Ice Lake(10代酷睿)开始宣传GNA的。虽然透露的信息甚少,但这也算是个AI硬件。(从此前外媒公开的Meteor Lake框图来看,GNA可能仍然存在,或者已经成为VPU的组成部分)
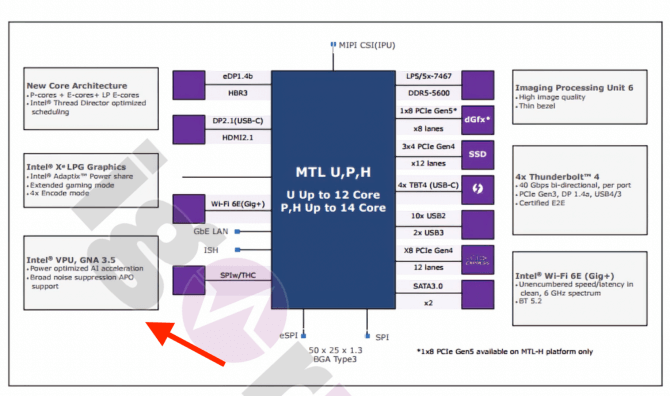
Credit: Igorslab.de
后续的Modivius VPU,以及现如今Intel Arc独显的AI支持自不必多说。其实我们对VPU所知也不多,如其具体算力、功耗、效率、内部结构。不过从Intel的介绍来看,至少在Meteor Lake上这应该是个占die面积不大的单元,所以主打“低功耗”。当然,从PC之外,就Intel AI产品布局大板图来看,Intel在AI方面相关的硬件部署更多样化,不止是AI芯片和FPGA这类传统硬件,还包括相当未来向的神经拟态Loihi,此前我们都撰文谈到过。
总的来说,在Intel看来,单一架构并不适用所有AI场景。单PC上的AI场景就有不同类别,有轻负载、重负载、延迟敏感的。比如人对语音、视频的延迟很敏感,这其中的很多场景负载不重,但延迟表现很重要。
而“CPU处理AI负载时,延迟低”,就适用于延迟敏感型AI负载;“GPU适合较重负载,比如AI大模型对算力要求很高,但对延迟没有那么敏感”;而像VPU这样的硬件,是“专为AI设计的一套架构,能够很高效地做一些矩阵运算,且擅长稀疏化处理“,另一个特点是基于DSA,功耗低,则对“流媒体AI处理,视频会议背景虚化等需要长时间运行的AI负载”很适用。
即便是端侧AI推理,光有芯片和硬件当然还是不够的。AI相关的芯片要落地到最终应用,就需要发展生态与合作。比如此前Intel在宣传13代酷睿期间,对VPU的着墨不多,但当时就已经面向开发者做发放了。前不久的微软Build开发者大会上,Intel才宣布了和微软之间在PC端就Meteor Lake芯片AI方面的合作。
当时微软提到,开发者可以用ONNX Runtime和相关工具链,在Windows平台上跑AI模型;合作涵盖了通过OpenVINO-EP和DirectML-EP达成的ONNX-RT支持,以及VPU、GPU的WinML/DirectML加速,还有落实到Microsoft Studio Effects的背景虚化、眼部对焦、声音聚焦等AI特性。
Intel在这次的媒体会上提到开发中间件、工具相关的部分,一是OpenVINO——前文已经提到,“将底层不同架构的异构计算差异封装好,提供同一软件接口,开发者不需要关心硬件层面的差别”;此外自然也有“对业界标准的支持”,比如ONNX格式;“也和W3C合作,将AI能力引入到浏览器中”;还有微软的DirectML机器学习API等等。
而在更下游的应用和软件方面,“我们也有专门的部门,与业界的不少软件开发商合作,让他们充分应用Intel底层架构、AI指令集和软件工具”,“今天有超过70%的ISV都在用AI改造自己的业务,我们和超过100家ISV在做AI方面的合作”。Intel表示。

具体到VPU的加速支持上,Intel谈到和Adobe的合作。Adobe应用因此可以利用VPU,来做智能抠图、应用滤镜(neural filter)、自动化处理、分类等。“另外,我们也和Blender、Audacity、OBS、GIMP合作”。
而且“和Unreal Engine一起做了数字人——捕捉人的面部表情,映射到一个3D模型中去”,可在虚拟主播之类的场景里应用。据说这一特性已经在引擎工具上以插件的形式做了集成。

在我们看来,PC端目前最有价值的AI应用应该还是在游戏、媒体与3D内容创作方向——不过这类重型负载的AI算力普遍应该会来自独显。但很显然,重载AI应用,即便是端侧AI推理,英伟达依然有着自上而下的主场优势。但Intel也正依托于自家的GPU产品在努力。
而前面谈的这些,主要还是PC作为办公工具时,AI于日常生活发挥的作用——它更像是在潜移默化的过程里影响人们的数字生活。PC CPU的主场优势毕竟还是在Intel这边的——且Intel有机会借着chiplet和异构集成的大趋势,来发展基于自家芯片的AI。
或许上层应用开发者未来还会有新的点子出现,将端侧AI算力更进一步加入到PC的日常使用中:Intel当前的端侧AI硬件与生态建设就是为此准备的。
文章来自:https://www.eet-china.com/







