











随着「第九版」、「二十条」以及最近发布的「新十条」,我们的防疫措施转向开放和共存,全国各地的企业陆续复工复产。这让我们仿佛看到了经济的快速复苏和生产力的立即回升。
但是,北方的几个城市相继出现了大量人员感染的情况。特别是最近,北京的感染人数肉眼可见地快速增加。大家仿佛一夜之间从「因为封控无法上班」变成了「因为发烧无法上班」。突如其来的情况令众多团队措手不及:人员因病无法到岗,或者因为需要照料家人无法全身心投入工作,导致项目进度濒临失控。
同样的,作为以北京和西安为研发中心的 PingCode 团队也面临着这样的问题。接下来,本文试图和大家分享一下我们是如何通过敏捷开发,结合 PingCode 产品本身来尽力解决问题的,希望能够为您提供一些灵感和思路。
一、更加细致地进行迭代容量估算
在 Scrum 流程中,迭代计划会议的名列前茅个阶段就是要确定团队的容量,就是确定当前迭代能够完成的故事点总和。一般来讲,这个数字是参考之前已完成的迭代,然后再进行讨论,并最终达成共识。在人员相对稳定的情况下,上述方式不会有什么大问题。但是,因为处在名列前茅波疫情冲击之下,对于容量估算则要格外谨慎和小心。为此,我们引入了一个简单的公式进行计算。首先我们会统计之前(冲击前)几个迭代的平均容量。然后再统计当前迭代人员的投入情况(百分比)。主要包括:
- 因为生病,或者需要照料家人等造成的病假或事假。
- 因为恢复期无法以之前100%的能力投入。
- 家人或共居者有阳性,结合目前5-7天的潜伏期,预计可能出现的病假。
这里需要注意的是,我们明确的表示,投入情况并不代表某位成员是否「称职」,也与绩效、工作态度等无关,仅仅是为了团队能够尽量合理的预测,保证最终产出物的质量。因为只有这样,才能让大家提供最真实客观的反馈。最后我们将每位成员的投入情况带入公式计算,得到一个估算的容量值。再讨论确定最终的容量。譬如之前团队共有5人,平均容量为 50 。本次迭代开始时,两位同事因病在家休息一周,第二周恢复期只能有50%的工作效率。另一位成员需要照看家人,只有15%的时间能够参与工作。那么最终的容量值大致是 50 / 5 * (1 + 1 + 0.15 + 0.25 + 0.25) = 26.5 。
二、确保每个人对需求的理解一致
由于人员的不确定性增加,在迭代会议时,大家在讨论需求的时候需要更加仔细。在可接受的范围内,我们建议团队尽可能地对用户故事的每一个细节和场景进行充分的讨论,确保所有人对需求的理解是一致的。同时,对于讨论过程中发掘出的内容进行详细记录。
对需求理解保持高度一致,能够确保在开发过程中,无论是谁作为用户故事负责人,无论用户故事内子任务分派给谁,都能在最终验收时与预期的功能保持一致。避免由于某位成员临时请假的情况下,因为其他成员对需求理解偏差导致最终的结果不达预期。
三、尽量不要指定用户故事负责人
虽然最「正统」的 Scrum 规范要求不能指定用户故事的负责人,但是我们在实际工作中,还是允许 Team Leader / Product Owner 在某些情况下可以提前指定用户故事的负责人。这主要是为了确保一些关键或复杂的功能由资深的员工完成,或者让某些成员能够有机会去负责一些自己想做的业务。
但是在当前情形下,我们认为提前指定负责人会带来更大的不确定性风险。因此,会倾向于更加的谨慎。也就是说,除非出现非常必要的情况,我们是不允许团队在计划会议中直接指定某些用户故事的负责人。因为指定负责人或多或少的会降低参与感与熟悉程度。而一旦出现负责人请假的情况,其他成员则很难短时间内进行补充和替代。
对于必须要指定的极特殊情况,我们也要求同时指定一名后备人员(即双负责人制)。他与负责人对用户故事的理解,以及对技术实现的了解程度基本一致,能够确保人员出现问题的时候可以快速补充。
四、每日站会时重点关注被阻塞的工作
我们要求各团队的 Scrum Master,在近期的每日站会中重点关注那些被阻塞的工作,在必要的时候逐个询问团队成员开发进度是否有偏差。
工作被阻塞,一方面可能是因为技术问题,另一方面,在当前还可能是其他成员或其他团队无法按时交付功能点。这在 PingCode 这种多团队、分布式项目中显得尤为突出。而功能点的延迟交付,很有可能是成员投入不足导致的。
有的时候,成员的投入比例很难在计划会议中明确预测。可能在迭代过程中,有的员工本人身体不适,或者家庭原因等等,导致不同程度的投入度不足。而我们不同于欧美企业,在遇到个人问题和困难时多半会自己解决,而并不会向团队同步。也就是经常说的「轻伤不下火线」。虽然这种做法可以理解,但是在客观上往往会导致工作进度和完成质量出现了不同程度的下降。而且往往很难被立即发现。
对于一个 Scrum 团队,我们希望看到真实的状况,遇到问题和困难大家一起解决。同时 PingCode 团队也不鼓励所谓的「带病工作」。因此,关注阻塞情况能够帮助我们更快发现潜在的问题,立即进行调整。这小调整包括更换负责人、调整迭代目标和优先级等。确保迭代结束时,交付的内容都是完整的且有质量保证的。
五、在群组、需求详情和评论以及协作空间讨论模块中进行沟通
开发过程中,团队成员、产品经理、设计师以及运维同事,甚至营销线同事之间都会有频繁的沟通。其中涉及需求、技术、实现等等诸多方面。此前我们推荐大家在可能的情况下面对面沟通。因为这样效率较高,而且能够确保大家都明确各自的诉求和最终的结论。
但是在人员波动较大的当下,我们转而推荐大家更多的使用能够留存数据的在线沟通方式。而且避免使用一对一的私聊。这主要是因为,一对一的沟通虽然效率高,但是沟通的结果仅限于两个人。一旦后期有人请假,对于接手的其他成员就会出现信息的缺失。即使通过再次沟通能够弥补这样的缺失,耗费的时间成本也是一个不能忽略的问题。
因此我们要求团队成员通过以下三种方式进行沟通:
一是利用Worktile 群组进行沟通:我们为每一个 Scrum 小组创建的对应的 Worktile 聊天群组,对于迭代内的沟通都要求通过群组进行交流。这样一方面保证了信息能够留存的检索,另一方面,如果有需要负责人替换的情况,也可以通过群组信息快速或者需求详情。
二是要求对所有结论性的东西都落实在对应工作项的描述和评论中。这样,任何人打开此工作项,都能够得到完成的需求详情、技术细节和讨论结果。

三是使用协作空间讨论偏底层技术,或者需要长期沟通的内容:作为PingCode协作空间中即将推出的一项新功能,目前已经在我们团队内部试用了一个月左右。对于那些偏底层技术,或者需要长期沟通的内容,我们要求通过讨论功能进行。一方面大家可以针对一个问题进行回复,同时也可以针对别人的回复进行评论。通过这种方式能够让讨论更加深入和有针对性,更容易沉淀出最终的结果。同时,讨论的结果连同过程,都能够被快速的查阅和检索。
六、使用自动化代替人工
需要注意的一点,我们采用上述的任何措施,只能是在人员出现波动的时候,通过灵活运用敏捷开发流程,尽量的规避风险,将影响降低到可控的范围内部。那么还有什么办法,进一步解决成员构成不稳定的问题呢?让更多的工作从人工操作变为机器自动操作,这不失为一种解决方案,而且是一个根本上的解决方案。
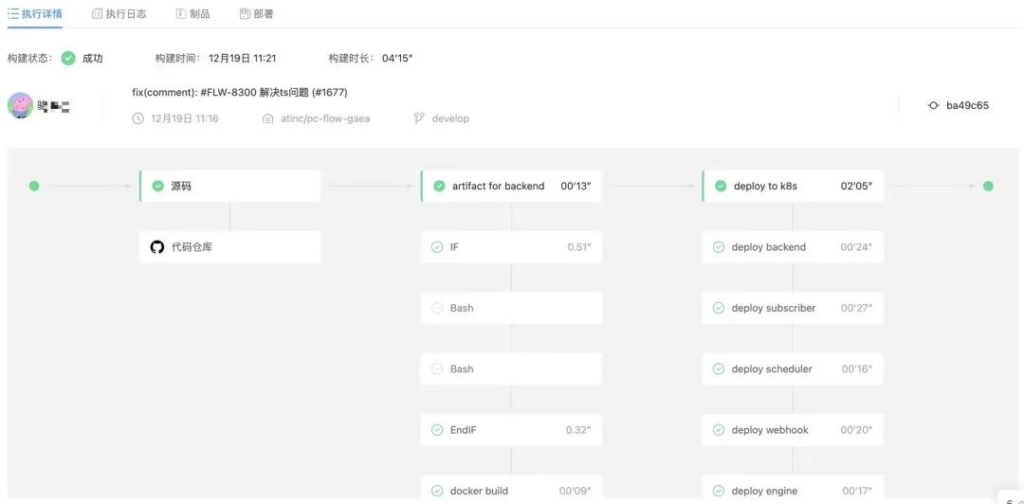
譬如在 PingCode,我们针对 Alpha、Beta 这两个日常开发用到的环境,都做到了基于代码仓储的全自动部署的能力,完全不需要人工的干预。通过在AWS上构建的 Jenkins、Kubernetes、Helm 和 Harbor,开发人员合并代码后会自动执行代码扫描、编译、测试、打包和部署工作。3-5分钟左右,就能够在 Alpha 环境看到最新的功能,完全无需研发和运维人员手工操作。
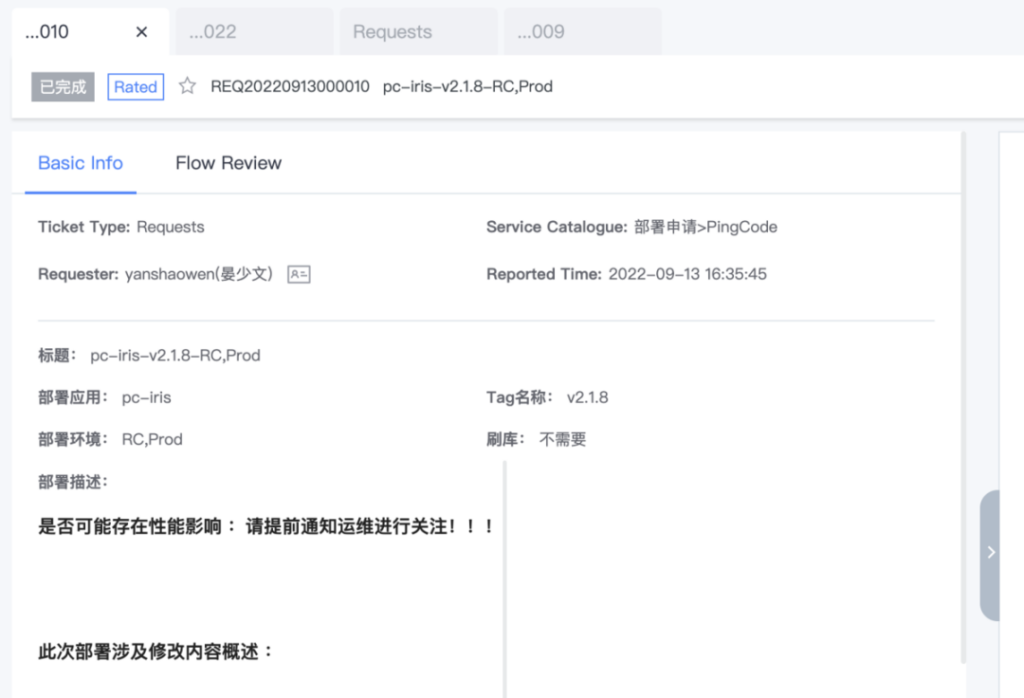
类似的,对于涉及线上的 RC 和 Production 环境,我们设计了完整的部署工单系统。研发人员只要按需提交申请,指定部署环境和待执行的脚本等,待运维同事确认就可以在指定时间自动执行,完成部署和上线。
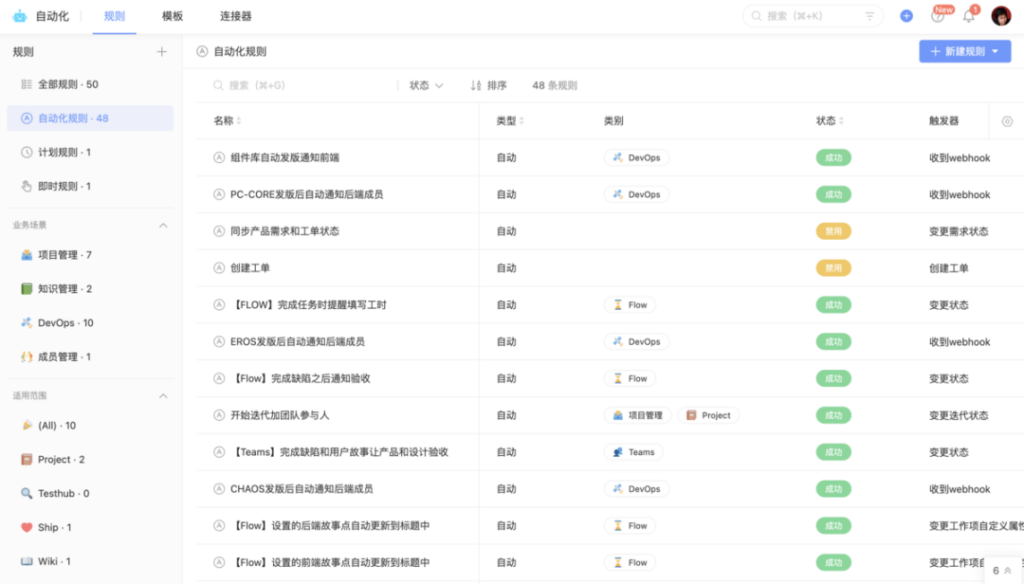
除了流水线以外,我们还充分利用 PingCode 的自动化能力,解决了很多之前需要大家手动执行的操作。一方面节约了开发的时间,另一方面,也在人员不在岗的时候尽量保持流程的稳定性和消息的及时性。
总结
研发团队人员的波动是一件很平常的事情,之前也会时有发生。但是由于名列前茅波疫情的冲击,使得这一现象体现的尤为突出。敏捷开发的原则是拥抱变化,而变化不仅是我们之前关注的需求变化,其实也包含了成员的变化。因此我们认为,通过贯彻和优化敏捷开发流程,能够很好的解决当下的问题。
上述的一些规则,在我们的团队已经实施了2周左右。从目前来看取得了较好的效果。虽然各团队的迭代产出或多或少的还是会收到一些影响,但是产品质量没有出现大的问题。团队内和团队间的配合也相对稳定。因此,我们希望通过这篇文章分享一下经验,能够帮助大家一起尽力平稳渡过这段特殊时刻。
希望以上 PingCode 经验能够带给大家一定启发。







